
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:PEER协同语言模型、基于辐射场的感知、ImageNet对生物多样性的歪曲、艾伯塔AI研究计划、基于深度学习和域外数据的自动音乐混音、从控制原理推导时间平均主动推理、用快速傅里叶卷积和改进的图像超分辨率训练重新审视SwinIR、3D可控人脸操纵研究、域特定视觉问答系统
1、[CL] PEER: A Collaborative Language Model
T Schick, J Dwivedi-Yu, Z Jiang, F Petroni, P Lewis, G Izacard, Q You, C Nalmpantis, E Grave, S Riedel
[Meta AI Research]
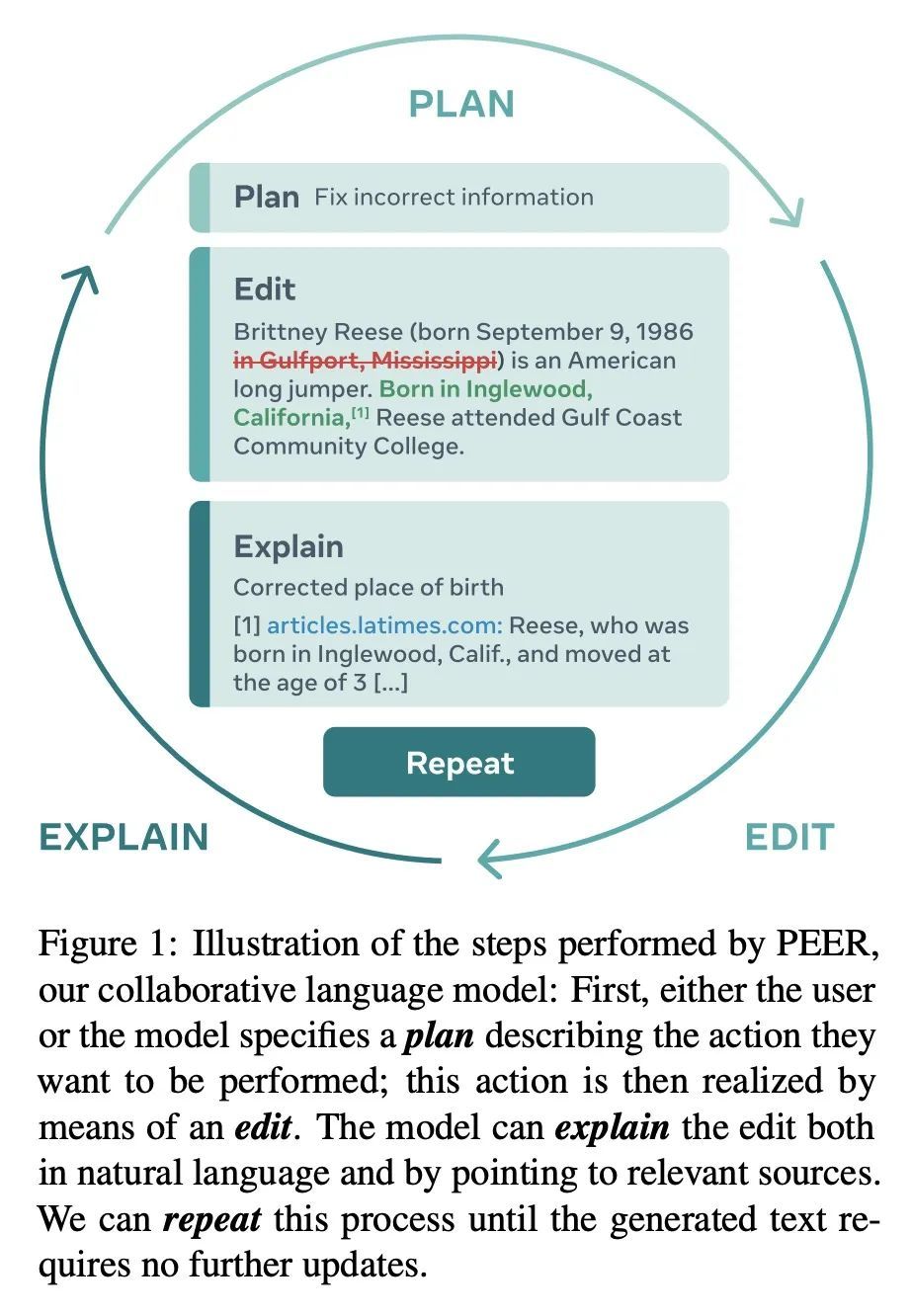
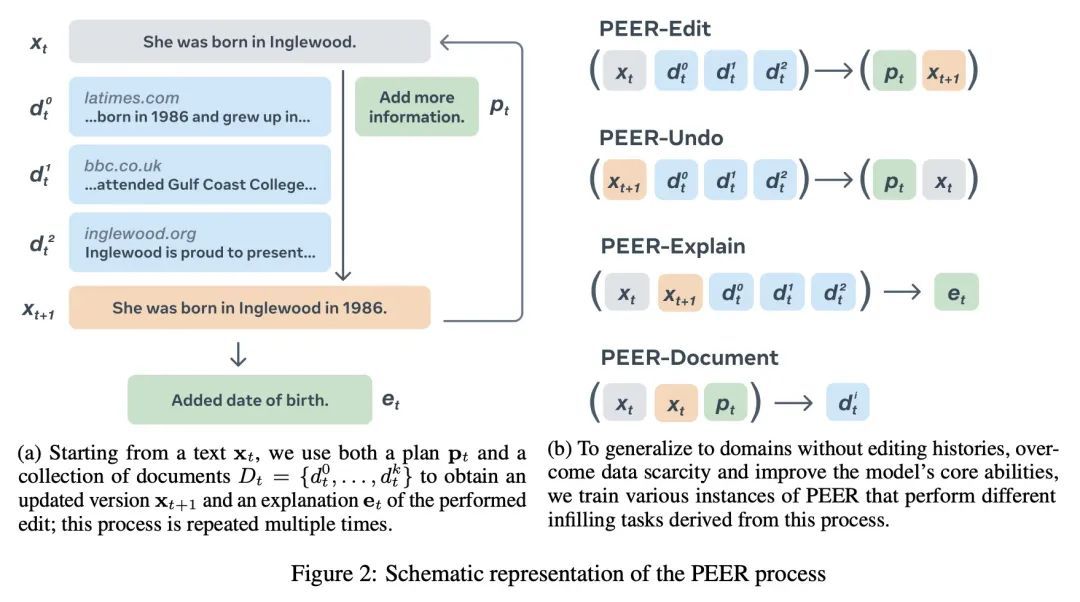
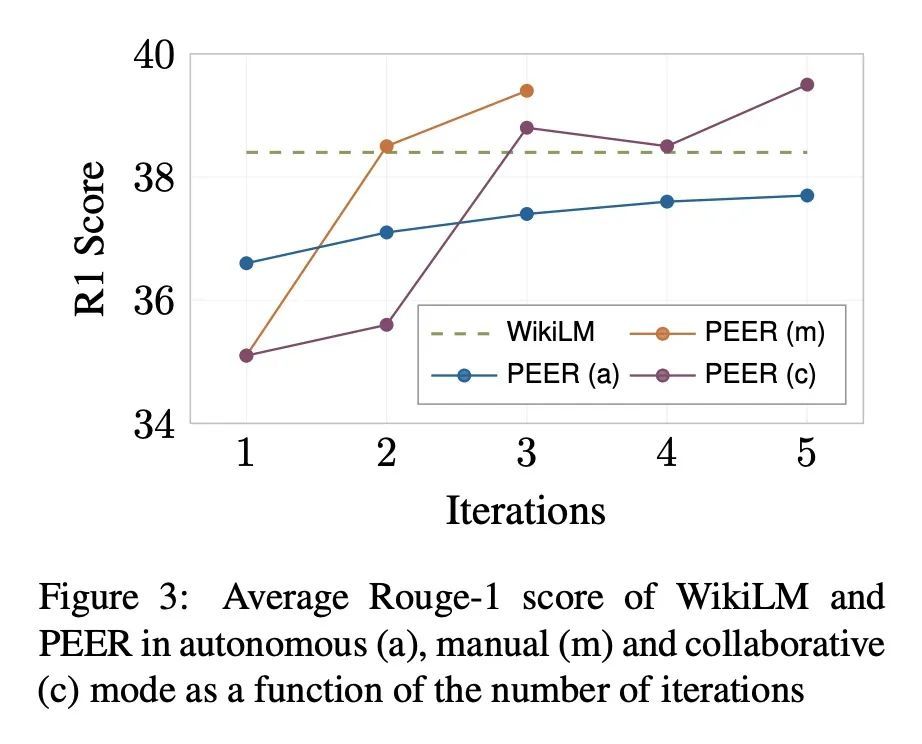
PEER: 协同语言模型。文本内容通常是协同写作过程的产物。从最初的草稿开始,征求建议,并反复进行修改。在这个过程中,如今的语言模型被训练成只生成最终的结果,缺乏对协同写作至关重要的几种能力:无法更新现有的文本,难以控制,也无法口头规划或解释其行为。为解决这些缺陷,本文提出PEER,一种经训练可以模仿整个写作过程本身的协同语言模型。PEER可以写草稿、添加建议、提出编辑意见并为其行为提供解释。最重要的是,训练PEER的多个实例,使其能填充写作过程的各个部分,从而能用自训练技术来提高训练数据的质量、数量和多样性。这释放了PEER的全部潜力,使其适用于没有编辑历史的领域,并提高其遵循指令的能力,写出有用的评论,并解释其行动。PEER在不同的领域和编辑任务中都取得了强大的性能。
Textual content is often the output of a collaborative writing process: We start with an initial draft, ask for suggestions, and repeatedly make changes. Agnostic of this process, today’s language models are trained to generate only the final result. As a consequence, they lack several abilities crucial for collaborative writing: They are unable to update existing texts, difficult to control and incapable of verbally planning or explaining their actions. To address these shortcomings, we introduce PEER, a collaborative language model that is trained to imitate the entire writing process itself: PEER can write drafts, add suggestions, propose edits and provide explanations for its actions. Crucially, we train multiple instances of PEER able to infill various parts of the writing process, enabling the use of selftraining techniques for increasing the quality, amount and diversity of training data. This unlocks PEER’s full potential by making it applicable in domains for which no edit histories are available and improving its ability to follow instructions, to write useful comments, and to explain its actions. We show that PEER achieves strong performance across various domains and editing tasks.
https://arxiv.org/abs/2208.11663

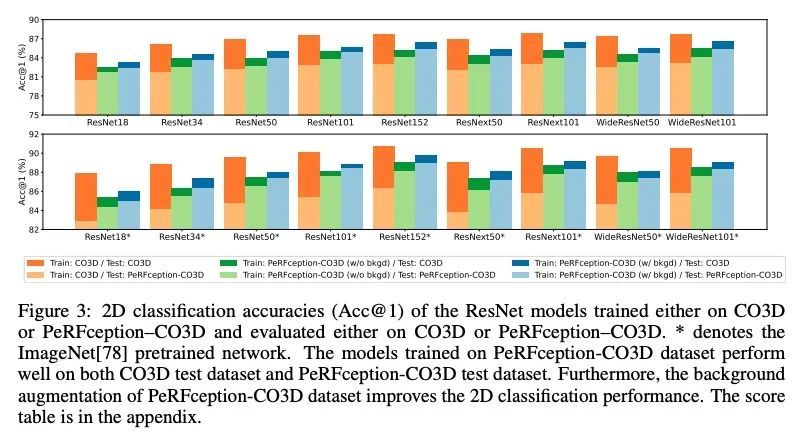
2、[CV] PeRFception: Perception using Radiance Fields
Y Jeong, S Shin, J Lee, C Choy, A Anandkumar, M Cho, J Park
[POSTECH & NVIDIA]
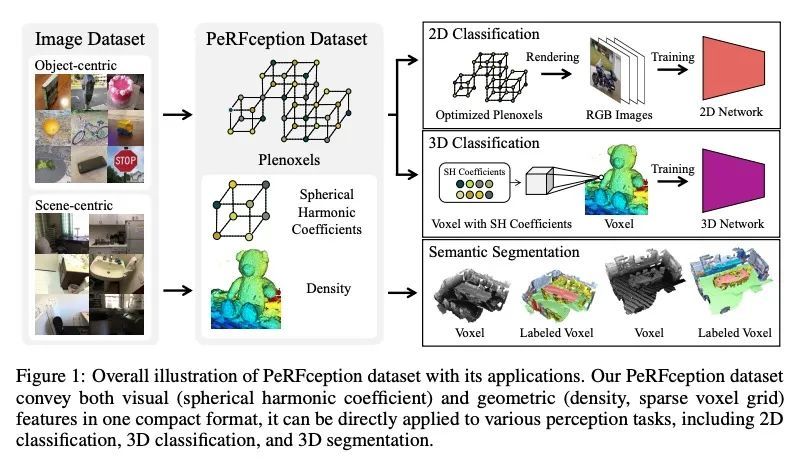
PeRFception: 基于辐射场的感知。最近在隐性3D表示方面的进展,即神经辐射场(NeRF),使准确和逼真的3D重建成为可能,而且是以一种可微的方式。这种新的表示方法可以在一个紧凑的格式中有效地传达数百个高分辨率图像的信息,可实现新视图的逼真合成。本文用NeRF的变种Plenoxels,创建了第一个用于感知任务的大规模隐式表示数据集,即PeRFception数据集,它由两部分组成,包括以物体为中心和以场景为中心的扫描,用于分类和分割。在原始数据集的基础上显示出显著的内存压缩率(96.4%),同时以统一的形式包含了2D和3D信息。本文构建了分类和分割模型,直接将这种隐性格式作为输入,还提出了一种新的增强技术,以避免对图像背景的过拟合。
The recent progress in implicit 3D representation, i.e., Neural Radiance Fields (NeRFs), has made accurate and photorealistic 3D reconstruction possible in a differentiable manner. This new representation can effectively convey the information of hundreds of high-resolution images in one compact format and allows photorealistic synthesis of novel views. In this work, using the variant of NeRF called Plenoxels, we create the first large-scale implicit representation datasets for perception tasks, called the PeRFception dataset, which consists of two parts that incorporate both object-centric and scene-centric scans for classification and segmentation. It shows a significant memory compression rate (96.4%) from the original dataset, while containing both 2D and 3D information in a unified form. We construct the classification and segmentation models that directly take as input this implicit format and also propose a novel augmentation technique to avoid overfitting on backgrounds of images. The code and data are publicly available in https://postech-cvlab.github.io/PeRFception/.
https://arxiv.org/abs/2208.11537


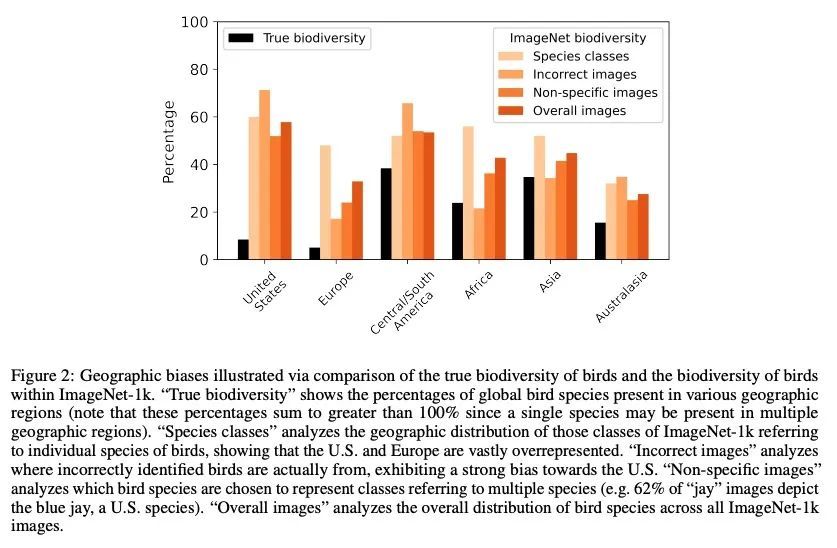
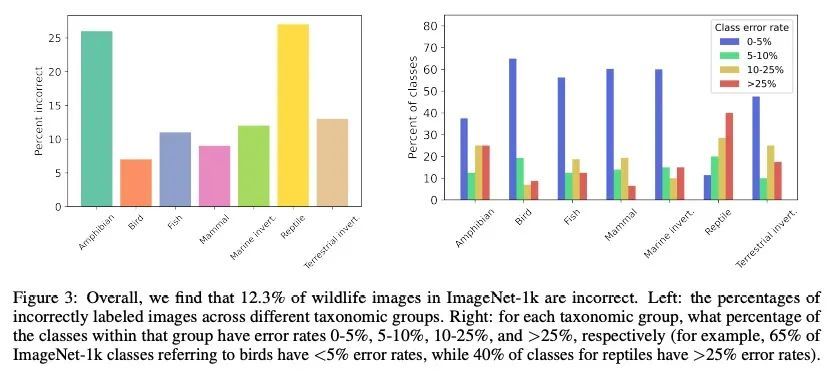
3、[CV] Bugs in the Data: How ImageNet Misrepresents Biodiversity
A S Luccioni, D Rolnick
[Hugging Face & McGill University]
数据中的错误:ImageNet对生物多样性的歪曲。ImageNet-1k是个数据集,常被用来作为机器学习(ML)模型的基准和评估图像识别和目标检测等任务。野生动物占ImageNet-1k的27%,但与代表人和物体的类不同,这些数据还没有被仔细研究过。本文分析了ImageNet-1k验证集中代表野生动物的269个类中的13450张图像,并有生态学专家参与其中。发现许多类的定义不明确或重叠,12%的图像被错误地标记,有些类有超过90%的图像不正确。还发现ImageNet-1k中包含的与野生动物相关的标签和图像都存在明显的地理和文化偏差,以及诸如人造动物、同一图像中的多个物种或人类存在等模糊性。本文的发现强调了广泛使用该数据集来评估ML系统、在野生动物相关任务中使用此类算法以及更广泛的ML数据集通常创建和策划的方式的严重问题。
ImageNet-1k is a dataset often used for benchmarking machine learning (ML) models and evaluating tasks such as image recognition and object detection. Wild animals make up 27% of ImageNet-1k but, unlike classes representing people and objects, these data have not been closely scrutinized. In the current paper, we analyze the 13,450 images from 269 classes that represent wild animals in the ImageNet-1k validation set, with the participation of expert ecologists. We find that many of the classes are ill-defined or overlapping, and that 12% of the images are incorrectly labeled, with some classes having >90% of images incorrect. We also find that both the wildlife-related labels and images included in ImageNet-1k present significant geographical and cultural biases, as well as ambiguities such as artificial animals, multiple species in the same image, or the presence of humans. Our findings highlight serious issues with the extensive use of this dataset for evaluating ML systems, the use of such algorithms in wildlife-related tasks, and more broadly the ways in which ML datasets are commonly created and curated.
https://arxiv.org/abs/2208.11695


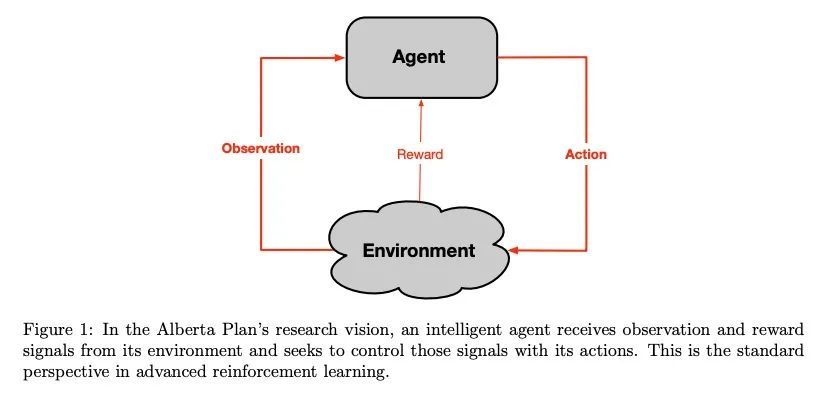
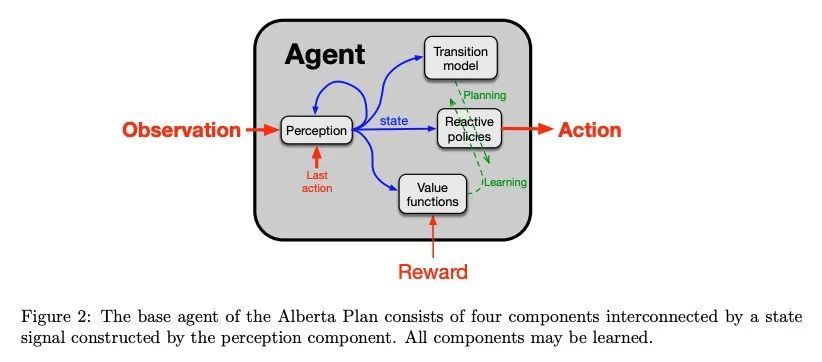
4、[AI] The Alberta Plan for AI Research
R S. Sutton, M H. Bowling, P M. Pilarski
[University of Alberta & DeepMind]
艾伯塔AI研究计划,艾伯塔计划是一个面向计算智能基本理解的长期计划,是未来5-10年的规划。它并不关注我们目前所知道如何做的直接应用,而是关注填补我们目前理解上的空白。随着计算智能逐渐被理解,它无疑将深刻地影响我们的经济、社会和个人生活。尽管所有的后果都难以预见,而且每一种强大的技术都包含着被滥用的可能性,但我们相信,更有远见的复杂智能的存在总体上对世界是有利的。按照阿尔伯塔计划,我们试图理解和创造持久的计算智能体,与一个巨大的更复杂的世界交互,来预测和控制其感觉输入信号。这些智能体之所以复杂,只是因为它们在很长一段时间内与复杂的世界交互;其最初设计是尽可能简单、通用和可扩展的。为了控制其输入信号,智能体必须采取行动。为适应变化和世界的复杂性,它们必须不断地学习。为了快速适应,必须用学到的世界模型进行规划。
The Alberta Plan is a long-term plan oriented toward basic understanding of computational intelligence. It is a plan for the next 5–10 years. It is not concerned with immediate applications of what we currently know how to do, but rather with filling in the gaps in our current understanding. As computational intelligence comes to be understood it will undoubtedly profoundly affect our economy, our society, and our individual lives. Although all the consequences are difficult to foresee, and every powerful technology contains the potential for abuse, we are convinced that the existence of more far-sighted and complex intelligence will overall be good for the world.
https://arxiv.org/abs/2208.11173

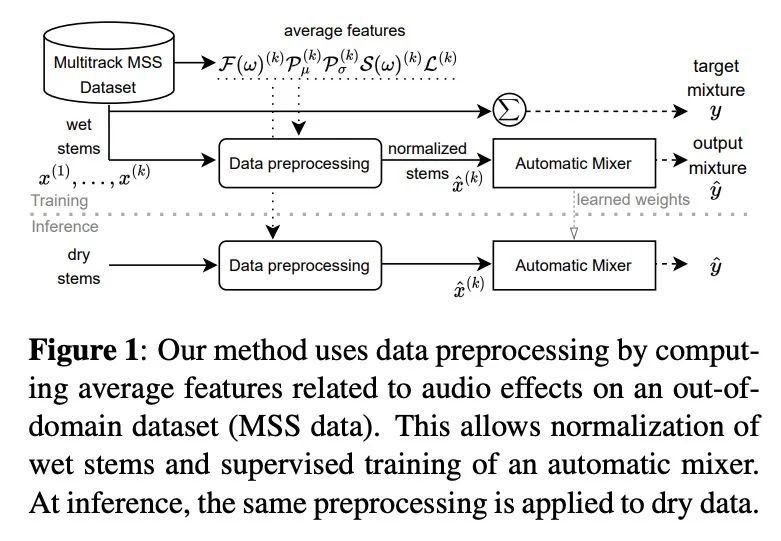
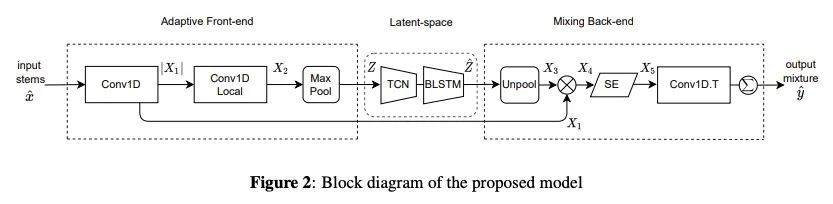
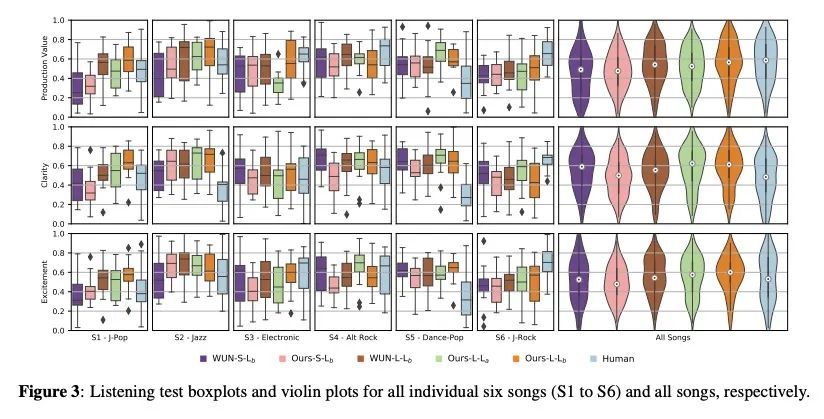
5、[AS] Automatic music mixing with deep learning and out-of-domain data
M A. Martínez-Ramírez, W Liao, G Fabbro, S Uhlich, C Nagashima, Y Mitsufuji
[Sony]
基于深度学习和域外数据的自动音乐混音。传统上,音乐混合涉及到以干净的单独音轨的形式记录乐器,并用音频效果和专家知识(例如,混音工程师)将其混合成最终的产物。近年来,音乐制作任务的自动化已成为一个新兴的领域,基于规则的方法和机器学习方法已经被探索出来。然而,缺乏纯净或干净的乐器录音限制了这类模型的性能,与专业人工混音相比仍有差距。本文探索是否可以用域外数据,如非纯净的或处理过的多轨音乐录音,并重新利用其训练有监督深度学习模型,以弥补目前自动混音质量的差距。为实现这一目标,本文提出一种新的数据预处理方法,使模型能够进行自动音乐混合。还重新设计了一种用于评估音乐混合系统的聆听测试方法。通过使用经验丰富的混音工程师作为参与者的这种主观测试来验证了所述结果。结果表明,所提出的方法成功地实现了自动响度、均衡器、DRC、平移和混响的音乐混合。与专业混音相比,所得混音在清晰度方面得分更高,在生产价值和兴奋度方面没有区别。
Music mixing traditionally involves recording instruments in the form of clean, individual tracks and blending them into a final mixture using audio effects and expert knowledge (e.g., a mixing engineer). The automation of music production tasks has become an emerging field in recent years, where rule-based methods and machine learning approaches have been explored. Nevertheless, the lack of dry or clean instrument recordings limits the performance of such models, which is still far from professional human-made mixes. We explore whether we can use outof-domain data such as wet or processed multitrack music recordings and repurpose it to train supervised deep learning models that can bridge the current gap in automatic mixing quality. To achieve this we propose a novel data preprocessing method that allows the models to perform automatic music mixing. We also redesigned a listening test method for evaluating music mixing systems. We validate our results through such subjective tests using highly experienced mixing engineers as participants.
https://arxiv.org/abs/2208.11428

另外几篇值得关注的论文:
[LG] Deriving time-averaged active inference from control principles
从控制原理推导时间平均主动推理
E Sennesh, J Theriault, J v d Meent, L F Barrett, K Quigley
[Northeastern University & University of Amsterdam]
https://arxiv.org/abs/2208.10601

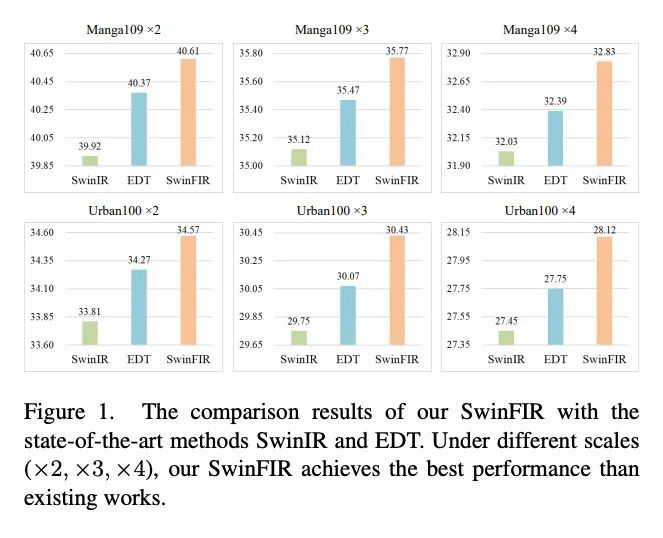
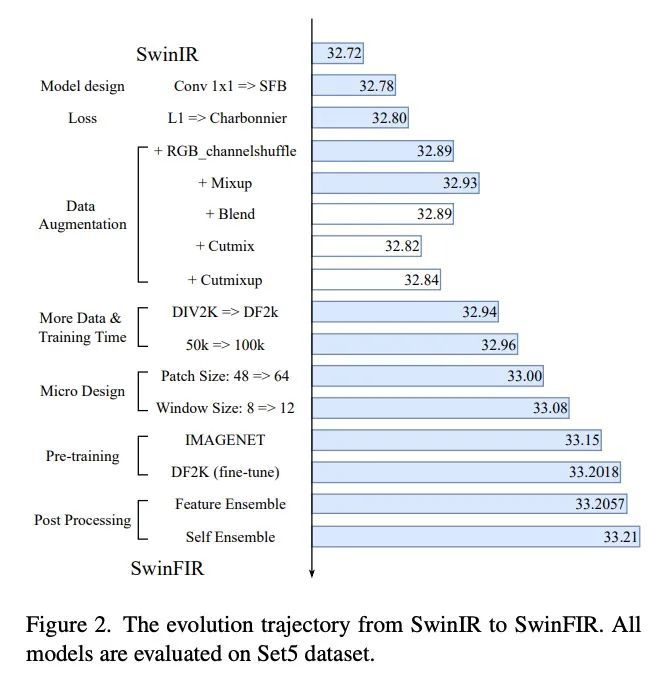
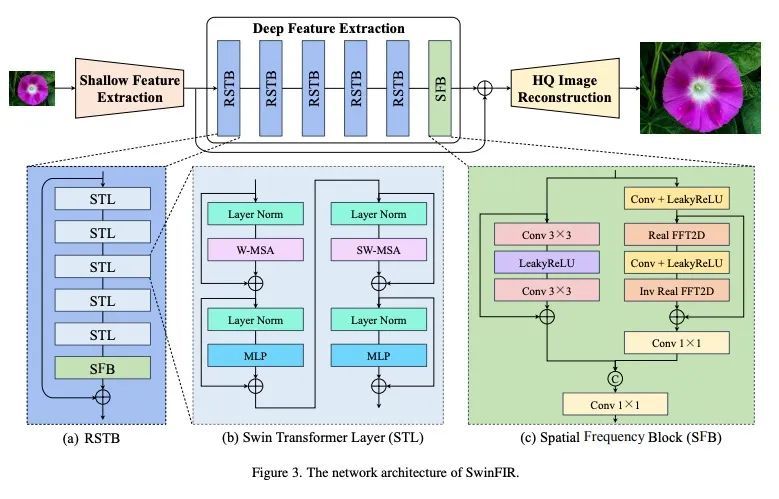
[CV] SwinFIR: Revisiting the SwinIR with Fast Fourier Convolution and Improved Training for Image Super-Resolution
SwinFIR:用快速傅里叶卷积和改进的图像超分辨率训练重新审视SwinIRD Zhang, F Huang, S Liu, X Wang, Z Jin
[Samsung Research China]
https://arxiv.org/abs/2208.11247

[CV] 3D-FM GAN: Towards 3D-Controllable Face Manipulation
3D-FM GAN:3D可控人脸操纵研究
Y Liu, Z Shu, Y Li, Z Lin, R Zhang, S.Y. Kung
[Princeton University & Adobe Research]
https://arxiv.org/abs/2208.11257




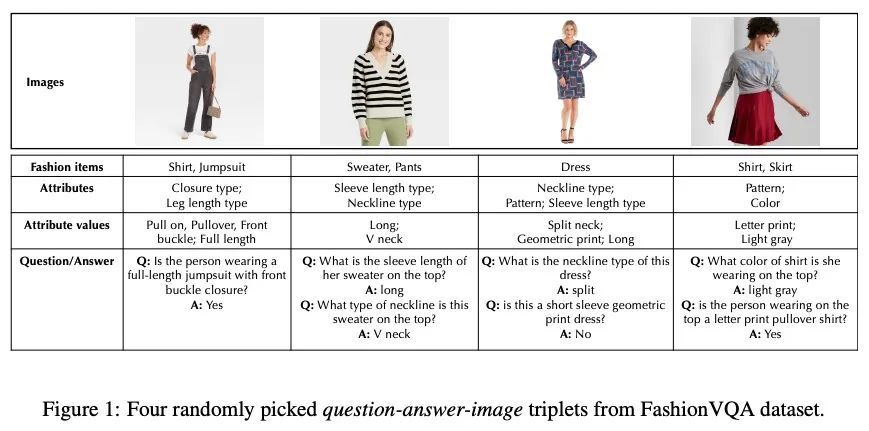
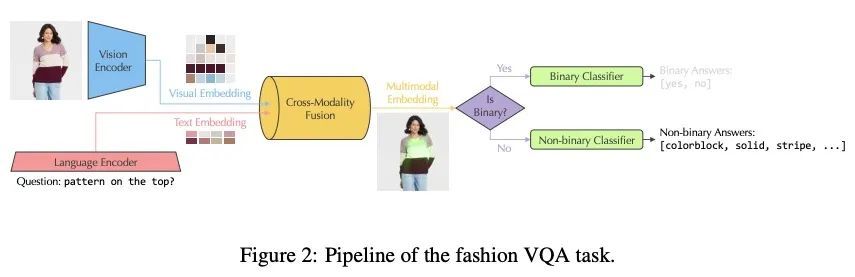
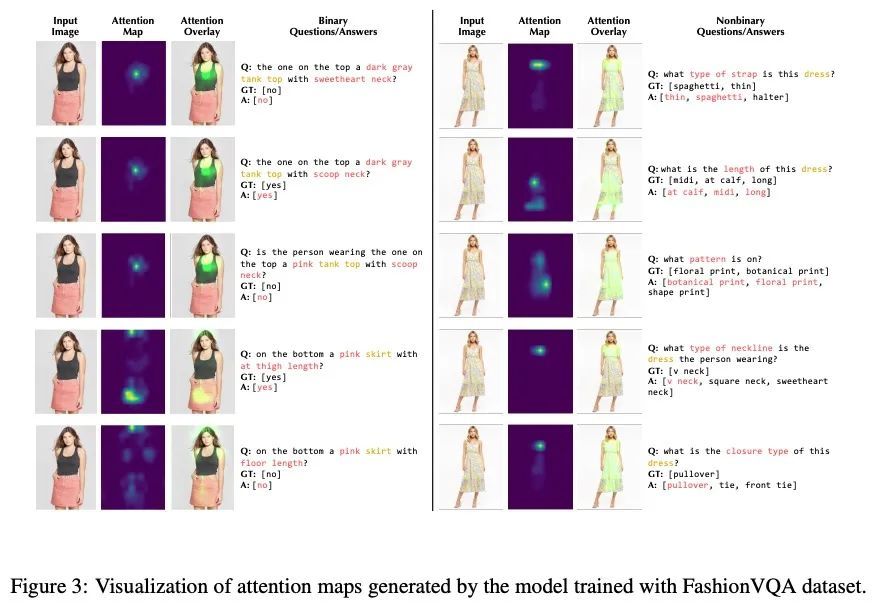
[CV] FashionVQA: A Domain-Specific Visual Question Answering System
FashionVQA:域特定视觉问答系统
M Wang, A Mahjoubfar, A Joshi
[Target Corporation]
https://arxiv.org/abs/2208.11253

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢