

Anchor-free检测器基本上将目标检测表述为密集分类和回归。对于流行的Anchor-free检测器,通常会引入一个单独的预测分支来估计定位的质量。当深入研究分类和质量估计的实践时,会观察到以下不一致之处。
- 首先,对于一些分配了完全不同标签的相邻样本,训练后的模型会产生相似的分类分数。这违反了训练目标并导致性能下降;
- 其次,发现具有较高置信度的检测框与相应的Ground-truth具有较小的重叠。
在非最大抑制 (NMS) 过程中,精确定位的边界框将被不太准确的边界框抑制。为了解决不一致问题,提出了动态平滑标签分配(DSLA)方法。基于FCOS最初提出的中心性概念,提出了一种平滑分配策略。标签被平滑到 [0, 1] 中的连续值,以在正样本和负样本之间进行稳定的过渡。 Intersection-of-Union (IoU) 在训练期间动态预测,并与平滑标签相结合。分配动态平滑标签以监督分类分支。在这样的监督下,质量估计分支自然地合并到分类分支中,这简化了Anchor-free检测器的架构。在 MS COCO 基准上进行了综合实验。结果表明,DSLA 可以通过减轻上述Anchor-free检测器的不一致性来显著提高检测精度。
1、简介
卷积神经网络 (CNN) 已广泛应用于计算机视觉任务,包括类别分类、目标检测、语义分割以及实体连接推理和跨模态理解等其他相关任务。具体来说,目标检测是计算机视觉中的一个基本问题,旨在预测图像中边界框和相应类别标签的位置。
自 RCNN 以来,基于深度学习的目标检测随着其在工业检测、视频分析、文本识别、航拍图像等领域的广泛应用而备受关注。现有的基于深度学习的检测器大致可以分为Anchor-free和Anchor-base的类别。正如 Faster R-CNN 所推广的那样,SSD、RetinaNet 和 YOLO v2、v3 等主流检测器通常依赖一组预定义的Anchor框来枚举目标的可能位置、尺度和纵横比。尽管它们的性能很好,但检测器仅限于Anchor的设计。
最近,Anchor-free检测器逐渐引领了目标检测的趋势,它直接学习目标可能性和边界框坐标,无需Anchor参考。与基Anchor-base检测器相比,Anchor-free检测器摆脱了与Anchor相关的超参数和复杂计算,使训练过程相当简单。
YOLOv1 是一种流行的Anchor-free检测器。 YOLOv1 没有使用Anchor,而是直接在目标中心附近的点处预测边界框。 CornerNet 和 CenterNet 采用基于关键点的检测管道,检测边界框的一对角并将它们分组,形成最终检测到的绑定框。 FCOS、CenterNet 和 FoveaBox 以逐像素预测方式制定目标检测。
为了训练检测器,定义正样本和负样本是一个必要但重要的过程,它直接影响训练效率,从而影响性能。需要仔细考虑这个问题,尤其是对于Anchor-free检测器,而Anchor-base检测器根据联合交集(IoU)值将Anchor分为正样本和负样本。
以前的Anchor-free检测器通常采用单一的固定划分标准。也就是说,正样本和负样本根据手工规则和几个预定义的阈值进行划分。例如,YOLOv1 将输入图像划分为网格。如果一个物体的中心落入一个网格单元中,那么那个网格单元被认为是正的并且负责检测那个物体。
CornerNet 仅将 ground-truth (gt) 角位置视为正数,而所有其他位置均为负数。但是在正位置半径内的负位置的损失被降低了权重。 FCOS 和 Foveabox 将任何 gt 目标的中心区域或边界框内的位置视为正候选框。然而,这种静态策略不能适应物体的各种形状和姿态,以始终提供最佳的正/负划分。ATSS 提出动态分配策略根据 IoU 值的统计为每个 gt 设置划分边界。 OTA 试图通过解决最优传输问题来寻找全局最优划分策略。不幸的是,大多数方法都是基于Anchor的,不能直接应用于Anchor-free点检测器。同时,Anchor-free检测器中出现的不一致问题没有得到足够的重视,下面将以FCOS为例进行详细说明。
FCOS 对多级特征图上的每个位置进行预测。如果该位置的感受野 (RF) 的中心落入一个 gt 框,则计算从该中心到该框4个边的距离。如果最大距离在预定义的范围内,则将该位置设置为正样本,并且需要对框进行回归。图 1(b) 显示了样本划分的一个示例。输入图像被输入到经过训练的 FCOS 模型中以获得分类分数,其值由颜色表示。可以注意到,通常会为相邻位置分配完全不同的标签。
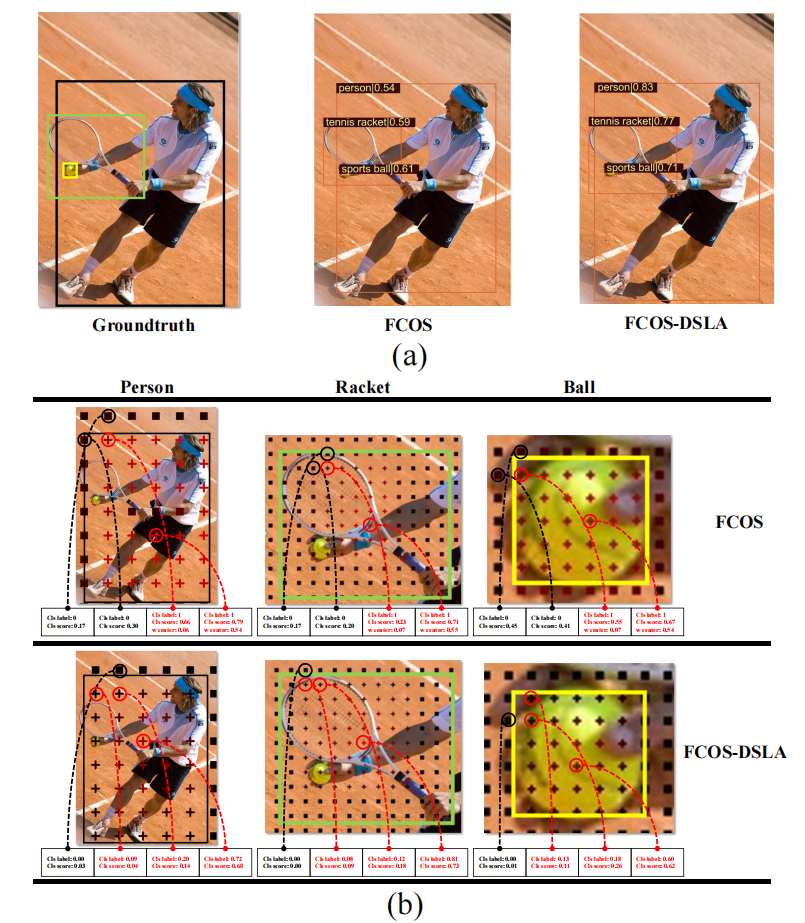
在图 1(b) 中考虑这些位置的分类分数。在预测“球拍”和“球”的特征图上,相邻位置具有相似的分数,但分配有不同的标签。显然,这与预期不符。作者将此问题称为分类不一致。还可以观察到,在预测“人”的特征图上,分数是不一致的。这是由于特征图的步幅不同。作者认为,分类不一致是由具有相似 RF 但分配了完全不同的监督的相邻样本引起的。这种不一致会阻止检测器学习更有效的对象表示,从而降低性能,如图 1(a) 所示。 centerness score的引入在一定程度上解决了分类分数相似带来的问题。然而,centerness score 仅用于 NMS 在推理时的排序过程中,在训练中仍然存在不一致的情况。

在 FCOS 中,中心度用于估计定位质量。该分数被预测并与分类置信度相结合作为NMS的最终排名分数。尽管有所改进,但中心度得分并不完全适用于定位质量的估计。在图 2 中,发现中心度得分较高的位置预测的边界框与 gt 的重叠较小。这主要是因为中心度得分较高的位置(黄色点)位于背景上,因此无法捕获足够的语义信息来预测准确的边界框。
对于具有不同外观的目标,固定的中心度分数不能总是提供对定位质量的可靠估计。作者称之为问题质量估计不一致。 centerness score的引入可能会导致意想不到的小ground-truth标签,这使得一组gt框很难被召回。研究人员建议,IoU 得分将优于 centerness 得分。但是,IoU 分数在整个训练过程中是不断变化的,在训练初期极低。这样的动态值会使训练过程剧烈振动。
为了提高Anchor-free检测器的性能,本文提出了动态平滑标签分配(DSLA)方法。在 DSLA 中,使用了最初在 FCOS 中开发的中心概念,但有两个改进,即核心区和区间松弛。为每个gt框定义核心区域以保持足够的置信度分数,从而解决由于置信度分数小而忽略真实目标的问题。引入间隔松弛以克服分配标签的剧烈变化。在此基础上,将标签平滑为[0, 1]中的连续值,从而实现正样本和负样本之间的平稳过渡。
IoU 分数在训练过程中动态计算,并与中心分数相结合,以提供对定位质量的合理估计。因此,推导出动态平滑标签来监督分类分支。图 1(b) 显示了配备 DSLA 的 FCOS 的划分结果。与 FCOS 相比,预测的分类分数与分配的目标更加一致。检测结果对比见图1(a)。可以看出,由于不一致性的解决,DSLA预测的边界框更加精确。真实目标的置信度得分明显增加。使用DSLA,分类分支不仅可以预测类别标签,还可以预测定位质量,可以直接用作NMS的排名分数。不再需要Anchor-free检测中常用的质量分支。因此,检测器的架构变得更加简洁,并且保持了训练和推理的一致性。
本文的贡献总结如下:
- 指出并分析分类和质量估计的不一致性。 提出了动态平滑标签分配来解决这些问题。
- 提出区间松弛策略并结合改进的中心度得分。 分配的标签被平滑到[0, 1]中的连续值,从而实现了正样本和负样本之间的稳定过渡。
- IoU 分数是动态计算的,并与平滑标签耦合以监督检测器的分类分支。 在DSLA的监督下,不一致性问题大大缓解。
- 所提出的方法适用于流行的Anchor-free检测器。 在MS COCO上进行了综合实验,证明了有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢