

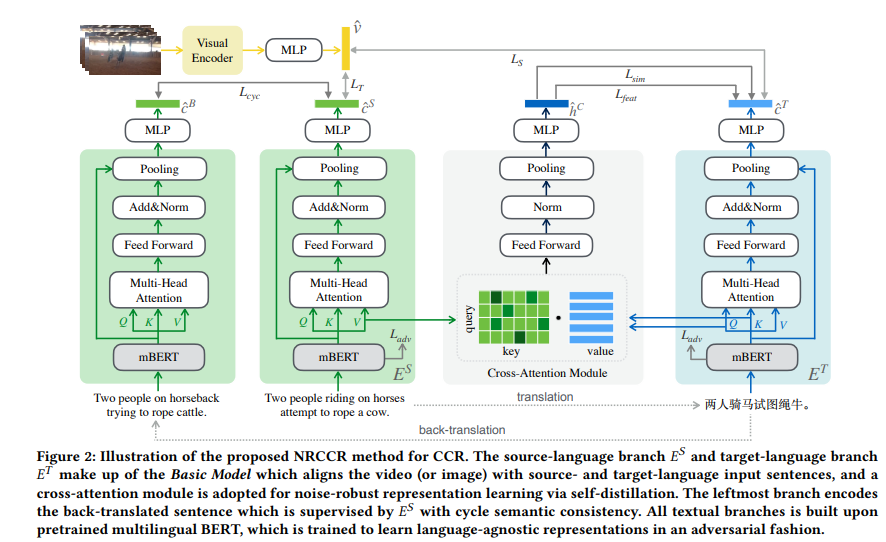
尽管近年来跨模态检索领域取得了长足的发展,但由于缺乏人工标注的数据集,针对低资源语言的研究较少。针对低资源语言,提出一种抗噪的跨语言跨模态检索方法.为此,我们使用机器翻译(MT)为低资源语言构造伪平行句子对。然而,由于机器翻译的不完善性,它在翻译过程中容易引入噪声,使得文本嵌入被破坏,从而影响检索性能。为了解决这一问题,本文提出了一种多视角自提取方法来学习噪声鲁棒的目标语言表示,该方法利用交叉注意模块生成软伪目标,从基于相似度的视角和基于特征的视角提供直接监督。此外,受无监督机器翻译中回译的启发,我们最小化原始句子和回译句子之间的语义差异,以进一步提高文本编码器的噪声鲁棒性。在三个跨语言的视频—文本和图像—文本跨模态检索基准上进行了大量实验,实验结果表明,该方法在不使用额外人工标注数据的情况下显著提高了整体性能.此外,配备有来自最近的视觉和语言预训练框架的预训练的视觉编码器,即,CLIP的测试结果表明,该方法与常用的预训练模型具有良好的兼容性。
论文链接:https://arxiv.org/pdf/2208.12526.pdf
代码链接:https://github.com/HuiGuanLab/nrccr
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢