
文 | 王思若
2018年GPT、BERT预训练模型的提出吹响了大模型“军备竞赛”冲锋的号角,一场大模型的狂欢拉开帷幕,业界强大的算力支撑起例如Megatron-Turing、Switch Transformer、悟道2.0等千亿&万亿参数量模型。与此同时,面对着超大模型训练在内存存储、网络通信、性能功耗等方面的严峻挑战,这同样是一场工程上极致优化的探索之旅,各家公司纷纷提供了自己的解决方案或训练框架,常用的方法有以下几种:
1. 并行化方法: 主要包括数据并行、模型并行和流水线并行,切分数据、Tensor或模型Block到不同GPU上从而达到并行化的效果。之后,Google提出了基于专家并行的MoE架构,通过稀疏结构拓展实现了大模型万亿参数量的飞跃。
2. 内存&通信优化方法: 进一步为了应对并行化方法在内存及通信量上的局限,16年,陈天奇团队提出亚线性内存优化的Checkpointing(重计算)方法,在反向传播时重新计算前向传播的中间激活达到节省显存的目的。21年,微软提出了CPU offload的ZeRO-Offload方案,将梯度、优化器、参数在CPU和GPU间Swapping,通过通信成本来大幅度的节省显存开销。当然,混合精度或者半精度模型训练即采用FP16代替FP32模型参数的量化方法是更加常见有效的方案,大幅度减少内存带宽和存储空间并且提高系统吞吐量,几乎可以成倍提升模型训练速度。
在这场巅峰较量中,Facebook表示:只需更改两行代码,带你体验极致的显存优化,单机即可训练千亿模型,助力贫民玩家实现大模型梦!虽然这里单机至少需要8张RTX 3090, 但未来可期呀!
哇喔~ 请各位抓紧上车并系好安全带,下一站是位于ICLR2022 Spotlight的8-BIT优化器,“一个故事,两行代码,无限显存优化”,祝您路途愉快~
论文题目:
8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION
论文链接:
https://arxiv.org/pdf/2110.02861.pdf
Github:
https://github.com/TimDettmers/bitsandbytes
一、优化器遇到量化的故事
随着Transformer模型不断scale参数,Transformer家族迎来了110亿参数量的T5,1750亿参数量的OPT,1760亿参数量的BLOOM......,这些开源模型给了科研人员更多的可能去进一步探索大模型未知的潜力。但尴尬的是,8张80GB A100依然不足以对T5模型进行微调,显存又双叒叕爆掉了。实际的境况比你想的更加糟糕,仅仅对BLOOM-176B模型进行推理,就需要8张80GB的A100,如果想要进一步的对模型进行微调,至少需要72张!
我们不禁要问,模型训练时是谁占据了大量的显存?
10亿 (1 Billion)参数量的模型使用Adam优化器进行训练,所有数据使用FP32进行存储,模型权重(Model weights)和梯度(Gradients)分别需要4GB存储空间,Adam优化器保存了梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second Moment Estimation,即梯度的未中心化的方差)又分别需要4GB存储空间。Adam优化器占据了50%的显存空间!!!
如何缩减Adam优化器的显存占用无疑成为了重点,微软提出了ZeRO-Offload方案把优化器参数卸载到CPU内存中,那是否还有其他方法呢?使用半精度或者INT8来代替全精度数据类型去存储参数?实际上,一种称为量化的方法已经广泛应用于深度学习中。
那么,下一个问题,什么是量化?
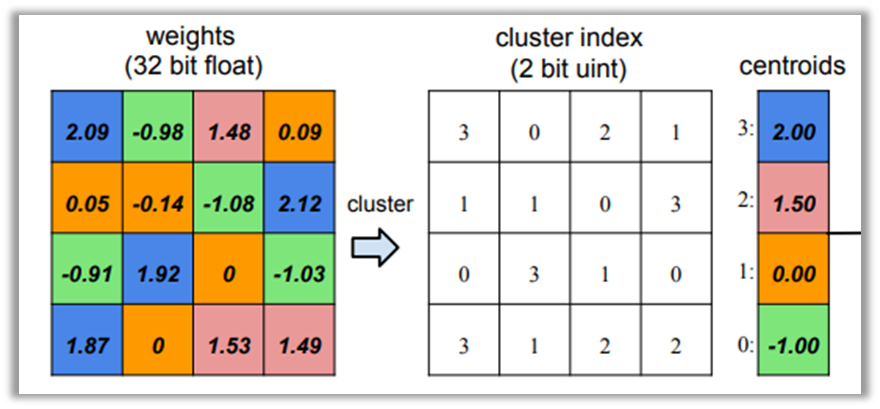
量化: 通俗理解就是将权值参数或中间激活值用更少位数的数据类型近似表示FP32浮点型数据。16年Deep Compression论文中首次提出参数量化方法,使用K-means聚类方法将参数矩阵进行聚类,使用聚类中心来代替原值,模型只需存储聚类的index和聚类中心centroid,从而达到压缩参数的目的,一般来讲为了更好的聚类首先会将参数归一化到某个区间范围,让不同张量值的量级保持一致。
这是量化操作的一种方案,反过来从量化数值转化为原始数值的过程称为反量化,量化可以有效降低内存消耗和计算强度但也带来了严重的精度损失问题。
当优化器遇到了量化,思路很简单,但是优化很难,FP16优化器已经很不稳定,但Facebook直接使用INT8优化器,直接减少38%的显存占用,需要更少的模型训练时间,但拥有和FP32优化器完全相当的效果。
二、三个方法构建无损INT8优化器
INT8优化器会以低精度的状态存储在显存中,在参数更新时会反量化为FP16的高精度状态,从而既能够高精度的更新参数,也可以尽可能缩减存储空间,如下图所示。为了构建无损INT8优化器,作者提出了逐块量化和动态量化的量化策略,以及稳定化词嵌入层的方法。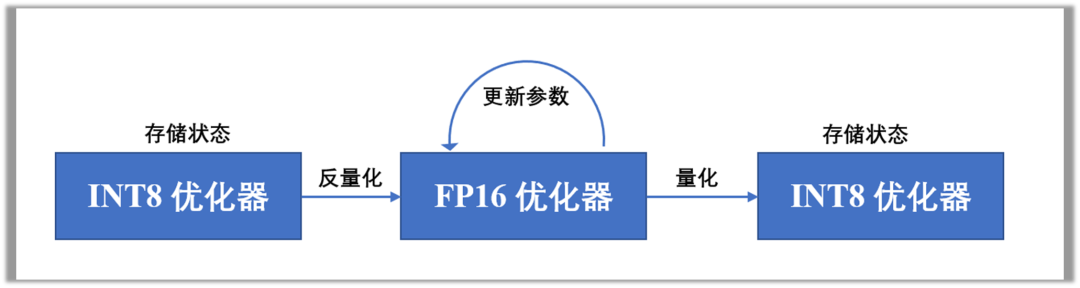
逐块量化 Block-wise Quantization
量化的第一步需要将张量归一到[-1,1]范围内,常见的归一化需要将整个张量的缩减,但这样多GPU核心同步会带来一定的通信消耗。块级动态量化将输入张量划分为2048大小的块来降低这个代价,每个块归一化可以独立的计算,不需要在核心之间同步,提供了吞吐量。此外,它对输入张量中的异常值也有更强的鲁棒性,在逐块量化中,异常值的影响被限制在单个块上。因此,大多数比特在其他块中被有效地使用,保证了量化的鲁棒性和精确性。
动态量化 Dynamic Quantization
首先简绍一下动态树量化,动态树量化包括四部分:(1) 符号位Sign;(2)指数Exponent,使用0的数量表示指数大小;(3)标志位,表明后面是线性量化的数值;(4)线性数值。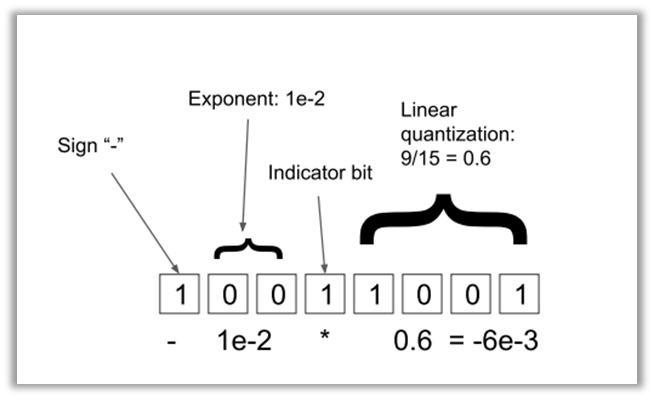
与固定指数和分数的数据类型不同,动态树量化可以通过移动标志位,随每个数字动态变化指数和分数的范围,从而保留更多小数位的信息。动态量化实际上就是动态树量化在优化器场景下的拓展,优化器二阶矩估计恒为正,不需要符号位,因此将符号位重新利用来拓展线性数值的表达范围。
稳定的词嵌入层 Stable Embedding Layer
词嵌入层(embedding layer)经常在模型训练的时候发生梯度溢出的情况,从而让模型不能稳定训练。稳定的词嵌入层方法通过Xavier uniform进行参数初始化并在Embedding Layer后加上层归一化操作,保证张量大致为1的方差,并且均匀分布初始化相对于正态分布初始化避免了极值的出现,保证梯度不会溢出,极大地提高了训练稳定性。
三、效果
作者在机器翻译、基于RoBERTa模型的文本预训练及其在GLUE任务上微调、图像预训练和分类任务上比较了8位优化器和32位优化器的性能表现,效果如下图所示: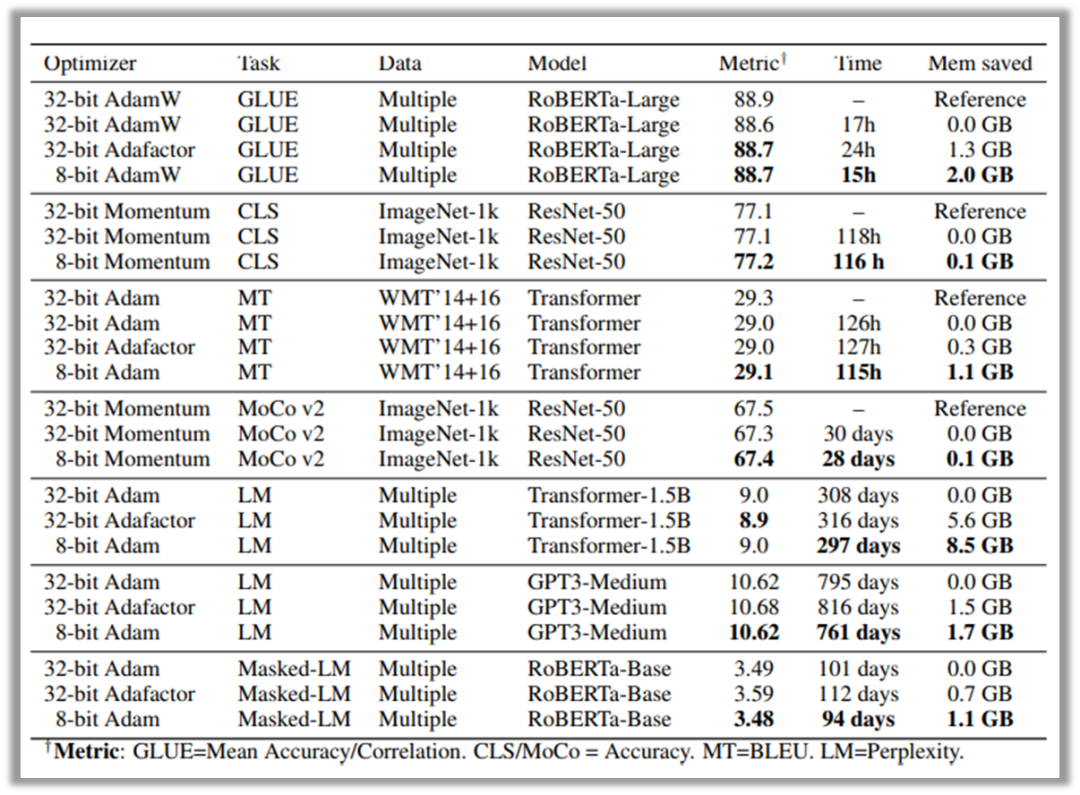
8位优化器在包括翻译、文本理解和图像的7个基准数据集上相对于32位优化器均有相当甚至更优的性能指标,此外,8位优化器极大减少了内存消耗并在一定程度上提升了模型的训练速度。
此外,作者进一步通过基于模型预训练的消融实验验证了动态量化、逐块量化和稳定词嵌入层三种方法对模型效果的影响,如下图所示: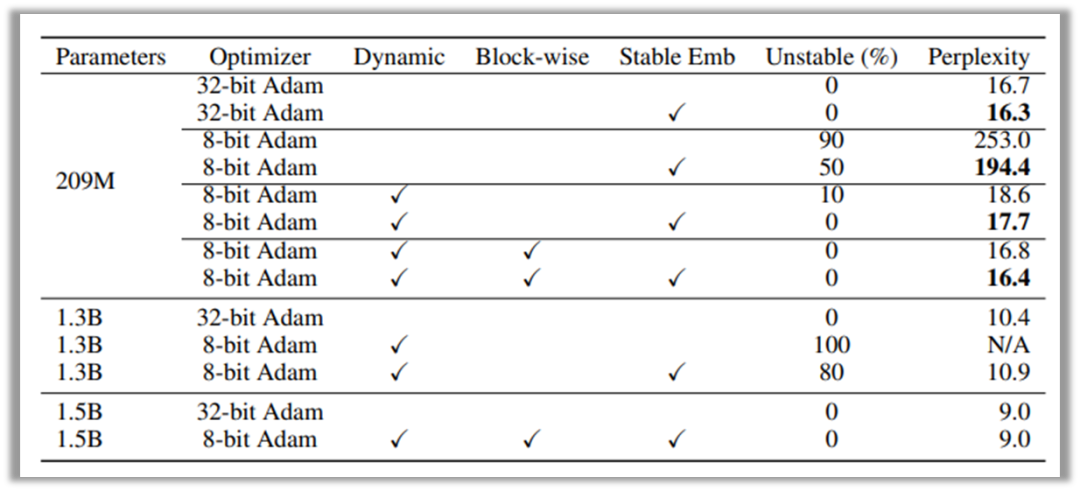
我们可以看到动态量化对整体稳定性至关重要,缺少动态量化会导致模型不能正常收敛;逐块量化对更大规模模型的训练稳定性产生了更为关键的作用;稳定的词嵌入层对8位和32位优化器都是有用的,在一定程度上提高了稳定性。
总结
8位优化器减少了内存占用,并在广泛的任务上实现了加速优化。目前Facebook提供了bitsandbytes库,两行代码即可调用8位优化器,一键实现广大“贫民”炼丹玩家小显存玩转大模型的梦,大家赶快动手试试吧~
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群
[1] 8-BIT OPTIMIZERS VIA BLOCK-WISE QUANTIZATION https://arxiv.org/pdf/2110.02861.pdf
[2] bitsandbytes库 https://github.com/TimDettmers/bitsandbytes

内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢