

论文地址:
代码地址:https://github.com/Carlisle-Liu/OCENet
摘要
对于伪装物体检测,由于伪装前景和背景的外观相似,很难获得高精度的标注,尤其是物体边界周围的标注。作者认为,直接使用“嘈杂”的伪装图进行训练可能会导致泛化能力较差的模型。在本文中,作者引入了一种显式的偶然不确定性估计技术来表示由于噪声标记而产生的预测不确定性。具体而言,作者提出了一种使用动态监督的感知伪装对象检测 (COD) 框架,以产生准确的伪装图和可靠的 “偶然不确定性”。与根据点估计pipeline生成确定性预测的现有技术不同,本文的框架将偶然不确定性形式化为模型输出和输入图像上的概率分布。经过训练后,本文的置信度估计网络可以评估预测的像素精度,而无需依赖ground truth图像。大量结果表明,所提出的模型在解释伪装预测方面具有优越的性能。
贡献
深度学习系统在实际应用中很受欢迎,例如自动驾驶。然而,这种深度神经网络(DNN)模型的故障可能会导致灾难性后果,对其可靠性提出质疑。因此,能够根据不确定性解释DNN模型预测至关重要。
现有深度神经网络中存在两种主要类型的不确定性,即表示数据分布中固有噪声的偶然不确定性(aleatoric uncertainty),例如标注模糊性和捕捉模型预测中不确定性的认知不确定性(epistemic uncertainty)。通过有足够的数据观察,可以减少认知不确定性。
已经做了大量的研究来模拟这两种不确定性。他们通常采用贝叶斯神经网络(BNN)框架。用于不确定性估计的BNN的主要问题是难以处理的后验推理,因此大多数现有的不确定性估计技术都集中于设计近似的后验推理。
伪装被定义为一种状态,在这种状态下,物体具有与周围环境无法识别的伪装外观,这是动物界广泛应用的一种隐藏自己的技术,欺骗捕食者做出错误判断。这是通过各种伪装技术实现的。这种自然现象也激发了艺术伪装的发展,例如军事伪装。伪装动物的不可区分性对标注提出了巨大挑战,标注更容易出现嘈杂的标签。作者提出通过模拟偶然不确定性来捕捉这种标注不一致性。

偶然不确定性估计的现有技术涉及一个额外的方差估计模块来表示偶然不确定性。在错误预测时最大化无界方差,以最小化损失,并采用L2正则化,以防止其变得非常大。
不同的是,作者提出了一种创新的在线置信度估计网络(OCENet)来模拟伪装目标检测中的偶然不确定性。作者动态推导预测和ground truth之间的差异,作为OCENet内不确定性估计模块的监督。通过这种设置,本文的OCENet能够将错误分类的区域识别为不确定区域,并将低不确定值分配给正确预测的区域。如上图所示,本文的估计置信度图能够将高度不确定性分配给欠分割、过分割、幻影分割。
本文的主要贡献为:
- 作者提出了一种创新的在线置信度估计网络(OCENet)来建模偶然不确定性,用于伪装目标检测。它输出像素级的不确定性,显示true-negative预测和false-positive预测,以防止网络overconfident;
- 本文的OCENet在不依赖ground truth的情况下提供了预测的初步评估;
- 作者进一步提出了一种困难感知学习伪装目标检测框架,以有效利用偶然不确定性进行难例挖掘。实验结果表明,本文的模型在解释模型预测方面具有优越的性能。
方法
1. Overview
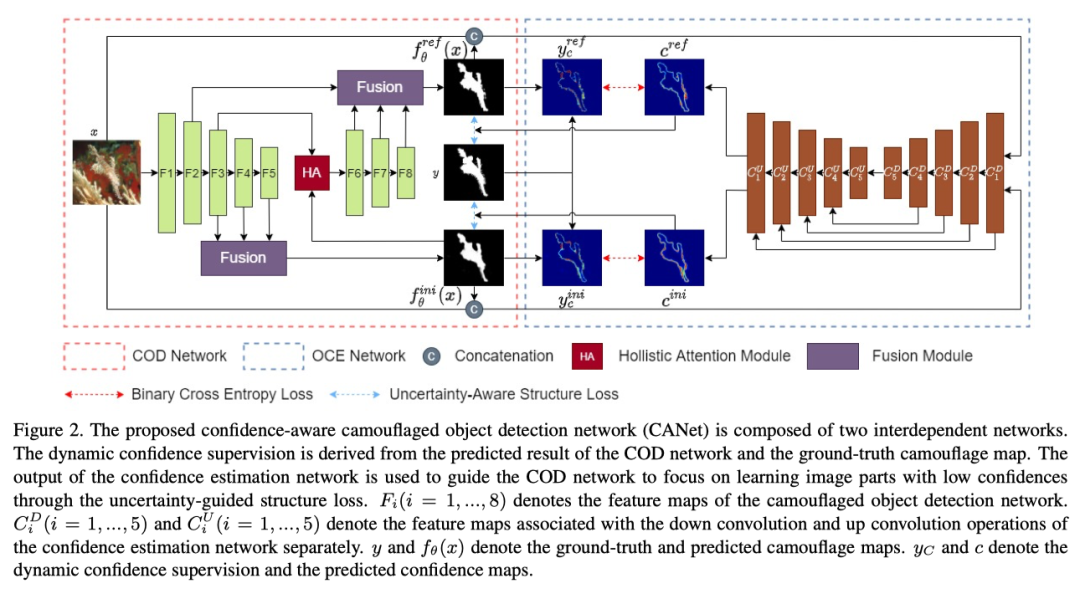
作为一个二进制分割网络,伪装目标检测模型通常遵循给定输入图像回归伪装图的传统做法。作者引入了一个相互监督的伪装目标检测学习框架来直接建模任意不确定性。本文的框架中包括两个主要模块,即用于生成伪装图的伪装目标检测网络(CODNet)和用于明确估计当前预测中任意不确定性的在线可信度估计网络(OCENet)。作者在上图中展示了本文的框架。
本文的训练数据集是D={xn,yn}n=1N,其中xn和yn是图像及其对应的ground truth伪装图,n为训练图像建立索引,N是训练数据集的大小。将CODNet定义为f,从而生成预测的图像。然后,OCENet将预测的伪装图和图像的concat作为输入,以估计像素级的不确定性图,表明模型对CODNet预测的感知。
2. Camouflaged Object Detection Network
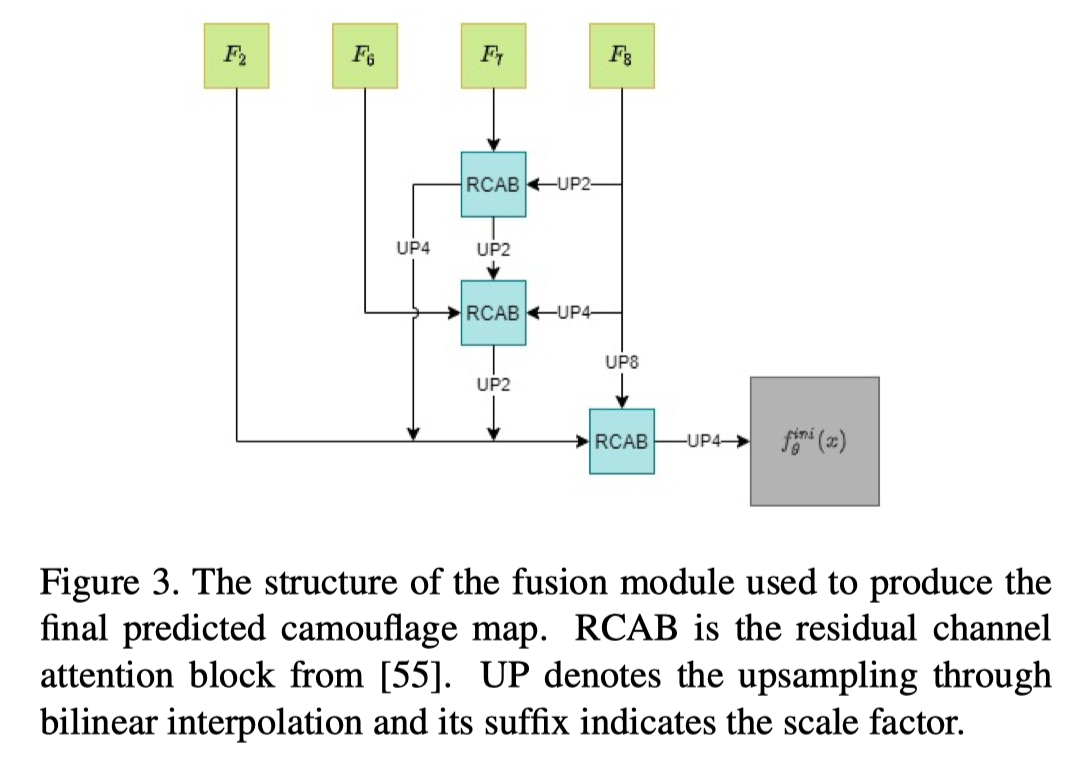
本文的CODNet采用ResNet-50编码器来生成特征映射Fi,提出了一种融合模块(FM)来组合不同层次的特征图。如上图所示,FM逐渐将高级特征与低级特征融合。在每个融合操作中,包含最高级别的特征以提供语义指导。
利用特征映射F3-5的初始预测yini还作为特征图F3的注意机制。通过F6将穿过残差块获得F7,8。最终预测yref通过融合特征图F2,6-8来计算。相对较低级别的特征图F2提供了更多的空间信息,这对于分割任务恢复更清晰的结构非常重要。
给定输入图像x,本文的伪装目标检测网络产生两种不同的预测:在(0,1)范围内的yini和yref,其中为两种预测提供监督。该设置允许初始预测恢复更完整的伪装对象,随后作为更好的注意力图来过滤特征图F3。采用最终预测作为伪装目标检测结果进行评估。
3. Online Confidence Estimation Network
OCENet采用U-Net结构来获得像素精确的不确定性预测。它由5个表示为CiD的下卷积特征和5个表示为CiU的上卷积特征组成,具有成对的相应分辨率。提出的下卷积块有两个3×3卷积层(“Conv3”),每个层后面是一个Batch归一化和一个Leaky ReLU激活函数,负斜率设置为0.2,还有一个dropout layer。下卷积运算可以表示为: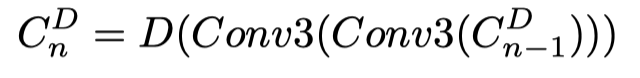
上卷积块由一个2×2转置卷积层(“TConv2”)和两个3×3卷积层组成,每个卷积层后面都有一个Batch归一化和一个具有0.2负斜率的Leaky ReLU激活函数。下卷积和上卷积特征在两个卷积层之前concat。在转置卷积层之后和上卷积操作结束时,使用rate为0.5的dropout层。上卷积运算可以总结为: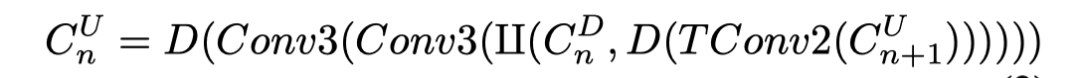
其中II()表示concat操作。
CODNet将模型预测和图像x的concat作为输入,以生成一个单通道置信图,该图Cini用于初始预测,并且cref进行最终预测。估计的置信度图由动态不确定性进行监督,动态不确定性监督源自伪装目标检测网络f和ground-truth伪装图y的预测。
4. Dynamic Uncertainty Supervision
现有方法将任意不确定性建模为方差,如下所示: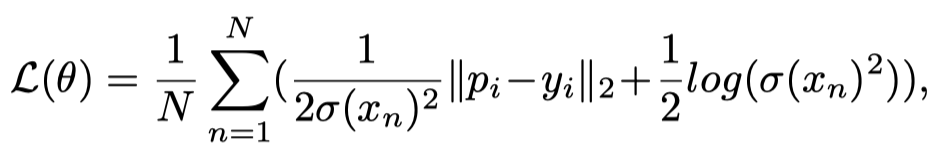
其中,N是训练数据集的大小,xn是具有n个图像索引的输入图像,θ是模型参数集,pi和yi分别是第i个预测和ground truth。采用无界方差来平衡损失。最大限度地减少错误预测的二阶损失,并对其进行正则化,以防止其变得过大。相反,作者使用预测和ground truth之间的差异作为显式监督来模拟任意不确定性。在本文的工作中,它表示以输入图像为条件的预测中的不确定性。
OCENet的动态不确定性监督计算如下: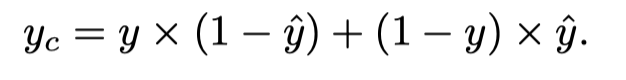
动态不确定性监督yc定义为预测f(x)与其相应ground truth标签y之间的像素级L1距离。这个监督将会那些给模型分类错误但高置信度的像素分配高不确定性。
OCENet使用二进制交叉熵损失进行训练,如下所示: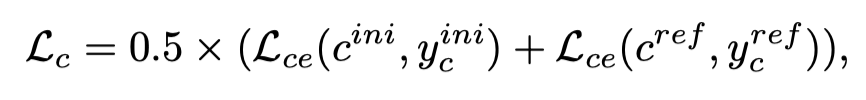
其中,Lce是二进制交叉熵损失,ycini和ycref分别是初始预测和最终预测的动态监督。
5. Uncertainty-Aware Learning
伪装物体检测在整个图像中具有不同的学习困难。与远离伪装对象的背景像素相比,沿对象边界的像素更难区分。此外,伪装前景包含具有不同伪装级别的部分,其中一些部分很容易识别,例如眼睛、嘴巴等,而另一些部分很难区分,例如身体区域与背景具有相似的外观。作者打算通过在CODNet中建模不确定性意识来模拟图像中这种不同的学习困难。具体而言,作者提出训练具有不确定性感知结构损失的伪装目标检测网络,如下所示: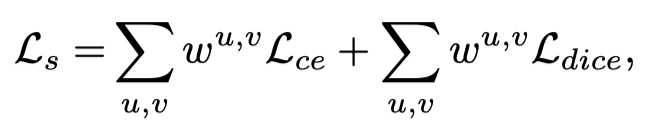
第一项是加权二元交叉熵损失,第二项是加权dice损失。权重项提供了样本特定的像素权重,使CODNet专注于学习不确定像素,尤其是在做出错误预测的情况下。整个算法如下所示。

实验
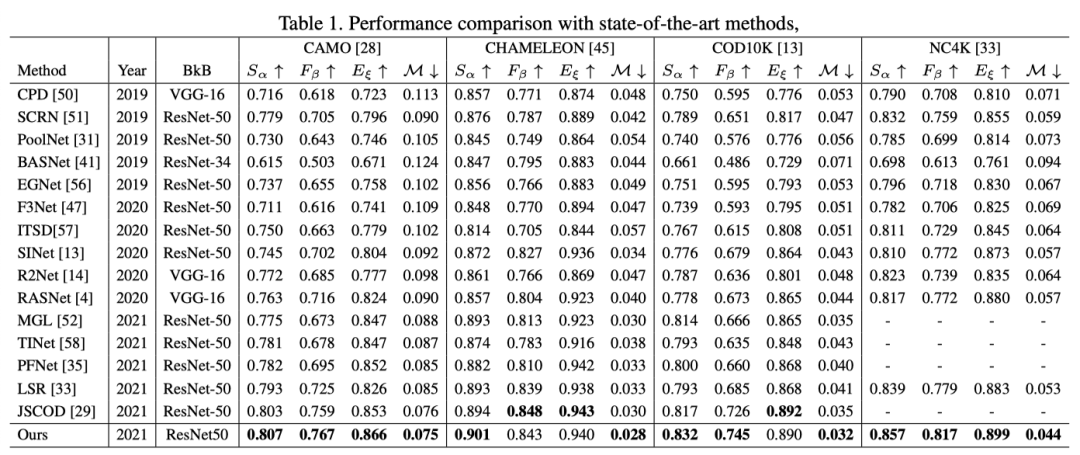
上表中,作者展示了本文方法在四个数据集上的结果,可以看出吗,本文方法能够达到非常好的结果。
作者在上图中展示了本文的方法的预测和比较方法。在第一行和第二行中,以前的方法大多未能恢复蝙蝠鱼和幽灵管鱼的主要结构。相反,本文的方法能够分割出边界更接近ground truth值的更完整的伪装对象。在第三排,以前的方法恢复了蜥蜴的主体,但他们没有找到四肢。相比之下,本文的方法成功地分割了主体和四只脚。
上图比较在动态监督和对抗性学习环境下生成的信任图。从左到右分别是图像、ground truth图、模型预测、对对抗式学习的confidence以及对本文动态监督的confidence。
上图展示了使用估计的置信度图作为预测质量的指标。第一列显示ground truth和图像。从第二列到第五列显示了不同训练阶段的预测和相应的不确定性图。红色表示低置信度,蓝色表示高置信度。t表示训练epoch数。
上表展示了不同超参数λ下的实验结果。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢