

摘要
人们不断地推动人工智能(AI)尽可能地像人类智能一样;然而,这是一项艰巨的任务,因为它无法学习超出其目前的理解能力。类比推理(AR)已被提议作为实现这一目标的方法之一。目前的文献缺乏对心理学启发的和自然语言处理产生的AR算法的技术比较,这些算法在基于单词的多选题类比问题上具有一致的指标。评估是基于 "正确性 "和 "良好性 "指标的。对于所有的文本问题,并没有一个通用的算法。作为视觉类比推理的贡献,卷积神经网络(CNN)与AR矢量空间模型Global Vectors(GloVe)在拟议的Image Recognition Through Analogical Reasoning Algorithm(IRTARA)中被整合。IRTARA结果质量是通过定义、类比推理和人为因素评估方法来衡量的。研究表明,AR有可能通过其在文本和视觉问题空间中理解超出其基础知识概念的能力,促进更多类似人类的人工智能。
1 前言
在整个娱乐界,人们都认为机器人是人工智能(AI)的化身,几乎可以立即识别和探测物体。然而,对于今天的人工智能来说,现实是明显不同的。运行中的人工智能被训练成能够理解、识别或对几个已知的实例采取行动;然而,像人类一样,对人工智能可能遇到的每个场景进行训练是不可行的,所以它有一些未知的场景,图1-1的行数。当付诸实践时,人工智能可以观察到或接触到它知道或不知道的东西(情况、物体等)。其结果是,人工智能的交互涉及图1-1所示的四类可能的结果之一,基于实体是已知的(库内)还是未知的(库外),从正确分类(已知的已知)、错误分类(未知的已知)或各种库外情况(已知的未知和未知的未知)(Situ, Friend, Bauer, & Bihl, 2016)。
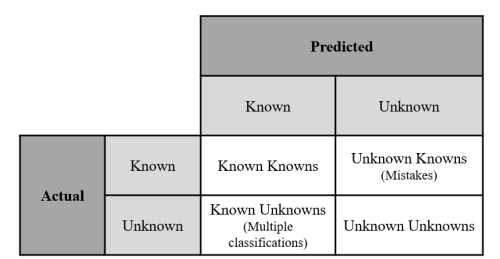
图1-1. 已知和未知矩阵
在图1-1的三个类别中,至少有一个部分是已知的,然而,人们对探索如何 "学习 "未知的未知数有很大的兴趣。未知数的例子是试图识别一个机器学习(ML)算法以前没有训练过的物体。探索这一领域的动机包括自动化系统的不断增长,以及无法产生能够在已知-未知情况下评估问题的模型数量(Bihl & Talbert, 2020)。
现代娱乐业将人工智能展示为能够几乎立即解决未知的未知问题,正如2004年和2008年的电影《iRobot》和《Wall-E》所展示的那样。虽然这两部电影都发生在比现在更晚的未来,但它们给人留下的印象是人工智能比它的真实情况要自如得多。在这两部电影中,人工智能可以识别极其广泛的物体和情况,而观察所需的时间似乎是最少的。这项任务本质上是复杂的,涉及多个人工智能过程,包括图像识别、未知事物的识别和分类,以及复杂的推理逻辑。在这种情况下使用的人工智能俗称包括许多涉及模式识别或ML的方法和领域;虽然ML是人工智能的一个子集,但俗称的人工智能/ML可以用来包括许多能力,从分类和图像处理到完全机器意识的计算机。
为了更好地说明人工智能在图像识别方面的状况,图1-2.a所示的图像由人类(即作者)和谷歌云的Vision AI进行评估。如图1-2.b所示,人类会很容易地识别出天空中的许多烟花,然后,识别出烟花下面的水。对人类观察者来说,这幅图像显然包含了多个物体;然而,视觉人工智能对这一结论感到挣扎。

图1-2. 烟花图像
Vision AI包括Vision API,可以对图像中的各种物体/特征进行分类、识别和检测(Google, 2021)。使用他们的工具的网络演示,图1-2.a所示的同一图像被通过,并在两种不同的情况下被评估,物体识别和图像标签。Vision AI只对物体进行识别,图1-3中的绿框表示的是闪电,得分是51%(其中 "得分 "是一个从无信心,0%到高信心,100%的值(Google, 2021))。
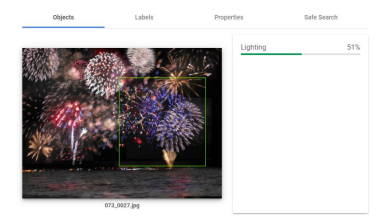
图1-3. 由谷歌云视觉AI分解的烟花图像(谷歌,2021年)
然而,当试图只给整个图像贴上标签而不是搜索特定的物体时,Vision AI明显改善了其预测结果。这些结果,即排名、标签和分数,都显示在表1-1中。开头用 "t-"表示的排名代表得分相同。在排名的顶部,这些标签似乎适合于该图像,特别是 "烟花 "以96%的分数出现在顶部。有几个标签激起了人们对该算法如何工作的好奇心。尽管 "地标 "和 "空间 "的得分是77%,但如果从图像的表面价值来看,它们是不准确的。有几个标签似乎很难被普遍可视化,如 "午夜"、"事件 "和 "假日"。最后,有些标签可能是准确的,也可能是不准确的,这取决于标签的使用环境(例如,同音字,如 "光 "的亮度或重量,这两个词在这里都很合适),以及图片的拍摄环境(例如,"除夕"、"排灯 "和 "中国新年")。
表1-1. 谷歌云端视觉AI标签预测
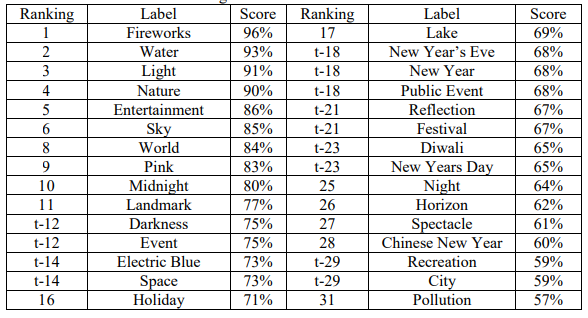
退一步讲,这很可能是一个已知的情况;然而,除了表1-1中的 "烟花 "标签外,其余的顶级分类(得分大于或等于90%)都在不描述图像的类别上,例如 "水"、"光 "或 "自然"。这就是图像分类由于其对它所知道的类/标签的限制而提供了非常狭窄的结果。能够准确地解释或识别这些未知的东西,是目前文献中非常感兴趣的。解决未知数的一个建议是通过应用类比推理(AR),从而通过类比进行推理/学习。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢