

论文地址:https://arxiv.org/pdf/2203.01439.pdf
开源代码:https://github.com/cdluminate/robdml
摘要
由于对抗性弱点的安全影响,深度度量学习模型的对抗性稳健性必须得到改善。为了避免模型因过硬的例子而崩溃,现有的防御措施摒弃了最小最大值的对抗性训练,而是低效地从弱对抗者那里学习。相反,我们提出了 "硬度操纵"(Hardness Manipulation),根据更硬的良性三要素或伪硬度函数,有效地扰动训练三要素,直到指定的硬度水平,用于对抗性训练。它很灵活,因为常规训练和最小-最大对抗训练是它的边界情况。此外,渐进对抗(Gradual Adversary),一个伪硬度函数系列被提出来,在训练过程中逐渐增加指定的硬度水平,以便在性能和稳健性之间取得更好的平衡。此外,在良性案例和对抗性案例之间的类内结构损失项进一步提高了模型的稳健性和效率。综合实验结果表明,所提出的方法虽然形式简单,但在鲁棒性、训练效率以及在良性实例上的表现方面,都压倒性地超过了最先进的防御方法。
主要贡献
总而言之,我们的贡献包括提出:
- 硬度操纵(HM)是一种灵活而有效的工具,可以创建对抗性示例三重态,以进行DML模型的后续训练。
- 线性渐进对抗(LGA)作为渐进的对抗,即HM的伪硬度函数,它结合了我们的经验观察,可以在训练过程中平衡训练目标。
- 阶层内结构(ICS)损失项,以进一步提高模型的鲁棒性和对抗性训练效率,而这种结构被现有防御能力忽略了。
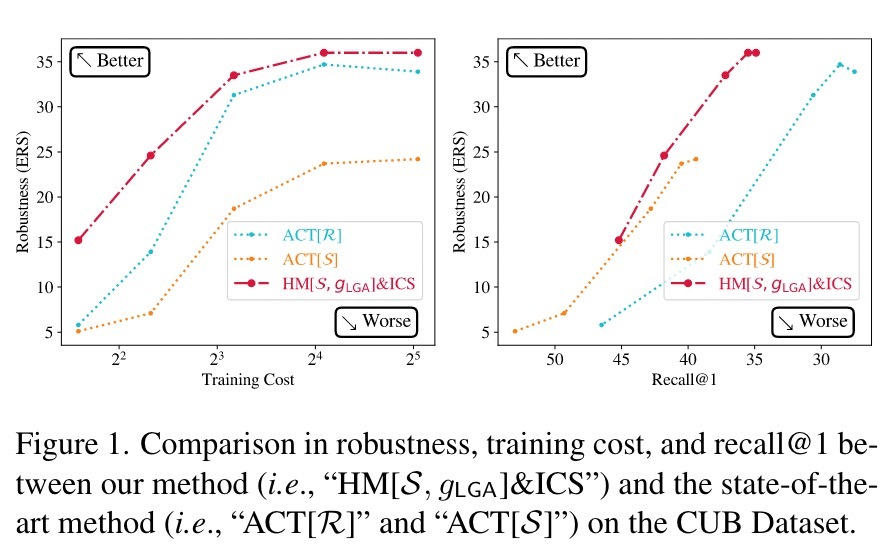
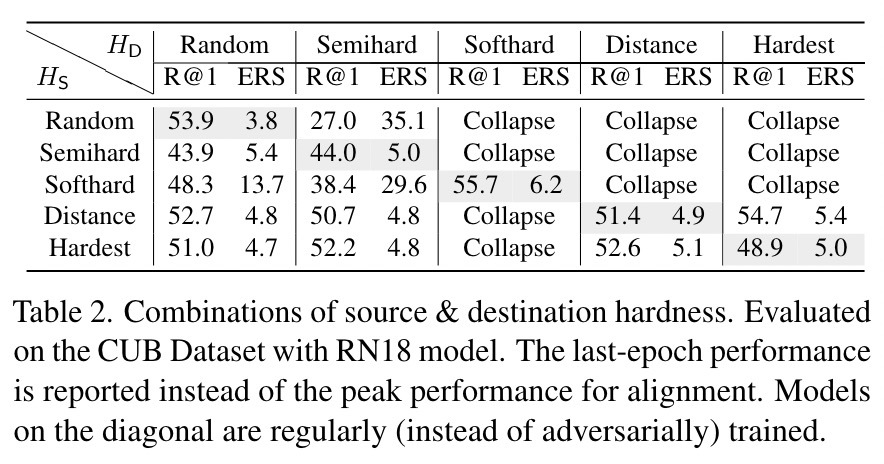
实验
为了验证我们的防御方法,我们对三个常用的DML数据集进行了实验:CUB-200-2011(CUB),CARS-196(CARS)和Stanford-online-Product(SOP)。我们遵循与最先进的防御工作[55]和标准DML [27]相同的实验设置,以易于比较。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢