
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:主题驱动生成的文本-图像扩散模型微调、势函数塑造作为梯度、面向新闻插图的多模态图像生成、用掩码自蒸馏推进对比语言-图像预训练、用掩码自编码器实现高效知识蒸馏、移动事件相机神经辐射场、高效异构视频边缘分割、用于未知意图检测的零样本管线、通过重采样减轻实验性社交网络中的偏差放大
1、[CV] DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
N Ruiz, Y Li, V Jampani, Y Pritch, M Rubinstein, K Aberman
[Google Research]
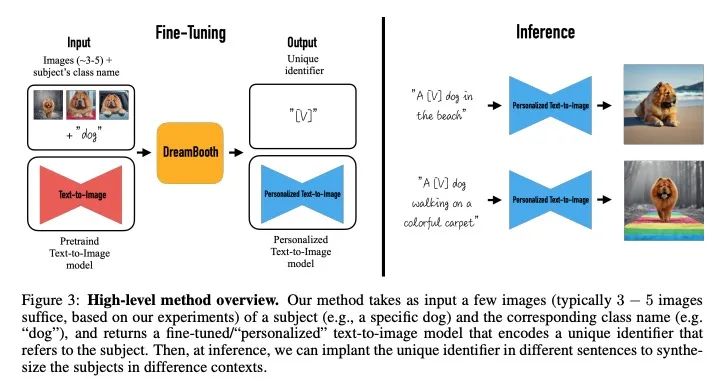
DreamBooth: 主题驱动生成的文本-图像扩散模型微调。大型文本到图像模型在人工智能的发展过程中实现了一个显著的飞跃,能从给定的文本提示中合成高质量和多样化的图像。然而,这些模型缺乏模仿给定参考集中的主体外观和合成不同背景下的全新演绎的能力。本文提出一种文本-图像扩散模型"个性化"的新方法,根据用户需要对生成过程进行特定处理。给定一个主题的几张图片作为输入,对预训练的文本-图像模型(Imagen,尽管方法不限于特定模型)进行微调,使其学会将一个独特的标识符与该特定主题绑定。一旦主题被嵌入到模型的输出域中,这个唯一的标识符就可以用来合成该主题在不同场景中完创新的逼真图像。通过利用嵌入在模型中的语义先验和新的自体类先验保留损失,该技术能在不同的场景、姿态、视角和照明条件下合成参考图像中未出现的主体。本文将该技术应用在了几个之前无法完成的任务,包括主体重构、文本指导的视图合成、外观修改和艺术渲染(同时保留主体的关键特征)。
Large text-to-image models achieved a remarkable leap in the evolution of AI, enabling high-quality and diverse synthesis of images from a given text prompt. However, these models lack the ability to mimic the appearance of subjects in a given reference set and synthesize novel renditions of them in different contexts. In this work, we present a new approach for “personalization” of text-to-image diffusion models (specializing them to users’ needs). Given as input just a few images of a subject, we fine-tune a pretrained text-toimage model (Imagen, although our method is not limited to a specific model) such that it learns to bind a unique identifier with that specific subject. Once the subject is embedded in the output domain of the model, the unique identifier can then be used to synthesize fully-novel photorealistic images of the subject contextualized in different scenes. By leveraging the semantic prior embedded in the model with a new autogenous class-specific prior preservation loss, our technique enables synthesizing the subject in diverse scenes, poses, views, and lighting conditions that do not appear in the reference images. We apply our technique to several previously-unassailable tasks, including subject recontextualization, text-guided view synthesis, appearance modification, and artistic rendering (all while preserving the subject’s key features). Project page: https://dreambooth.github.io/
https://arxiv.org/abs/2208.12242



2、[LG] Calculus on MDPs: Potential Shaping as a Gradient
E Jenner, H v Hoof, A Gleave
[University of Amsterdam & UC Berkeley]
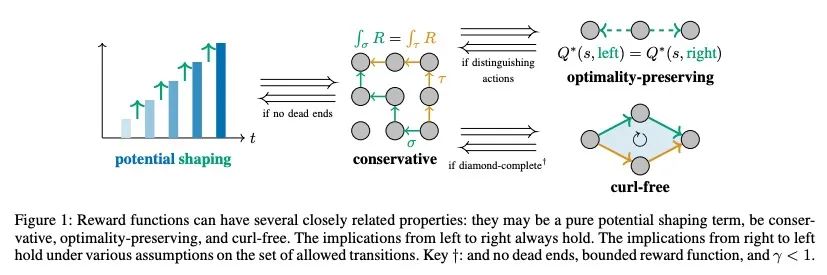
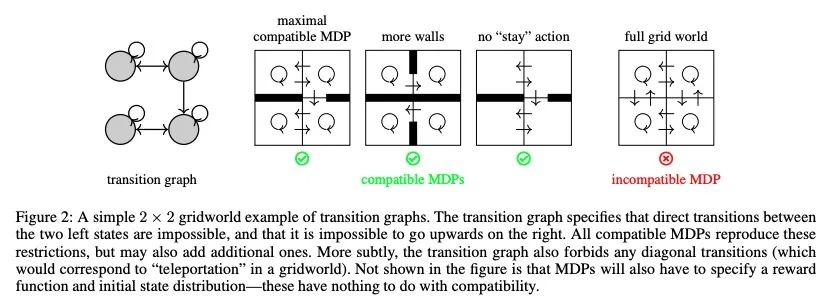
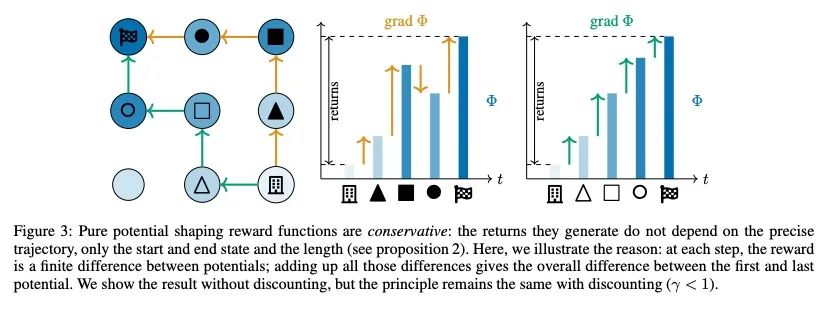
MDP上的微积分:势函数塑造作为梯度。在强化学习中,不同的奖励函数在它们所引起的最优策略方面可以是等价的。一个特别著名和重要的例子是势函数塑造,这是一类可以添加到任何奖励函数而不改变任意过渡动态下的最优策略集的函数。势函数塑造在概念上类似于数学和物理学中的势、保守矢量场和规整变换,但这种联系以前还没有被正式探讨过。本文为图上的离散微积分开发了一个形式化,对马尔科夫决策过程进行了抽象,并展示了势函数塑造如何在这个框架内被正式解释为一个梯度。使得能够加强Ng、Harada和Russell的结果,这些结果描述了势函数塑造是唯一能始终保持最优策略的加性奖励变换的条件。作为该形式化的额外应用,本文定义了一种规则,用于从每个势函数塑造的等价类中挑选一个单一的奖励函数。
In reinforcement learning, different reward functions can be equivalent in terms of the optimal policies they induce. A particularly well-known and important example is potential shaping, a class of functions that can be added to any reward function without changing the optimal policy set under arbitrary transition dynamics. Potential shaping is conceptually similar to potentials, conservative vector fields and gauge transformations in math and physics, but this connection has not previously been formally explored. We develop a formalism for discrete calculus on graphs that abstract a Markov Decision Process, and show how potential shaping can be formally interpreted as a gradient within this framework. This allows us to strengthen results from Ng, Harada, and Russell (1999) describing conditions under which potential shaping is the only additive reward transformation to always preserve optimal policies. As an additional application of our formalism, we define a rule for picking a single unique reward function from each potential shaping equivalence class.
https://arxiv.org/abs/2208.09570

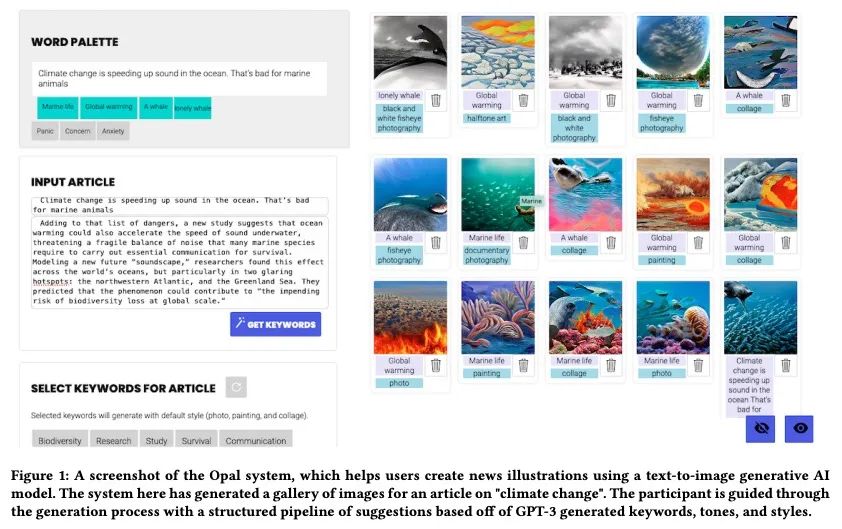
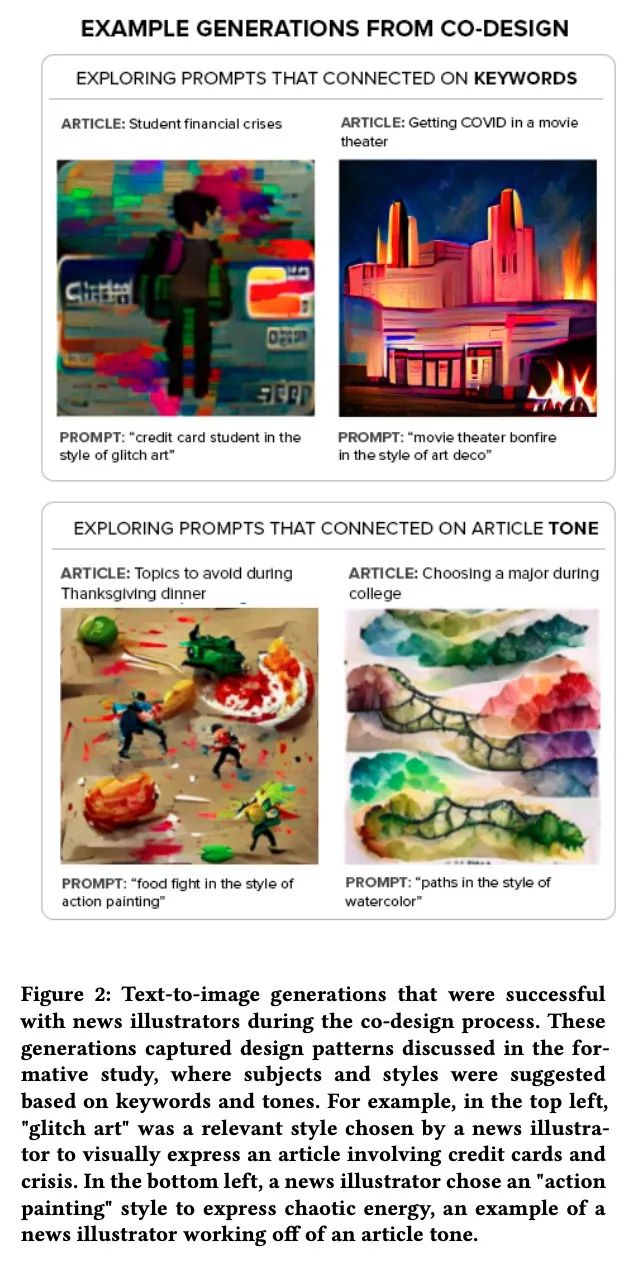
3、[CV] Opal: Multimodal Image Generation for News Illustration
V Liu, H Qiao, L Chilton
[Columbia University & University of Toronto]
Opal: 面向新闻插图的多模态图像生成。多模态人工智能的进步为人们提供了从文本创造图像的强大方式。最近的工作表明,文本到图像的生成能够代表广泛的主题和艺术风格。然而,为文本提示找到合适的视觉语言是很困难的。本文用Opal来解决这一挑战,Opal是一个为新闻插图制作文字到图像的系统。给定一篇文章,Opal引导用户进行结构化的视觉概念搜索,并提供一个管道让用户根据文章的语气、关键词和相关的艺术风格来生成插图。评估显示,Opal有效地生成了不同的新闻插图、视觉产品和概念想法。使用Opal的用户产生的可用结果是没使用Opal的用户的2倍。本文讨论了结构化探索如何帮助用户更好地理解人类人工智能共同创造系统的能力。
Advances in multimodal AI have presented people with powerful ways to create images from text. Recent work has shown that text-to-image generations are able to represent a broad range of subjects and artistic styles. However, finding the right visual language for text prompts is difficult. In this paper, we address this challenge with Opal, a system that produces text-to-image generations for news illustration. Given an article, Opal guides users through a structured search for visual concepts and provides a pipeline allowing users to generate illustrations based on an article's tone, keywords, and related artistic styles. Our evaluation shows that Opal efficiently generates diverse sets of news illustrations, visual assets, and concept ideas. Users with Opal generated two times more usable results than users without. We discuss how structured exploration can help users better understand the capabilities of human AI co-creative systems.
https://arxiv.org/abs/2204.09007


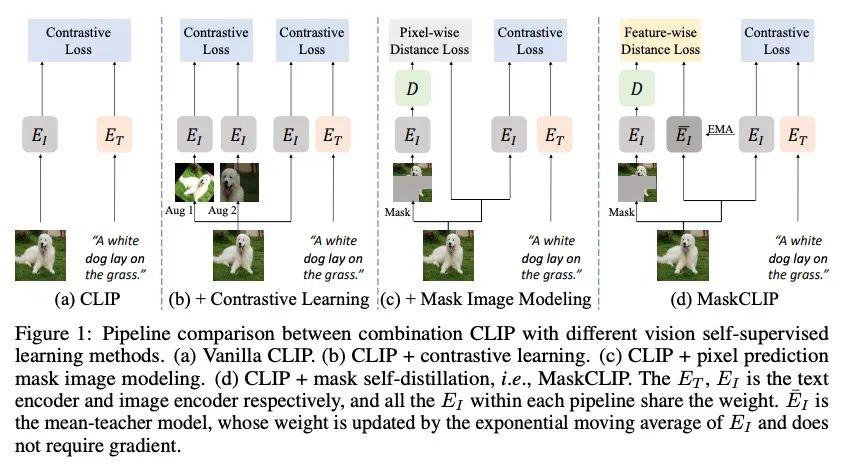
4、[CV] MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining
X Dong, Y Zheng, J Bao...
[University of Science and Technology of China & Xiamen University & Microsoft Research Asia]
MaskCLIP: 用掩码自蒸馏推进对比语言-图像预训练。本文提出一种简单而有效的框架MaskCLIP,将新提出的掩码自蒸馏纳入对比语言-图像预训练。掩码自蒸馏的核心思想是将完整图像中的表示提炼成由掩码图像预测的表示。这种结合享有两种重要的好处。首先,掩码自蒸馏的目标是局部图块表示学习,这与视觉-语言对比地关注文本相关表示是相辅相成的。第二,从训练目标的角度,掩码自蒸馏也与视觉语言对比一致,因为两者都利用视觉编码器来进行特征对齐,因此能从语言中获得间接监督来学习局部语义。本文提供了专门设计的实验和全面的分析来验证这两个优点。经验表明,MaskCLIP在应用于各种挑战性的下游任务时,在语言编码器的指导下,在线性探测、微调以及零样本方面取得了卓越的性能。
This paper presents a simple yet effective framework MaskCLIP, which incorporates a newly proposed masked self-distillation into contrastive language-image pretraining. The core idea of masked self-distillation is to distill representation from a full image to the representation predicted from a masked image. Such incorporation enjoys two vital benefits. First, masked self-distillation targets local patch representation learning, which is complementary to vision-language contrastive focusing on text-related representation. Second, masked self-distillation is also consistent with vision-language contrastive from the perspective of training objective as both utilize the visual encoder for feature aligning, and thus is able to learn local semantics getting indirect supervision from the language. We provide specially designed experiments with a comprehensive analysis to validate the two benefits. Empirically, we show that MaskCLIP, when applied to various challenging downstream tasks, achieves superior results in linear probing, finetuning as well as the zero-shot performance with the guidance of the language encoder.
https://arxiv.org/abs/2208.12262


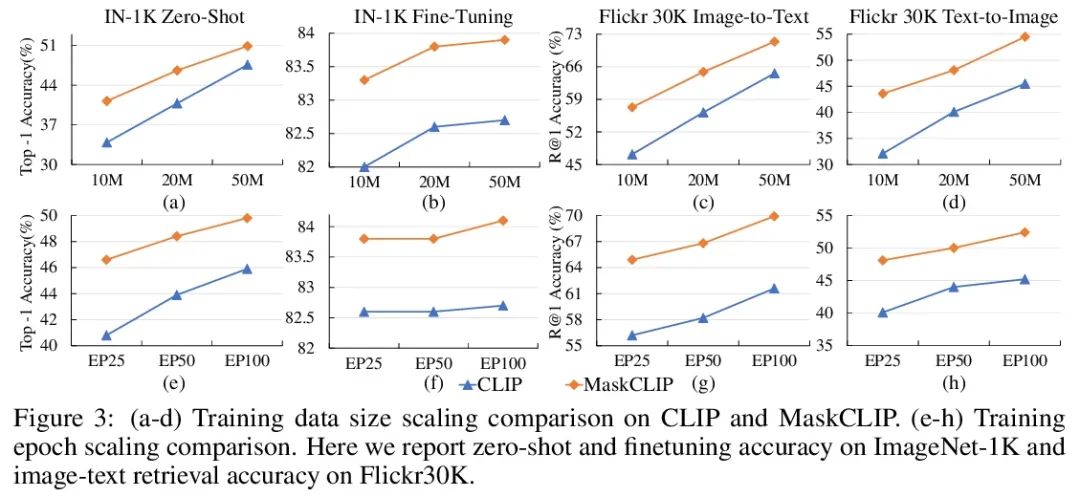
5、[CV] Masked Autoencoders Enable Efficient Knowledge Distillers
Y Bai, Z Wang, J Xiao, C Wei, H Wang, A Yuille, Y Zhou, C Xie
[Johns Hopkins University & University of California, Santa Cruz & FAIR]
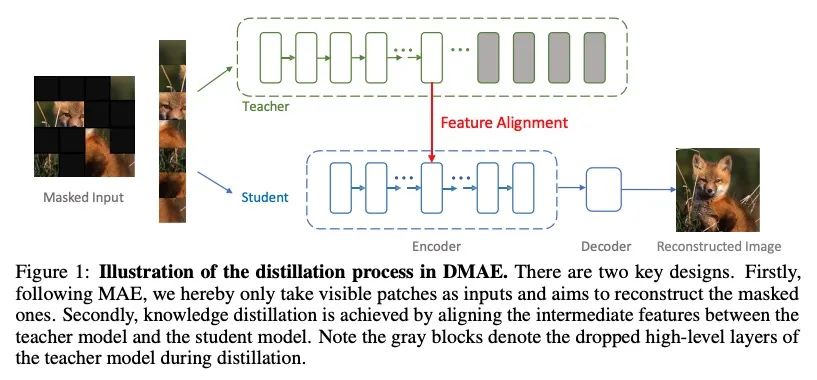
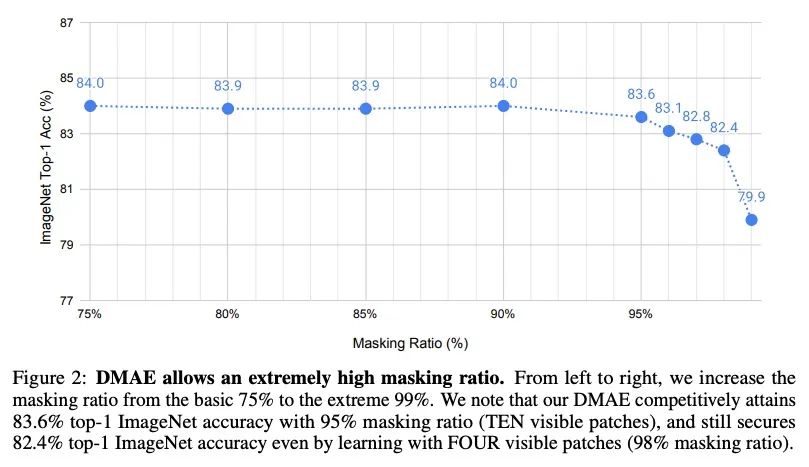
用掩码自编码器实现高效知识蒸馏。本文研究了从预训练模型,特别是掩码自编码器中提炼知识的潜力。方法很简单:除了优化被掩码输入的像素重建损失外,还最小化教师模型和学生模型的中间特征图之间的距离。这种设计导致了一个计算效率高的知识提炼框架,因为:1)只用一小部分可见的图块子集;2)(繁琐的)教师模型只需要部分执行,即通过前几层前向传播输入,以获得中间特征图。与直接蒸馏微调模型相比,蒸馏预训练的模型大大改善了下游性能。例如,通过将MAE预训练的ViT-L的知识提炼成ViT-B,所提出方法达到了84.0%的ImageNet top-1准确率,比直接提炼微调的ViT-L的基准高出1.2%。该方法即使在极高的掩码率下也能鲁棒地从教师模型中提炼出知识:例如,在95%的掩码率下,在提炼过程中只有10个图块是可见的,得到的ViT-B在竞争中获得了83.6%的ImageNet Top-1准确率;令人惊讶的是,它仍然可以通过积极训练只有4个可见图块(98%掩码率)来保证82.4%的ImageNet Top-1准确率。
This paper studies the potential of distilling knowledge from pre-trained models, especially Masked Autoencoders. Our approach is simple: in addition to optimizing the pixel reconstruction loss on masked inputs, we minimize the distance between the intermediate feature map of the teacher model and that of the student model. This design leads to a computationally efficient knowledge distillation framework, given 1) only a small visible subset of patches is used, and 2) the (cumbersome) teacher model only needs to be partially executed, i.e., forward propagate inputs through the first few layers, for obtaining intermediate feature maps. Compared to directly distilling fine-tuned models, distilling pre-trained models substantially improves downstream performance. For example, by distilling the knowledge from an MAE pre-trained ViT-L into a ViT-B, our method achieves 84.0% ImageNet top-1 accuracy, outperforming the baseline of directly distilling a fine-tuned ViT-L by 1.2%. More intriguingly, our method can robustly distill knowledge from teacher models even with extremely high masking ratios: e.g., with 95% masking ratio where merely TEN patches are visible during distillation, our ViT-B competitively attains a top-1 ImageNet accuracy of 83.6%; surprisingly, it can still secure 82.4% top-1 ImageNet accuracy by aggressively training with just FOUR visible patches (98% masking ratio). The code and models are publicly available at https://github.com/UCSC-VLAA/DMAE.
https://arxiv.org/abs/2208.12256

另外几篇值得关注的论文:
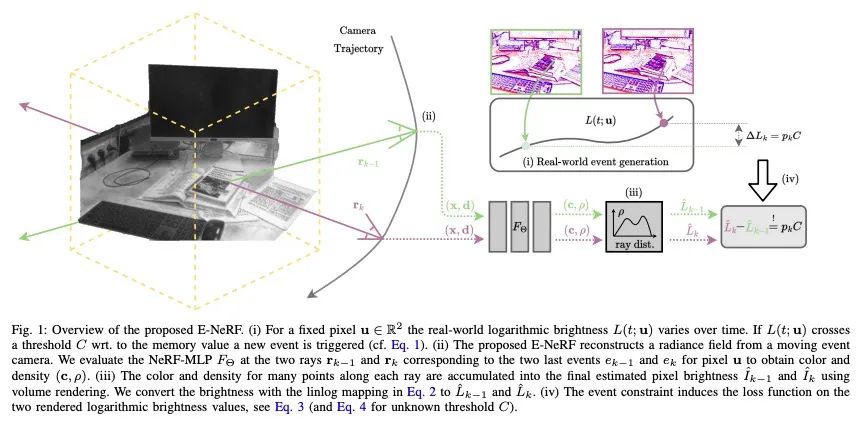
[CV] E-NeRF: Neural Radiance Fields from a Moving Event Camera
E-NeRF:移动事件相机神经辐射场
S Klenk, L Koestler, D Scaramuzza, D Cremers
[Technical University of Munich & University of Zurich]
https://arxiv.org/abs/2208.11300



[CV] Efficient Heterogeneous Video Segmentation at the Edge
高效异构视频边缘分割
J M Lin, S Pisarchyk, J Lee, D Tian, T Hou, K Raveendran, R Sarokin, G Sung, T Tolley, M Grundmann
[Google]
https://arxiv.org/abs/2208.11666



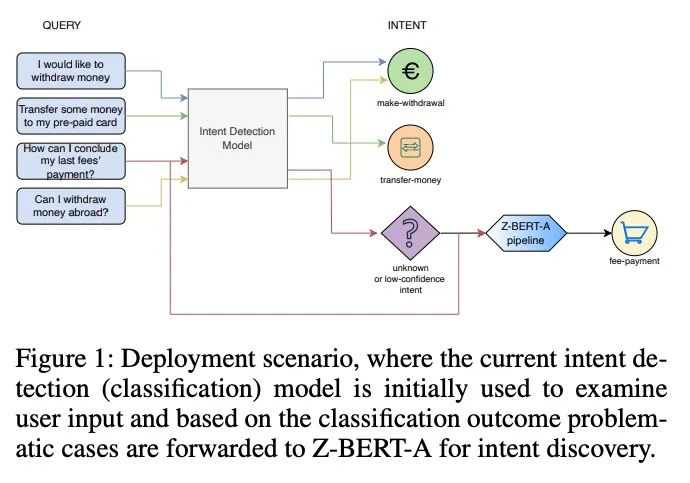
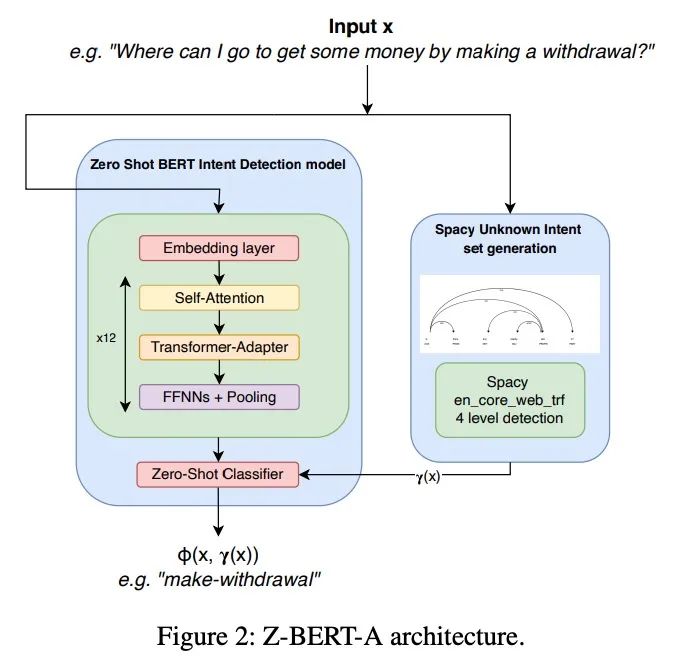
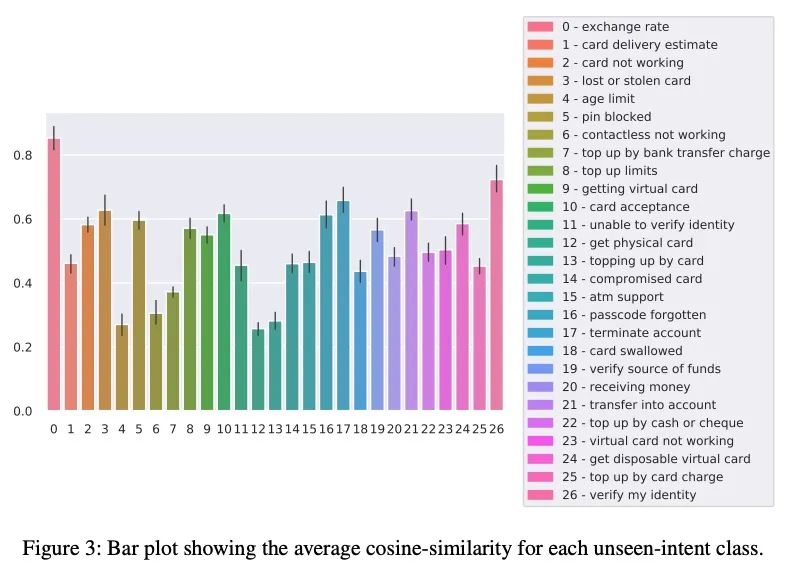
[CL] Z-BERT-A: a zero-shot Pipeline for Unknown Intent detection
Z-BERT-A:用于未知意图检测的零样本管线
D Comi, D Christofidellis, P F Piazza, M Manica
[IBM]
https://arxiv.org/abs/2208.07084

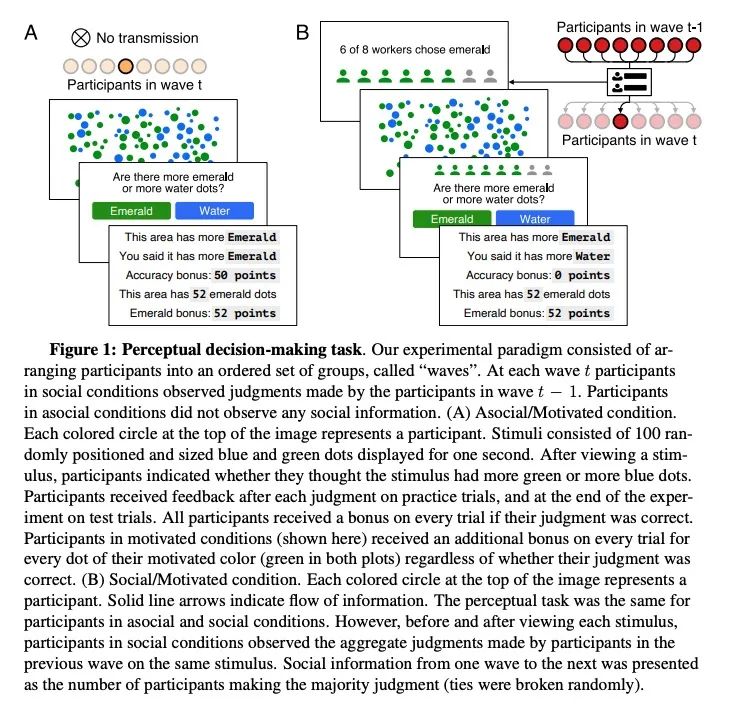
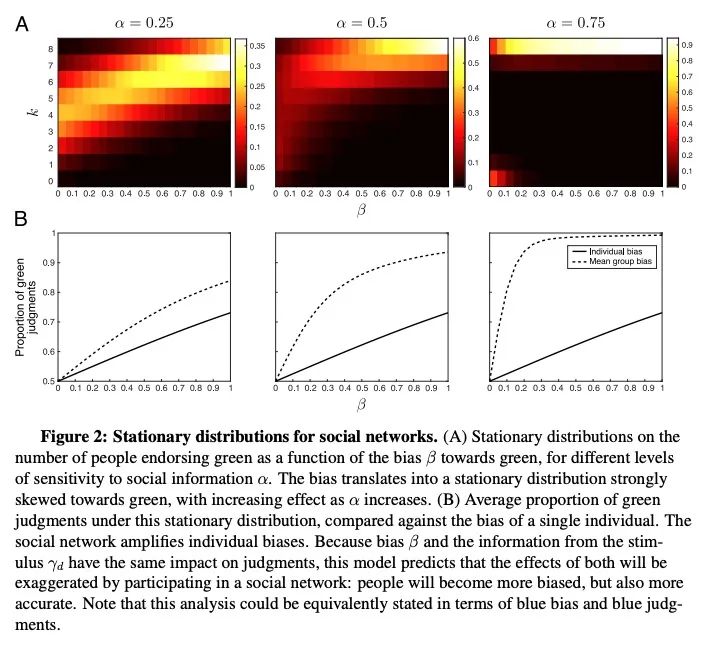
[SI] Bias amplification in experimental social networks is reduced by resampling
通过重采样减轻实验性社交网络中的偏差放大
M D. Hardy, B D. Thompson, P.M. Krafft, T L. Griffiths
[Princeton University & UC Berkeley & University of the Arts London]
https://arxiv.org/abs/2208.07261

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢