
作者:Shubham Toshniwal
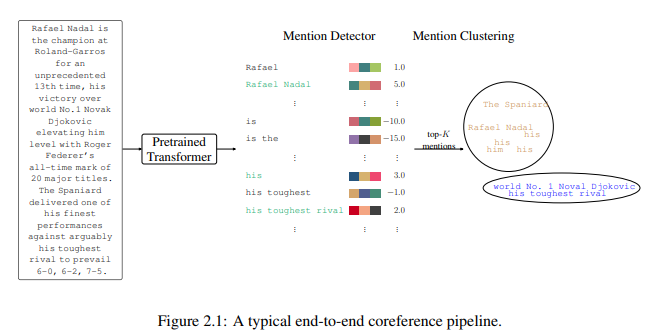
简介:本文研究在长文档与语言模型中集成实体跟踪。自然语言模型需要什么才能理解小说(如《指环王》)?除其他外,这种模型必须能够:(1)识别和记录文本中引入的新字符(实体)及其属性,以及(2)识别先前引入的字符的后续引用并更新其属性。实体跟踪问题对于语言理解至关重要,因此对于自然语言处理中的广泛下游应用(如问答、摘要)非常有用。
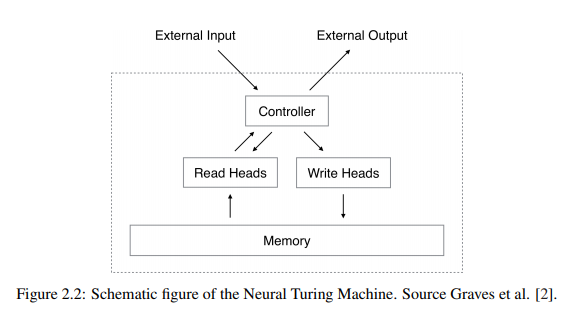
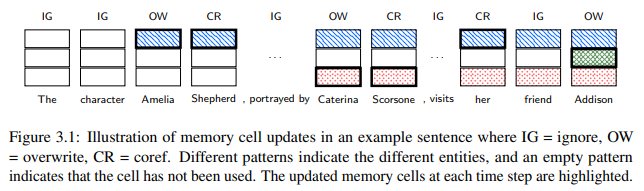
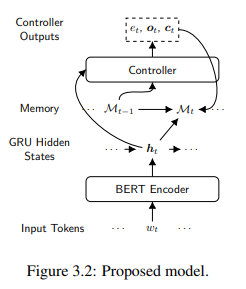
在本论文中,作者关注两个与促进实体跟踪模型的使用相关的关键问题:(1)将实体跟踪模型扩展到长文档 ,以及(2)将实体追踪集成到语言模型中。将语言技术应用于长文档最近引起了人们的兴趣,但计算约束是扩展当前方法的一个重要瓶颈。在这篇论文中,作者认为计算效率高的实体跟踪模型可以通过使用从预训练语言模型导出的丰富的固定维向量表示来表示实体,并利用实体的短暂性质来开发。作者还主张将实体跟踪集成到语言模型中,因为这将允许:(i)考虑到当前在NLP应用中普遍使用预训练语言模型,更广泛的应用,以及(ii)更容易采用,因为在新的预训练语言模型中交换比集成单独的独立实体跟踪模型容易得多。
论文下载:https://arxiv.org/pdf/2208.14252.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢