
当前,多模态预训练工作受限于数据基本只支持英语。而多语言多模态预训练旨在将高资源语言(例如英语)上的多模态能力迁移至低资源语言上。现有的多语言多模态方法虽然提高了低资源语言上的多模态效果,但是,在最近提出的多语言多模态测评榜单 IGLUE 上,这些方法在低资源语言上的效果仍然明显低于“translate-test”的效果,难以用于实际。(“translate-test”即指输入文本翻译到英语,然后使用英语多模态模型测评。)
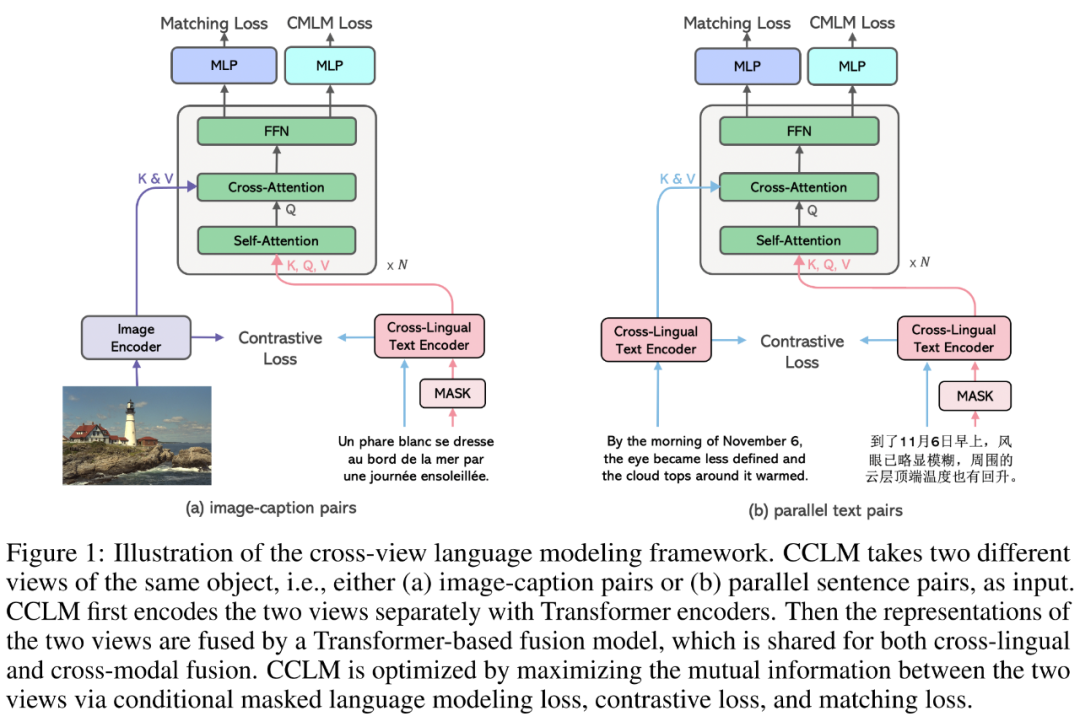
在这篇文章中,字节跳动 AI Lab Research 团队发现多语言预训练和多模态预训练都是在拉近同一对象的不同表示形式(view),因此提出 Cross-View Language Modeling,通过最大化同一对象的不同表示形式之间的互信息,以统一的方法拉近图像-文本对与平行文本对做多语言多模态预训练。该方法虽然概念相对简单,但是在多种语言下的多模态任务上远超过之前的最佳模型,包括:基于视觉的自然语言推断任务(VNLI)、图像文本检索(image-text retrieval)、视觉问答(VQA)、视觉推理(NLVR)等。

论文链接:
https://arxiv.org/abs/2206.00621
代码链接:
https://github.com/zengyan-97/CCLM
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢