
作者:Shahriar Golchin, Mihai Surdeanu, Nazgol Tavabi, 等
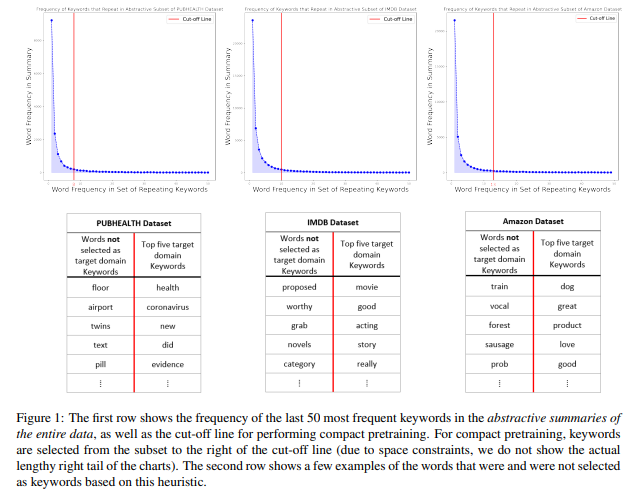
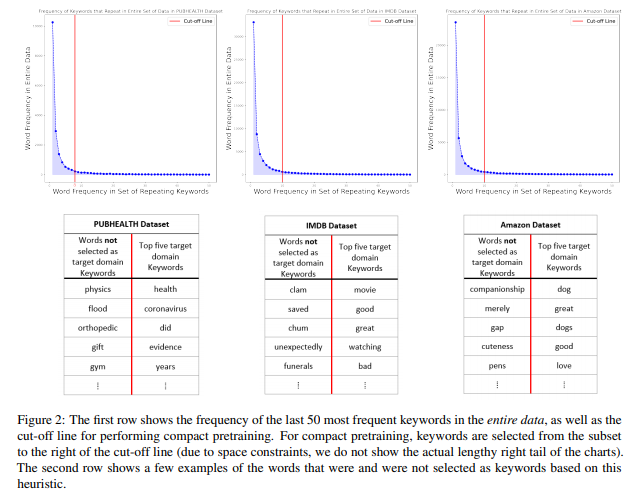
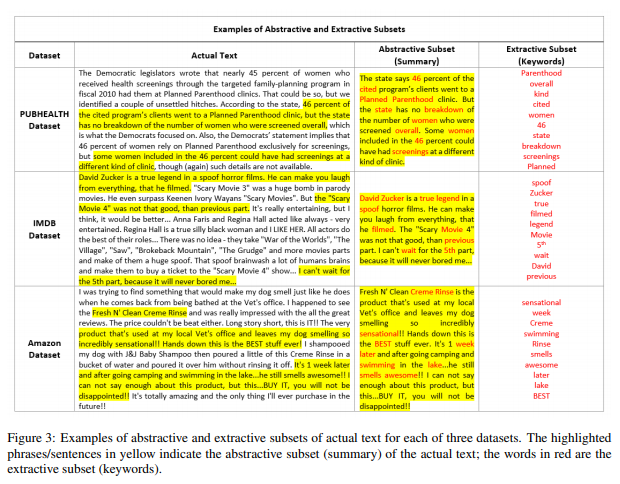
简介:本文研究通过紧凑预训练方法以降低训练成本。大型神经语言模型(NLM)的领域自适应与预训练阶段的大量非结构化数据相结合。然而,在本研究中,作者表明:预训练的NLM从集中于域中关键信息的数据的紧凑子集中更有效、更快地学习域内信息。作者使用抽象摘要和提取关键字的组合从非结构化数据中构造这些紧凑子集。特别是,作者依赖BART生成抽象摘要,而KeyBERT从这些摘要(或直接从原始非结构化文本)中提取关键词。作者使用六种不同的设置来评估其方法:三个数据集结合两个不同的NLM。实验结果表明,在使用作者的方法进行预训练的NLMs之上训练的任务特定分类器优于基于传统预训练的方法,即对整个数据进行随机掩蔽、以及不进行预训练。此外,作者还表明与vanilla 预训练相比,作者的策略将预训练时间缩短了五倍。
论文下载:https://arxiv.org/pdf/2208.12367.pdf
代码下载:https://github.com/shahriargolchin/compact-pretraining
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢