
近期,微软亚洲研究院联合微软图灵团队推出了最新升级的 BEiT-3 预训练模型,在广泛的视觉及视觉-语言任务上,包括目标检测(COCO)、实例分割(COCO)、语义分割(ADE20K)、图像分类(ImageNet)、视觉推理(NLVR2)、视觉问答(VQAv2)、图片描述生成(COCO)和跨模态检索(Flickr30K,COCO)等,实现了 SOTA 的迁移性能。BEiT-3 创新的设计和出色的表现为多模态研究打开了新思路,也预示着 AI 大一统渐露曙光。(查看 BEiT-3 论文)
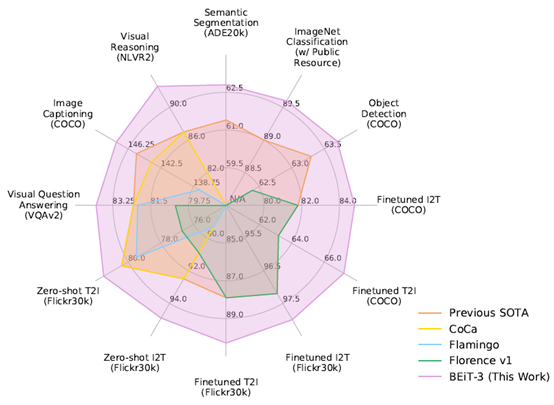
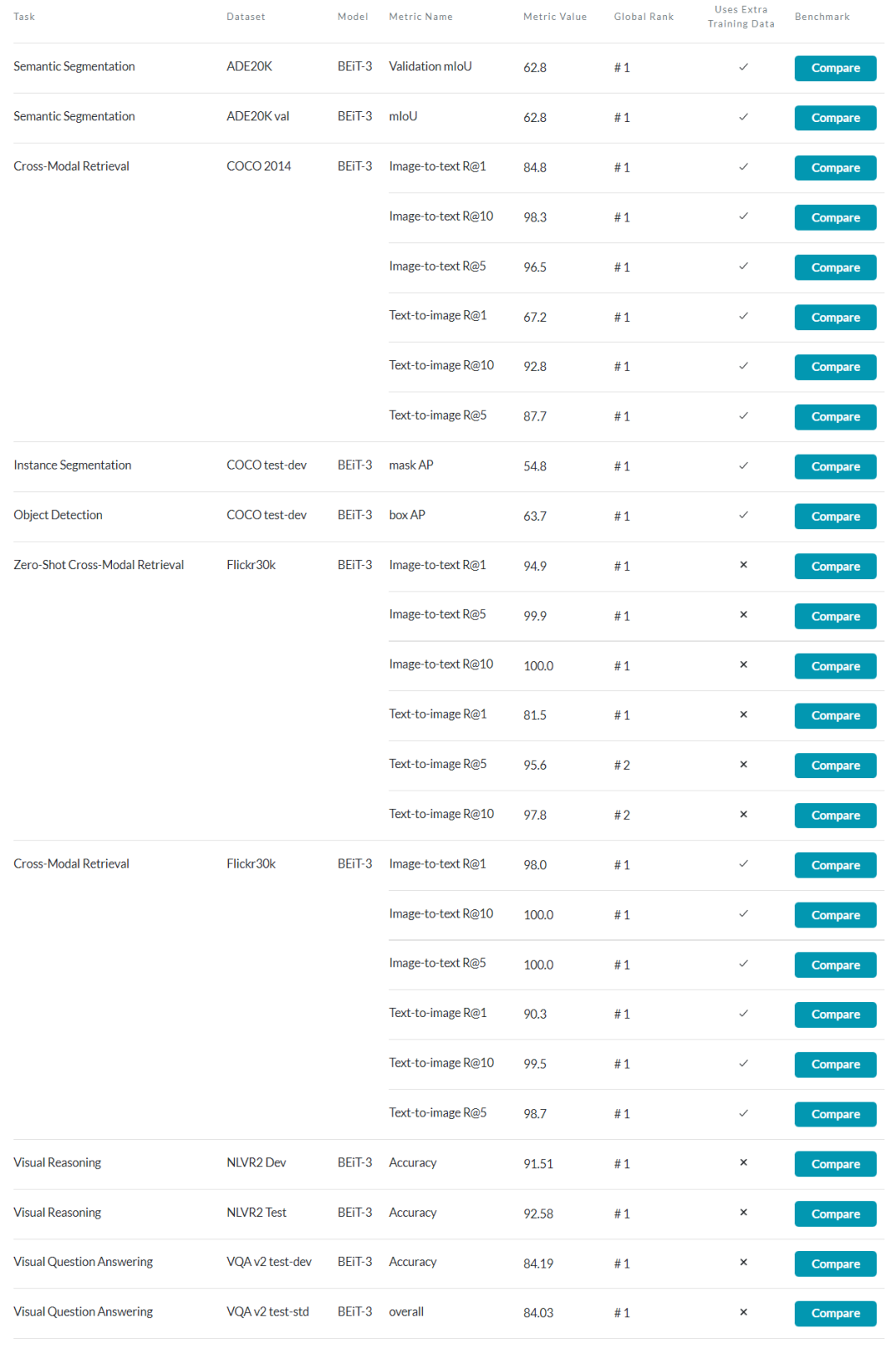
图1:截至2022年8月,BEiT-3 在广泛的视觉及视觉-语言任务上都实现了 SOTA 的迁移性能
事实上,在早期对于 AI 和深度学习算法的探索中,科研人员都是专注于研究单模态模型,并利用单一模态数据来训练模型。例如,基于文本数据训练自然语言处理(NLP)模型,基于图像数据训练计算机视觉 (CV) 模型,使用音频数据训练语音模型等等。然而,在现实世界中,文本、图像、语音、视频等形式很多情况下都不是独立存在的,而是以更复杂的方式融合呈现,因此在人工智能的探索中,跨模态、多模态也成了近几年业界研究的重点。
大规模预训练正在趋向“大一统”
“近年来,语言、视觉和多模态等领域的预训练开始呈现大一统(big convergence)趋势。通过对大量数据的大规模预训练,我们可以更轻松地将模型迁移到多种下游任务上。这种预训练一个通用基础模型来处理多种下游任务的模式已经吸引了越来越多科研人员的关注,”微软亚洲研究院自然语言计算组主管研究员董力表示。微软亚洲研究院看到,大一统的趋势已经在三个方面逐渐显现,分别是骨干网络(backbone)、预训练任务和规模提升。
首先,骨干网络逐渐统一。模型架构的统一,为预训练的大一统提供了基础。在这个思想指引下,微软亚洲研究院提出了一个统一的骨干网络 Multiway Transformer,可以同时编码多种模态。此外,通过模块化的设计,统一架构可以用于不同的视觉及视觉-语言下游任务。受到 UniLM(统一预训练语言模型)的启发,理解和生成任务也可以进行统一建模。
其次,基于掩码数据建模(masked data modeling)的预训练已成功应用于多种模态,如文本和图像。微软亚洲研究院的研究员们将图像看作一种语言,实现了以相同的方式处理文本和图像两种模态任务的目的。自此,图像-文本对可以被用作“平行句子”来学习模态之间的对齐。通过数据的归一化处理,还可以利用生成式预训练来统一地进行大规模表示学习。BEiT-3 在视觉、视觉-语言任务上达到 SOTA 性能也证明了生成式预训练的优越性。
第三,扩大模型规模和数据大小可提高基础模型的泛化能力,从而提升模型的下游迁移能力。遵循这一理念,科研人员逐渐将模型规模扩大到了数十亿个参数,例如在 NLP 领域,Megatron-Turing NLG 模型有5300亿参数,这些大模型在语言理解、语言生成等任务上都取得了更好的成效;在 CV 领域,Swin Transformer v2.0具有30亿参数,并在多个基准上刷新了纪录,证明了视觉大模型在广泛视觉任务中的优势。再加之,微软亚洲研究院提出了将图像视为一种语言的方式,可直接复用已有的大规模语言模型的预训练方法,从而更有利于视觉基础模型的扩大。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢