
作者:Fan Hu, Yanlin Wang, Lun Du,等
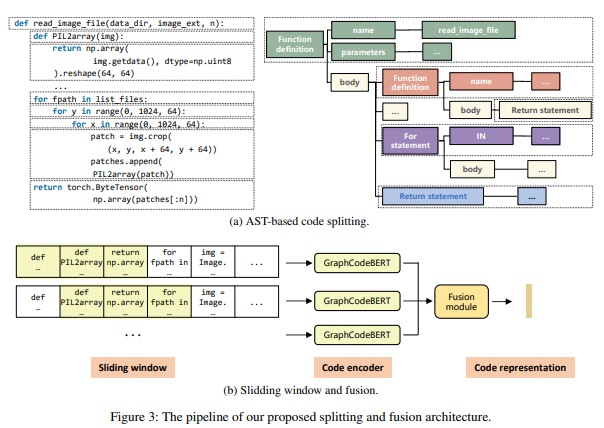
简介:本文研究当前预训练模型无法解决长代码的议题。由于基于transformer的预训练模型,代码搜索的性能得到了显著提高。然而,由于多头自注意力和GPU内存的限制,输入令牌长度有限制。现有的预训练代码模型(如GraphCodeBERT、CodeBERT、和RoBERTaCode),默认采用前256个令牌,这使得它们无法表示长代码(即大于256个令牌的代码)的完整信息。与可被视为具有完整语义的整体的长文本文档不同,长代码的语义是不连续的,因为一段长代码可能包含不同的代码模块。因此,将长文本处理方法直接应用于长代码是不合理的。为了解决长代码问题,作者提出了MLCS(为代码搜索建模长代码),以获得长代码的更好表示。作者的实验结果表明了MLC对于长代码检索的有效性。对于MLC,作者可以使用基于transformer的预训练模型来建模长代码,而不改变其内部结构和重新预训练。通过基于AST的分割和基于注意力的融合方法,MLCS实现了0.785的总体平均倒数排名(MRR)分数,优于公共CodeSearchNet基准上先前0.713的最新结果。
论文下载:https://arxiv.org/pdf/2208.11271.pdf
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢