
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于大型语言模型的事实推理、基于专家系统和神经网络用曲式生成旋律、语言无关的多语言流式设备端ASR系统、不完全矩阵补全、强化学习无监督表示的轻量探测、基于自适应跨度Transformer的免检测器图像匹配、用扩散模型从2D显微镜图像预测3D形状、基于深度的鲁棒高效自主微型无人机避障、基于Hessian方向的高维损失景观可视化
1、[CL] Faithful Reasoning Using Large Language Models
A Creswell, M Shanahan
[DeepMind]
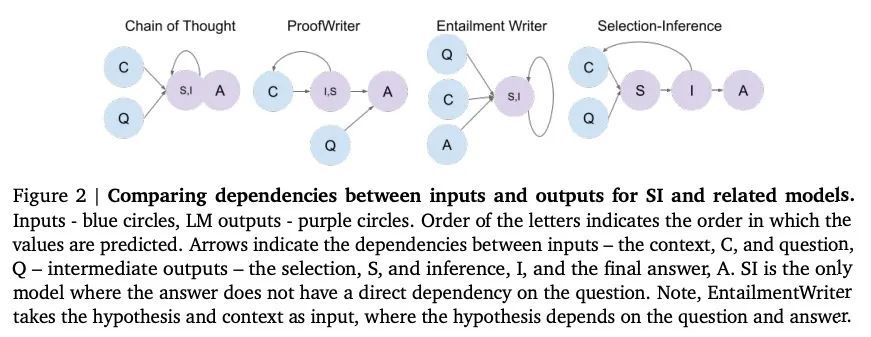
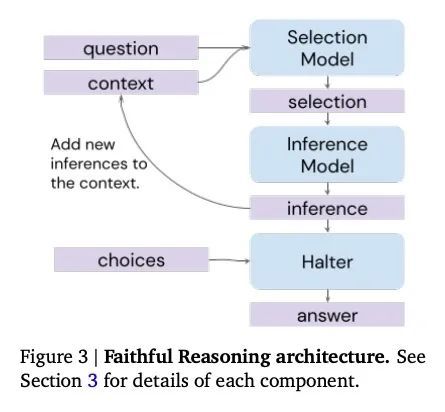
基于大型语言模型的事实推理。尽管当代大型语言模型(LM)展示了令人印象深刻的问题回答能力,但它们的答案通常是对模型的单一调用的产物。这带来了不受欢迎的不透明性,并影响了性能,特别是在固有的多步的问题上。为解决这些限制,本文展示了如何使LM通过一种因果结构反映问题的基本逻辑结构过程来进行忠实的多步推理。将推理步骤串联起来,每一步都调用两个微调的语言模型,一个用于选择,一个用于推理,以产生有效的推理轨迹。所提出的方法通过推理轨迹空间进行波束搜索,以提高推理质量。实验证明了该模型在多步逻辑推理和科学问答上的有效性,表明它在最终答案的准确性上优于基线,并且产生了人类可解释的推理轨迹,其有效性可由用户进行审查。
Although contemporary large languagemodels (LMs) demonstrate impressive question-answering capabilities, their answers are typically the product of a single call to the model. This entails an unwelcome degree of opacity and compromises performance, especially on problems that are inherently multi-step. To address these limitations, we show how LMs can bemade to perform faithfulmulti-step reasoning via a process whose causal structure mirrors the underlying logical structure of the problem. Our approach works by chaining together reasoning steps, where each step results from calls to two fine-tuned LMs, one for selection and one for inference, to produce a valid reasoning trace. Our method carries out a beam search through the space of reasoning traces to improve reasoning quality. We demonstrate the effectiveness of our model on multi-step logical deduction and scientific question-answering, showing that it outperforms baselines on final answer accuracy, and generates humanly interpretable reasoning traces whose validity can be checked by the user.
https://arxiv.org/abs/2208.14271


2、[AS] MeloForm: Generating Melody with Musical Form based on Expert Systems and Neural Networks
P Lu, X Tan, B Yu, T Qin, S Zhao, T Liu
[Microsoft Research Asia & Nanjing University & Microsoft Azure Speech]
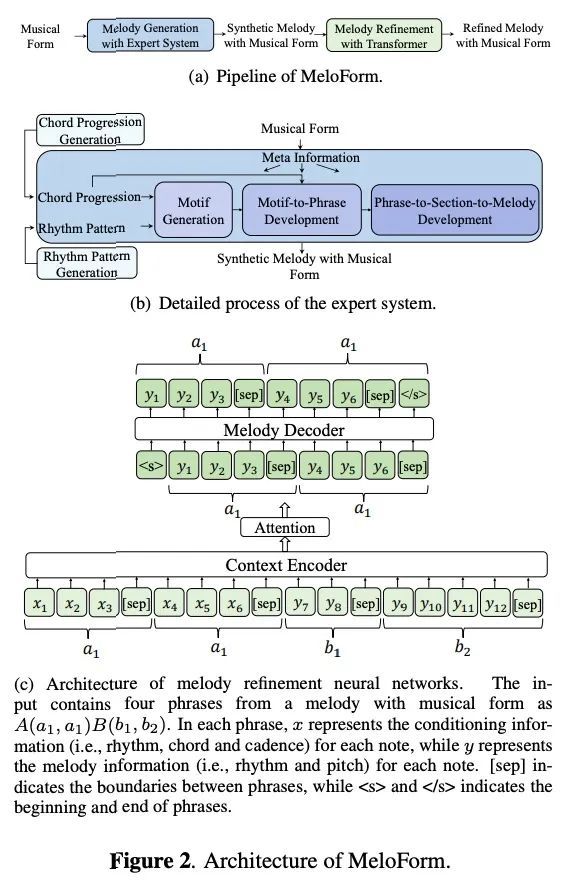
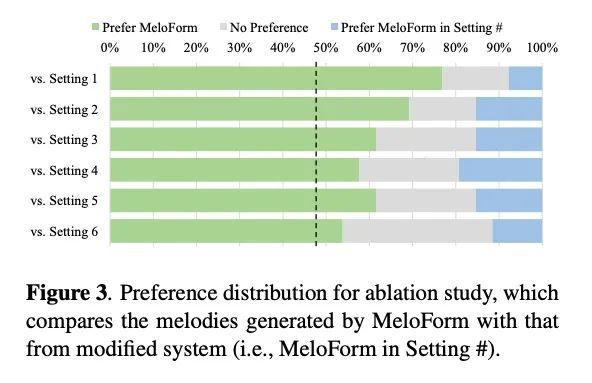
MELOFORM: 基于专家系统和神经网络用曲式生成旋律。人往往通过根据曲式组织元素来表达音乐理念的方式创作音乐。然而,对基于神经网络的音乐生成,由于缺乏关于曲式的标记数据,很难做到这一点。本文开发了MeloForm,一种用专家系统和神经网络生成具有曲式的旋律的系统。具体来说,1)设计了一个专家系统,根据预先给定的曲式,通过发展音乐元素,从主题到短语再到带有重复和变化的部分来生成旋律;2)考虑到生成的旋律缺乏音乐的丰富性,设计了一种基于Transformer的细化模型,在不改变其曲式的情况下改进旋律。MeloForm享有专家系统精确控制曲式和通过神经模型学习音乐丰富性的优势。主观和客观实验评估表明,MeloForm生成的旋律具有精确的曲式控制,准确率为97.79%,并且在结构、主题、丰富性和整体质量方面的主观评价得分,分别比基线系统高出0.75、0.50、0.86和0.89,不需要任何标记的曲式数据。此外,MeloForm可以支持各种形式,如诗句和合唱形式、轮唱形式、变奏形式、奏鸣曲形式等。
Human usually composes music by organizing elements according to the musical form to express music ideas. However, for neural network-based music generation, it is difficult to do so due to the lack of labelled data on musical form. In this paper, we develop MeloForm, a system that generates melody with musical form using expert systems and neural networks. Specifically, 1) we design an expert system to generate a melody by developing musical elements from motifs to phrases then to sections with repetitions and variations according to pre-given musical form; 2) considering the generated melody is lack of musical richness, we design a Transformer based refinement model to improve the melody without changing its musical form. MeloForm enjoys the advantages of precise musical form control by expert systems and musical richness learning via neural models. Both subjective and objective experimental evaluations demonstrate that MeloForm generates melodies with precise musical form control with 97.79% accuracy, and outperforms baseline systems in terms of subjective evaluation score by 0.75, 0.50, 0.86 and 0.89 in structure, thematic, richness and overall quality, without any labelled musical form data. Besides, MeloForm can support various kinds of forms, such as verse and chorus form, rondo form, variational form, sonata form, etc. Music samples generated by MeloForm are available via this link, and our code is available via this link.
https://arxiv.org/abs/2208.14345


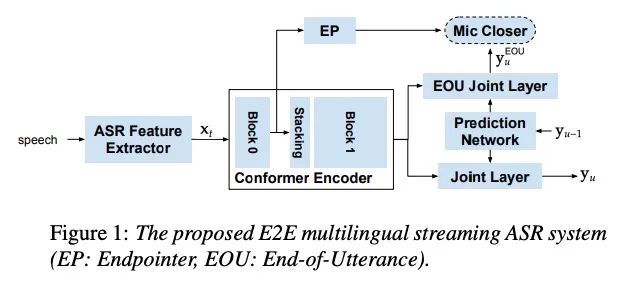
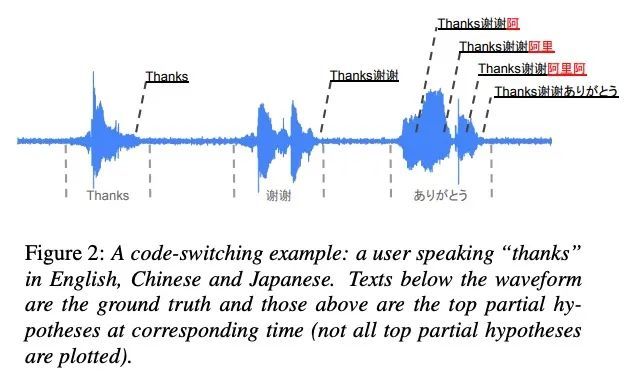
3、[AS] A Language Agnostic Multilingual Streaming On-Device ASR System
B Li, T N. Sainath, R Pang, S Chang, Q Xu, T Strohman, V Chen, Q Liang, H Liu, Y He, P Haghani, S Bidichandani
[Google LLC]
语言无关的多语言流式设备端ASR系统。设备上的端到端(E2E)模型在质量和延迟方面都比传统模型在英语语音搜索任务中有所改进。E2E模型在多语言自动语音识别(ASR)方面也显示出很好的效果。本文将之前的容量解决方案扩展到流式应用,并提出了一种流式多语言E2E ASR系统,该系统完全在设备端运行,其质量和延迟与单个单语言模型相当。为实现这一目标,本文提出一种编码器Endpointer模型和一种End-of-Utterance(EOU)联合层,以实现更好的质量和延迟权衡。该系统是以一种与语言无关的方式建立的,使其能够自然地支持实时的内部代码切换。为了解决大型模型的可行性问题,在设备上进行了分析,并用最近开发的嵌入解码器取代了耗时的LSTM解码器。通过这些改变,成功地在移动设备上运行了这样一个系统,达到了超实时的处理速度。
On-device end-to-end (E2E) models have shown improvements over a conventional model on English Voice Search tasks in both quality and latency. E2E models have also shown promising results for multilingual automatic speech recognition (ASR). In this paper, we extend our previous capacity solution to streaming applications and present a streaming multilingual E2E ASR system that runs fully on device with comparable quality and latency to individual monolingual models. To achieve that, we propose an Encoder Endpointer model and an End-of-Utterance (EOU) Joint Layer for a better quality and latency trade-off. Our system is built in a language agnostic manner allowing it to natively support intersentential code switching in real time. To address the feasibility concerns on large models, we conducted on-device profiling and replaced the time consuming LSTM decoder with the recently developed Embedding decoder. With these changes, we managed to run such a system on a mobile device in less than real time.
https://arxiv.org/abs/2208.13916

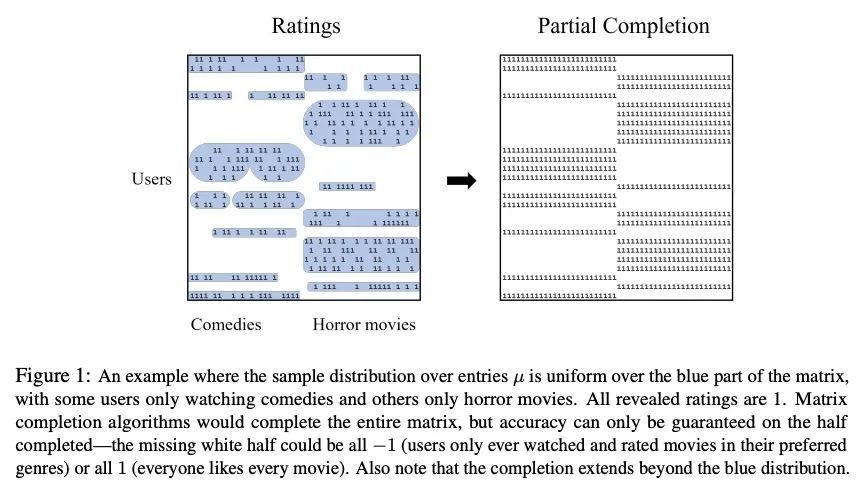
4、[LG] Partial Matrix Completion
V Kanade, E Hazan, A T Kalai
[University of Oxford & Princeton University & Microsoft Research]
不完全矩阵补全。在矩阵补全问题中,人们希望根据一组被揭示的(可能是包含噪声的)条目来重建一个低秩矩阵。之前的工作考虑补全整个矩阵,在条目分布不均匀的常见情况下,这可能是非常不准确的。本文将不完全矩阵补全问题规范化,其目标是完成一个大的条目子集,或者说补全整个矩阵并指定一个准确的条目子集。有趣的是,即使分布是未知的和任意复杂的,所提出的高效算法也能保证:(a)在所有补全的条目上有很高的准确性,和(b)高覆盖率,这意味着它覆盖的矩阵至少与观察到的分布一样多。
In the matrix completion problem, one wishes to reconstruct a low-rank matrix based on a revealed set of (possibly noisy) entries. Prior work considers completing the entire matrix, which may be highly inaccurate in the common case where the distribution over entries is non-uniform. We formalize the problem of Partial Matrix Completion where the goal is to complete a large subset of the entries, or equivalently to complete the entire matrix and specify an accurate subset of the entries. Interestingly, even though the distribution is unknown and arbitrarily complex, our efficient algorithm is able to guarantee: (a) high accuracy over all completed entries, and (b) high coverage, meaning that it covers at least as much of the matrix as the distribution of observations.
https://arxiv.org/abs/2208.12063

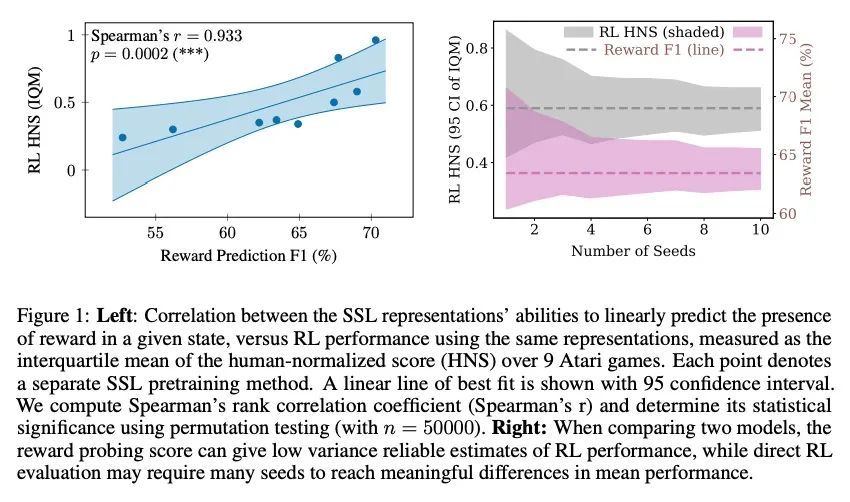
5、[LG] Light-weight probing of unsupervised representations for Reinforcement Learning
W Zhang, A GX-Chen, V Sobal, Y LeCun, N Carion
[AssemblyAI & New York University & Facebook AI Research]
强化学习无监督表示的轻量探测。无监督视觉表示学习提供了一个机会,可以利用大型的无标签轨迹体来形成有用的视觉表示,可有利于强化学习(RL)算法的训练。然而,评估这种表示的适用性需要训练强化学习算法,这在计算上是很稠密的,而且结果差异很大。为缓解该问题,本文设计了一种无监督强化学习表示的评估协议,其方差较低,计算成本降低了600倍。受视觉界启发,本文提出了两种线性探测任务:预测在特定状态下观察到的奖励,以及预测专家在特定状态下的行动。这两个任务普遍适用于许多强化学习领域,本文通过严格的实验表明,它们与Atari100k基准上的实际下游控制性能密切相关。这为探索预训练算法空间提供了一种更好的方法,而不需要为每一种设置运行强化学习评估。利用该框架,本文进一步改进了现有的自监督学习(SSL)强化学习的方案,强调了前向模型的重要性,视觉骨干的大小,以及无监督目标的精确表述。
Unsupervised visual representation learning offers the opportunity to leverage large corpora of unlabeled trajectories to form useful visual representations, which can benefit the training of reinforcement learning (RL) algorithms. However, evaluating the fitness of such representations requires training RL algorithms which is computationally intensive and has high variance outcomes. To alleviate this issue, we design an evaluation protocol for unsupervised RL representations with lower variance and up to 600x lower computational cost. Inspired by the vision community, we propose two linear probing tasks: predicting the reward observed in a given state, and predicting the action of an expert in a given state. These two tasks are generally applicable to many RL domains, and we show through rigorous experimentation that they correlate strongly with the actual downstream control performance on the Atari100k Benchmark. This provides a better method for exploring the space of pretraining algorithms without the need of running RL evaluations for every setting. Leveraging this framework, we further improve existing self-supervised learning (SSL) recipes for RL, highlighting the importance of the forward model, the size of the visual backbone, and the precise formulation of the unsupervised objective. Code is available at https://github.com/kevinghst/lightweight_rl_probe.
https://arxiv.org/abs/2208.12345


另外几篇值得关注的论文:
[CV] ASpanFormer: Detector-Free Image Matching with Adaptive Span Transformer
ASpanFormer:基于自适应跨度Transformer的免检测器图像匹配
H Chen, Z Luo, L Zhou, Y Tian, M Zhen, T Fang, D Mckinnon, Y Tsin, L Quan
[HKUST & Apple]
https://arxiv.org/abs/2208.14201


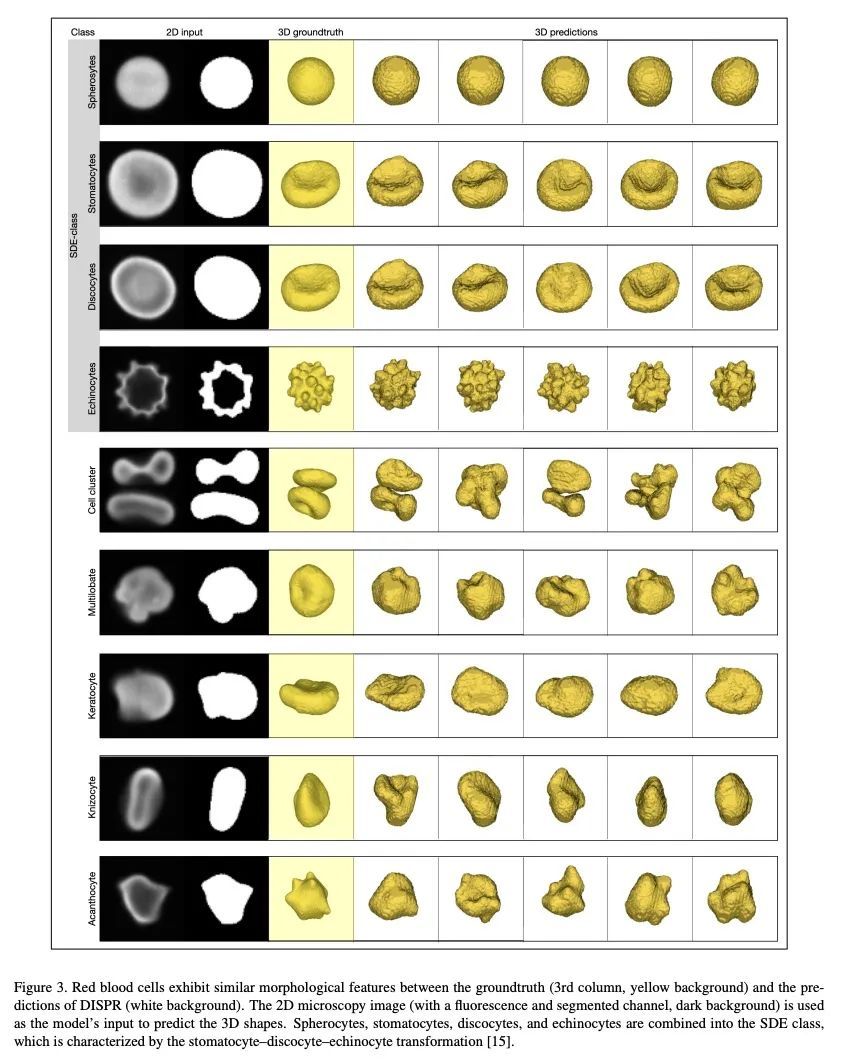
[CV] A Diffusion Model Predicts 3D Shapes from 2D Microscopy Images
用扩散模型从2D显微镜图像预测3D形状
D J. E. Waibel, E Röoell, B Rieck, R Giryes, C Marr
[Helmholtz Munich – German Research Centre for Environmental Health & Tel Aviv University]
https://arxiv.org/abs/2208.14125



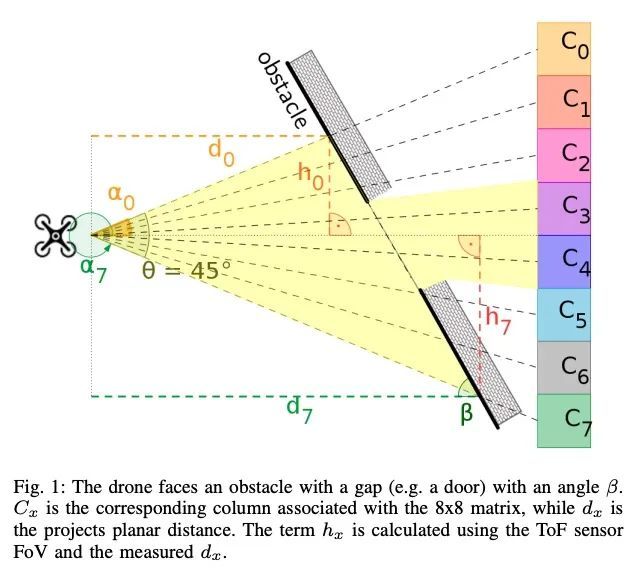
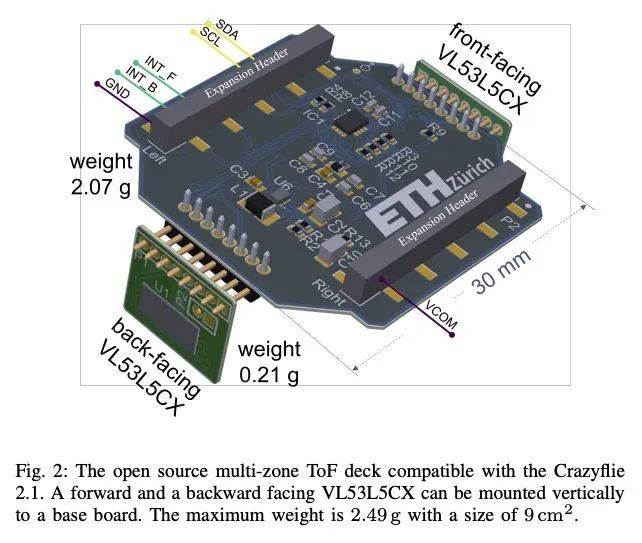
[RO] Robust and Efficient Depth-based Obstacle Avoidance for Autonomous Miniaturized UAVs
基于深度的鲁棒高效自主微型无人机避障
H Müller, V Niculescu, T Polonelli, M Magno, L Benini https://arxiv.org/abs/2208.12624


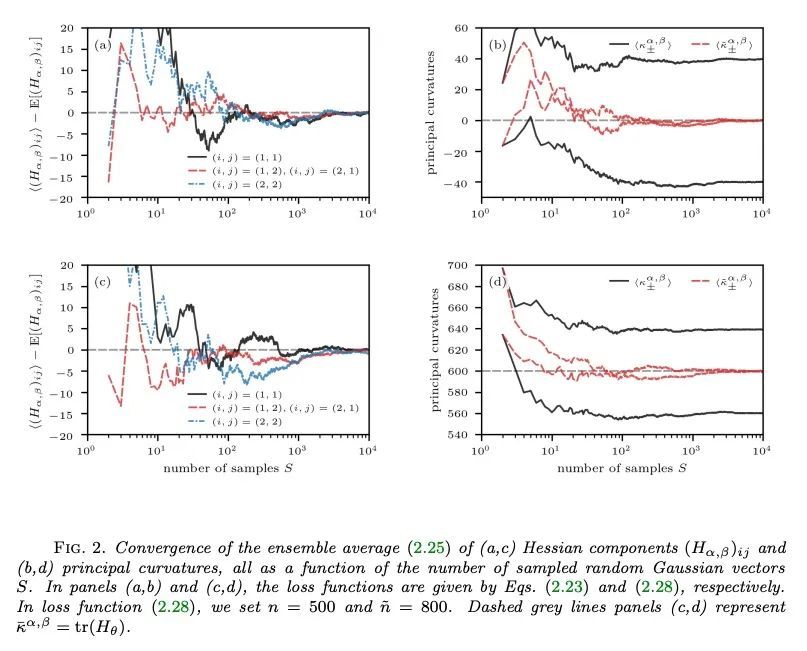
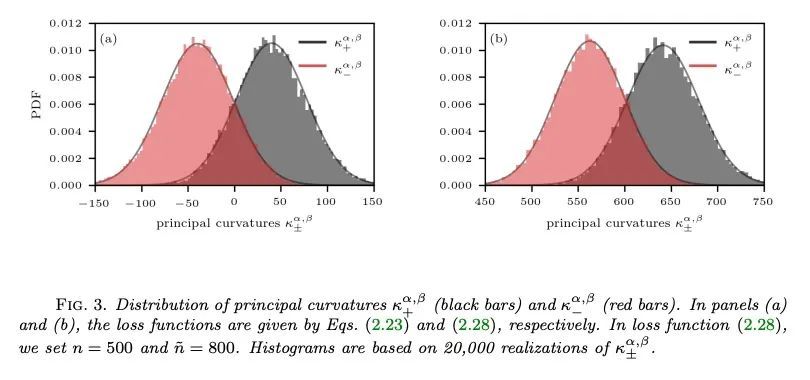
[LG] Visualizing high-dimensional loss landscapes with Hessian directions
基于Hessian方向的高维损失景观可视化
L Böttcher, G Wheeler
[Frankfurt School of Finance and Management]
https://arxiv.org/abs/2208.13219


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢