

论文地址:https://arxiv.org/pdf/2208.12262.pdf
摘要
本文提出了一个简单而有效的框架MaskCLIP,该框架将新提出的掩膜自蒸馏纳入对比的语言图像预处理中。掩膜自蒸馏的核心思想是将表示从完整的图像提取到掩膜图像预测的表示形式。这种合并有两个重要的优势。首先,掩盖的自我鉴定目标是局部贴片表示学习,这与视觉对比度的互补,重点关注与文本相关的表示。其次,从训练目标的角度来看,掩盖的自我缩减也与视觉语言对比相一致,因为两者都利用视觉编码器进行特征对齐,因此能够学习本地语义从语言中获得间接监督。我们提供了专门设计的实验,并进行了全面的分析,以验证这两个优势。从经验上讲,我们表明,当MaskCLIP应用于各种具有挑战性的下游任务时,可以在线性探测,填充和零样本中取得卓越的结果,并在语言编码器的指导下取得了卓越的结果。
主要贡献
总而言之,这项工作的主要贡献是:
- 我们提出了一个新颖的视觉预训练框架,并通过引入一个掩盖的自我验证目标来掩盖框架,以促进VL对比度以获得更好的可传递视觉模型。
- 我们介绍了对MaskCLIP变体的广泛消融实验,并在数值和视觉上提供深入的分析,以帮助了解建议的掩盖自我验证如何有助于VL对比。
- 我们在数十个基准测试上演示了MaskCLIP模型,显示了所有三个设置下的优越性:零样本,线性探测和微调。
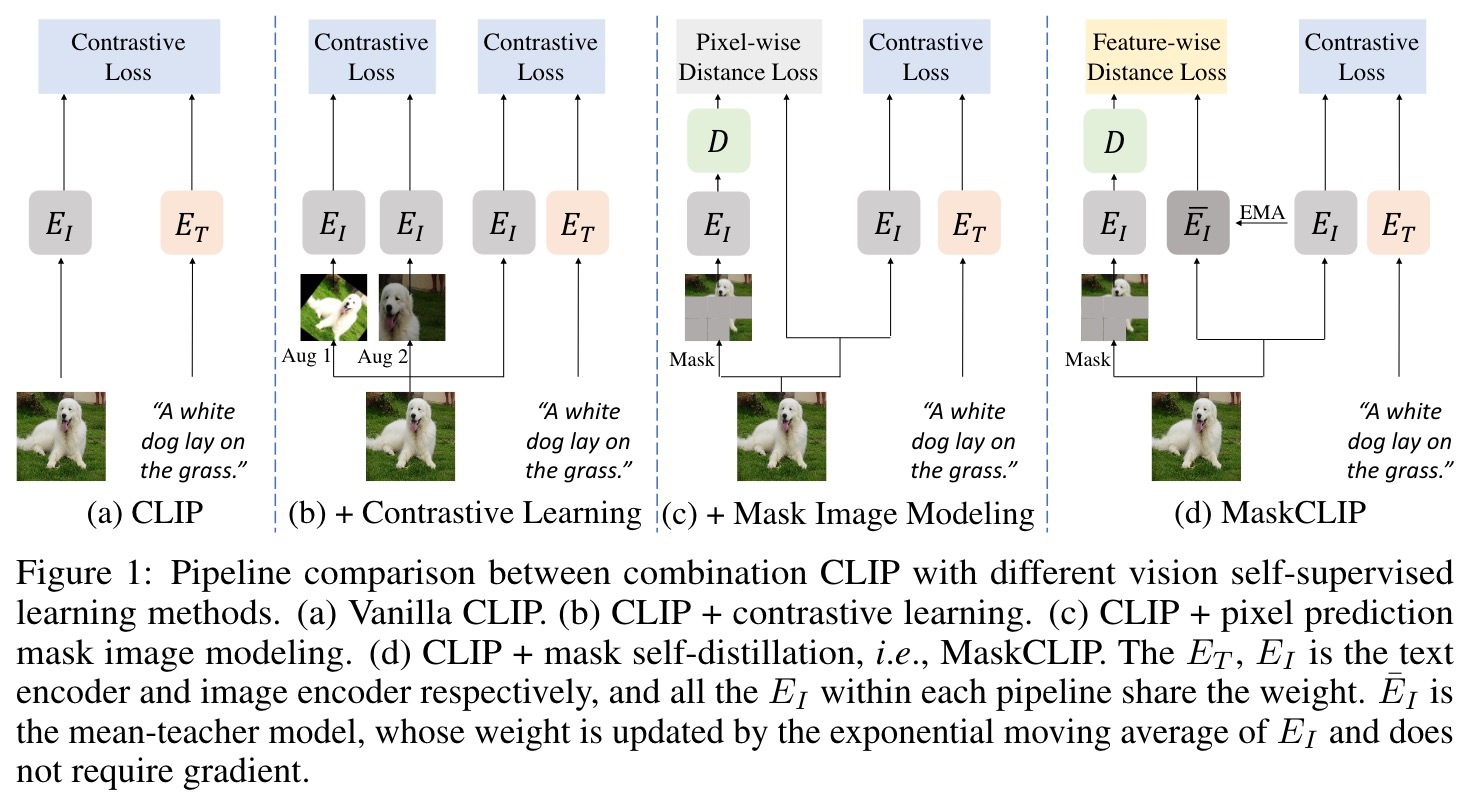
MaskCLIP
我们介绍了MaskCLIP,这是一个学习视觉表示的新颖框架。 MaskCLIP的核心部分是其骨干图像编码器,如图1所示,由EI表示。它在预处理过程中获得了可转移能力,可以使下游视觉任务受益。在最近的自我监督方法之后,我们将骨干\( E_I \)设定为视觉Transformer(ViT)。 \( E_I \)给定的输入图像I的预测结果,然后应该是视觉特征令牌的集合,表示为:
![]()
在这里,\( cls \)是类别token的缩写,\( 1,……N \)是非类令牌的索引。
实验
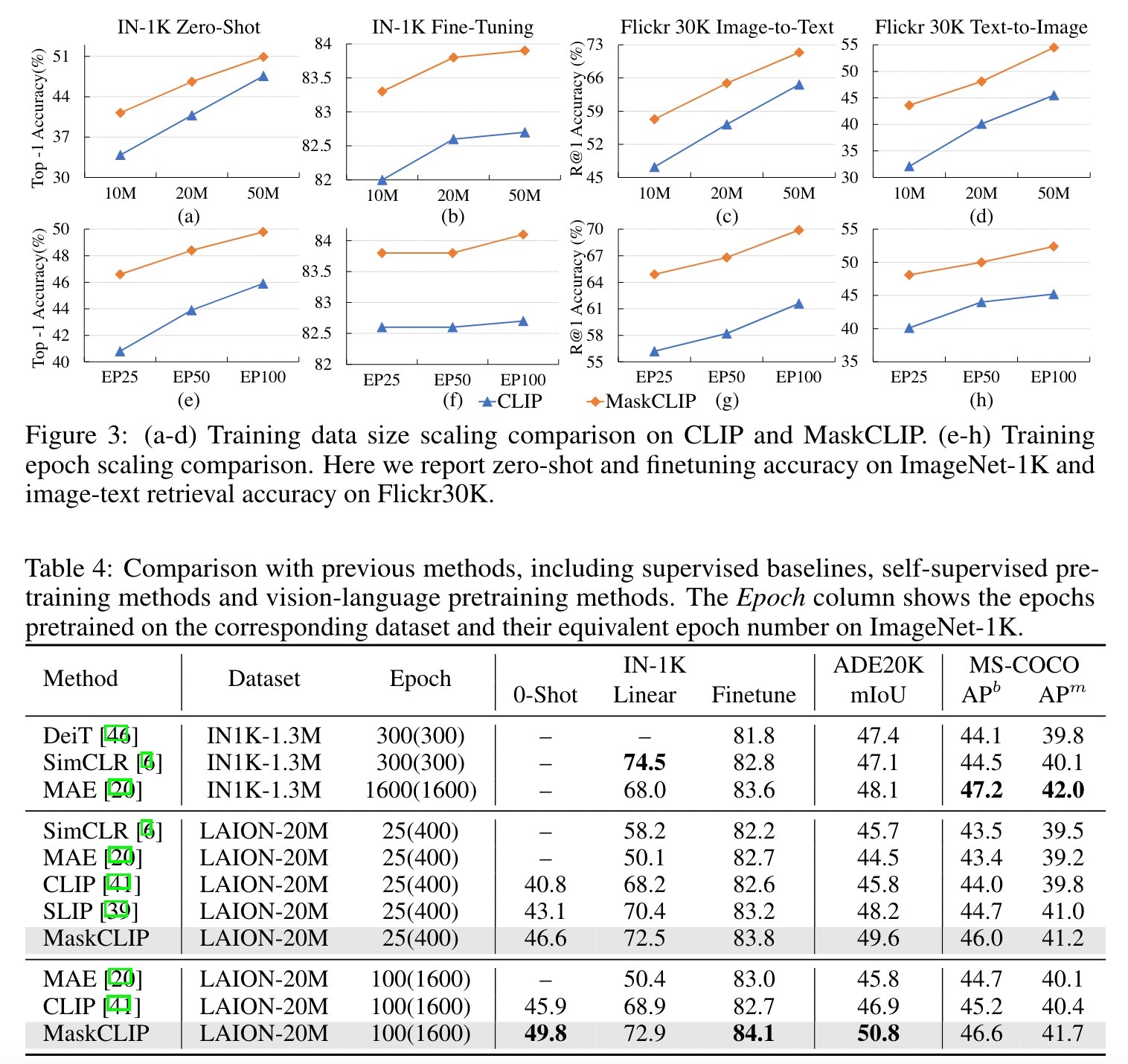
为了显示MaskCLIP作为一种通用视觉先进方法的有效性,我们对视觉任务进行实验。对于视觉任务,我们报告了Imagenet-1K分类,MS-COCO对象检测和ADE20K 语义分割的结果。对于视觉-语言任务,我们在25个数据集上报告了零样本结果,并在Flickr30K 和MS-COCO上报告了图像文本检索结果。在下文中,我们将监督基线DeiT [46],自监督方法SimCLR 和MAE 以及视觉-语言方法CLIP和SLIP进行比较。为了进行公平的比较,我们在LAION-20M上以相同的时代训练SimCLR和MAE。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢