

论文地址:https://arxiv.org/pdf/2203.01509v1.pdf
开源代码:https: //github.com/thangvubk/SoftGroup.git
摘要
现有的最新3D实例分割方法执行语义分割,然后进行分组。执行语义分割时会做出硬预测,使每个点都与单个类关联。但是,由于艰难的决定而引起的错误传播到分组中,导致(1)预测实例与地面真实之间的低重叠(2)大量的假阳性。为了解决上述问题,本文提出了一种3D实例分割方法,称为软分组(SoftGroup),通过执行自下而上的软分组,然后进行自上而下的细化。软分组允许每个点与多个类关联,以减轻语义预测错误引起的问题,并通过学习将它们分类为背景来抑制误报实例。在不同数据集和多个评估指标上的实验结果证明了软分组的功效。其性能超过了最强的先验方法,在ScanNet V2隐藏测试集上,显着的幅度为 +6.2%,而S3DIS区域5的AP50则超过了6.8%。软分组也很快,在ScanNet v2数据集上使用单一Titan X时,每次扫描速度为345ms。
主要贡献
总体来说,我们的贡献有三个:
-
我们提出了SoftGroup根据软语义分数进行分组,以解决硬语义预测将错误传播到实例预测的问题。
-
我们提出了一个自上而下的细化阶段,以纠正、细化正样本并抑制错误语义预测导致的假阳性。
- 我们报告了在具有不同评估指标的多个数据集上的广泛实验,显示出与现有SOTA方法相比的显著改进。
软分组
软分组模块接收语义得分和偏移量作为输入,生成实例建议。首先,使用偏移向量将点向对应的实例中心移位。为了使用语义分数进行分组,我们定义了分数阈值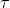 来确定一个点属于哪个语义类,允许该点与多个类相关联。给定语义分数
来确定一个点属于哪个语义类,允许该点与多个类相关联。给定语义分数![]() ,我们迭代\( N_{class} \)个类,在每个类索引处,我们对具有该(w.r.t. 类索引)分数高于阈值
,我们迭代\( N_{class} \)个类,在每个类索引处,我们对具有该(w.r.t. 类索引)分数高于阈值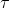 的整个场景的点子集进行切片。我们在每个点子集上遵循的形式分组。由于每个子集中的所有点都属于同一类,我们只需遍历子集中的所有点,并在几何距离小于分组带宽b的点之间创建链接,即可获得实例提案。对于每一次迭代,对整个扫描的点子集执行分组,以确保快速推理。我们注意到现有的基于提案的方法通常将边界框视为对象提案,然后在每个提案中进行分割。直观地,与实例高度重叠的边界框的中心应该靠近对象的中心,但在三维点云中生成高质量的边界框提案是具有挑战性的,因为该点只存在于对象表面上。与之相反的是,SoftGroup依赖于更准确的点级提案,并自然地继承了点云的散布特性。
的整个场景的点子集进行切片。我们在每个点子集上遵循的形式分组。由于每个子集中的所有点都属于同一类,我们只需遍历子集中的所有点,并在几何距离小于分组带宽b的点之间创建链接,即可获得实例提案。对于每一次迭代,对整个扫描的点子集执行分组,以确保快速推理。我们注意到现有的基于提案的方法通常将边界框视为对象提案,然后在每个提案中进行分割。直观地,与实例高度重叠的边界框的中心应该靠近对象的中心,但在三维点云中生成高质量的边界框提案是具有挑战性的,因为该点只存在于对象表面上。与之相反的是,SoftGroup依赖于更准确的点级提案,并自然地继承了点云的散布特性。
由于分组实例提案的质量高度依赖于语义分割的质量,因此我们定量地分析了阈值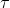 对语义预测召回率和查准率的影响。第\( j \)个类的召回率和查准率定义如下:
对语义预测召回率和查准率的影响。第\( j \)个类的召回率和查准率定义如下:

下图显示了与硬语义预测相比,分数阈值τ的召回和精度。通过艰苦的语义预测,召回率为79.1%,表明班级的20%以上的积分不涵盖预测。使用分数阈值时,召回率随着分数阈值的降低而增加。但是,小分阈值也导致较低的精度。我们提出了一个上层完善阶段,以减轻精度问题。精度可以解释为对象实例的前景和背景点之间的关系。我们将阈值设置为0.2,精度接近50%,从而导致前景和背景点之间的比率保持平衡。

实验
下表显示了软分组在ScanNet v2基准的隐藏测试集上使用的最新方法的结果。我们提交我们的模型并从服务器报告结果。所提出的软分组达到了最高的平均AP50%,达到了76.1%,以6.2%的显著差距超过了以前最强的方法。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢