
上篇文章我们介绍了基于 Transformer 和扩散模型(Diffussion Model)的序列建模(sequence modelling)方法在强化学习,特别是离线连续控制领域的应用。这其中 Trajectory Transformer(TT)和 Diffusser 属于基于模型的规划型算法,它们展现出了非常高精度的轨迹预测已经很好的灵活性,但是相对来说决策延迟也比较高。尤其是 TT 将每个维度独立离散化作为序列中的符号,这使得整个序列变得非常长,而且序列生成的耗时会随着状态和动作的维度提升快速升高。
为了让轨迹生成模型能被达到实用级别的决策速度,我们在和 Diffusser 平行(有重叠但是应该稍晚)的时候开始了高效轨迹生成与决策的项目。我们首先想到的是用连续空间内的 Transformer+Mixture of Gaussian 而非离散分布来拟合整个轨迹分布。虽然不排除实现上的问题,但是这种思路下我们没能获得一个比较稳定的生成模型。随后我们尝试了 Variational Autoencoder(VAE),并且取得了一定的突破。不过 VAE 的重建(reconstruction)精度不是特别理想,使得下游的控制表现和 TT 相差比较大。在几轮迭代之后,我们最终选定了 VQ-VAE 作为轨迹生成的基础模型,最终得到了一个能高效采样和规划,并且在高维度控制任务上表现远超其它基于模型方法的新算法,我们称为 Trajectory Autoencoding Planner(TAP)。

规划效率与高维下的表现
在单个 GPU 下,TAP 能轻松以 20Hz 的决策效率进行在线决策,在低维度的 D4RL 任务中下决策延迟只有 TT 的 1% 左右。更重要的是随着任务状态和动作维度 D 的增加,TT 的理论决策延迟会以三次方增长,Diffusser 理论上会线性增长 ,而 TAP 的决策速度则不受维度影响 。而在智能体的决策表现方面,随着动作维度增高,TAP 相对于其它方法的表现出现了提升,相对于基于模型方法(如 TT)的提升尤为明显。
决策延迟对决策和控制任务的重要性是非常明显的,像 MuZero 这样的算法虽然在模拟环境中表现优异,但是面对现实世界中需要实时快速响应的任务,过高的决策延迟就会成为它部署的一大困难。此外,在拥有模拟环境的前提下,决策速度慢也会导致类似的算法的测试成本偏高,同时被运用在在线强化学习中的成本也会比较高。
此外,我们认为让序列生成建模方法能顺利扩展到维度较高的任务上也是 TAP 一个很重要的贡献。现实世界中我们希望强化学习能最终解决的问题其实大都有较高的状态和动作维度。比如对于自动驾驶来说,各路传感器的输入哪怕经过各种感知层面的预处理也不太可能小于 100。复杂的机器人控制往往也有很高的动作空间,人类的所有关节自由度大概是 240 左右,也就对应了至少 240 维的动作空间,一个和人一样灵活的机器人也需要同样高维的动作空间。

四组维度逐渐升高的任务
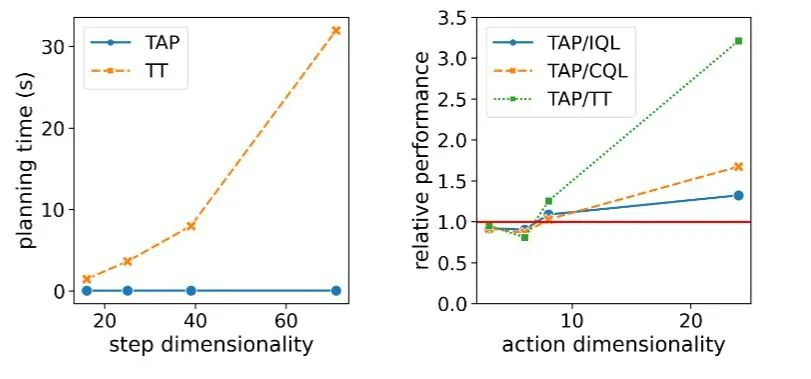
决策延迟和相对模型表现随着任务维度增长的变化
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢