

论文地址:https://arxiv.org/pdf/2111.15174.pdf
开源代码:https://github.com/DerrickWang005/CRIS.pytorch
摘要
参考图像分割旨在通过自然语言表达进行分割引用。由于文本和图像之间的独特数据属性,网络可以很好地对齐文本和像素级特征。现有的方法使用预验证的模型来促进学习,但分别从验证的模型中传递了语言/视觉知识,而忽略了多模式的相应信息。受到对比性语言图像预审预后(剪辑)的启发,在本文中,我们提出了一个端到端剪辑式的参考图像分割框架(CRIS)。为了有效地转移多模式知识,CRIS诉诸于视觉解码和对比度学习,以实现文本对像素对齐。更具体地说,我们设计了一个视觉解码器,以传播从文本表示到每个像素级激活的细粒语义信息,从而促进了两种模式之间的一致性。此外,我们提出了文本对像素的对比学习,以明确执行与相关的像素级特征相似的文本功能,并且与无关相似。三个基准数据集的实验结果表明,我们提出的框架在没有任何后处理的情况下显着优于先进的性能。
主要贡献
- 我们提出了一个CLIP驱动的参考图像分割框架(CRIS),以转移剪辑模型的知识,以实现文本对像素对齐。
- 我们通过两种创新设计(即视觉解码器和文本对像素对比度学习)充分利用了这种多模式知识。
- 三个具有挑战性的基准的实验结果大大优于先前的最新方法。

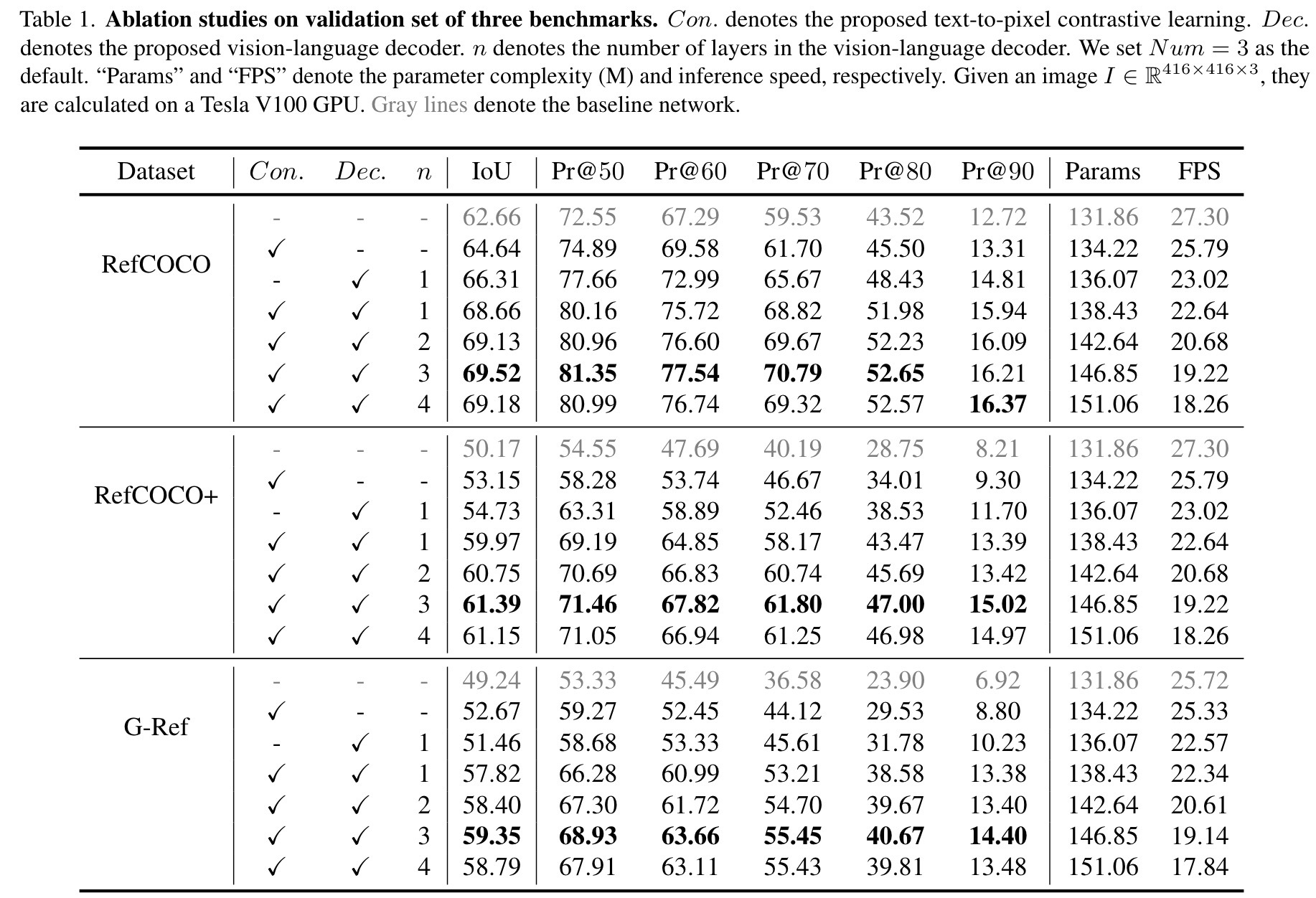
实验
我们提出的框架建立在不同的图像编码器上(例如Resnet-50,Resnet-101 [14]),并与一系列最新方法进行了比较。为了评估我们方法中每个组件的有效性,我们对包括RefCOCO [20],RefCOCO+ [20]和G-Ref [32]在内的三个基准进行了广泛的实验。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢