
卷友们好,我是rumor。
就在一个月前,我还很疑惑为什么大厂们都要去卷文本生成图像,当时自己总结了两个有价值的落地点(美术教育和内容生成),但始终不太exciting,感觉现在的技术离目标还有不少距离。
结果才短短一个月,我的认知就被革新了。
在过去的一两周里,我的twitter每天都在被Diffusion刷屏,各种玩法层出不穷。如果这样描述你没有感觉,那你可以打开这个网站,来看看过去一周内Diffusion相关的新项目列表:
https://multimodal.art/news/1-week-of-stable-diffusion
我数了一下,非完全统计一共24个,平均每天就有3+个Diffusion的项目,仿佛是一个新的大航海时代。
Stable Diffusion
这次火爆的源起,是慕尼黑大学的CompVis组,联合Stability AI[1]和Runway[2]发布了他们预训练的Diffusion生成模型[3]。
不就开源了一个模型吗?有啥呢?
首先,它开源。 别看OpenAI的DALLE2和Google的Imagen效果都那么好,可他们都是半开不开的,Diffusion的训练成本更高,普通人根本训不起。这次能开源要得益于Stability AI的加持,由国外超级富豪Emad Mostaque创办,目标是创造开源的AI工具,大家可以把它当成真正的「Open AI」。这次的Stable Diffusion,是Stability AI的第一个公开产品,在4000台A100上训了一个月[4],有钱真好。
其次,它轻量,一张10GB以上显存的卡就能跑。 要知道即使DALLE2开源了,普通人也是用不起的,而Stable Diffusion经过优化后一张卡就能放得下了,做到了真真正正的亲民。
最后,它效果真的好,好到能商用。 这主要归功于高质量数据集LAION[5]的加持,我分别挑了DALLE2和Imagen的prompt来对比,感觉Stable Diffusion不亚于那两个大模型:

同时它还有很多种玩法:
- 文本生成图像
- 图像+文本生成图像
- 补全图像中的某个部分(例如把猫换成一只狗)
种种以上因素,让Stable Diffusion在几天内引爆了AI圈。
Diffusion的大航海时代
Diffusion最早是15年的一篇文章提出的[6],但当时并不完善,直到20年时的DDPM[7]才真正做work。之后的事情大家也就知道了,从21年底到22年间,先后有OpenAI的GLIDE、DALLE2和Google的Imagen都用上了这个工作。
Diffusion的核心思想,就是把生成的过程拆成一个个简单的小步骤,而不是像其他模型一样「一步到位」,这样拟合起来相对容易,所以做出来效果很好,同时训练起来也更加稳定。
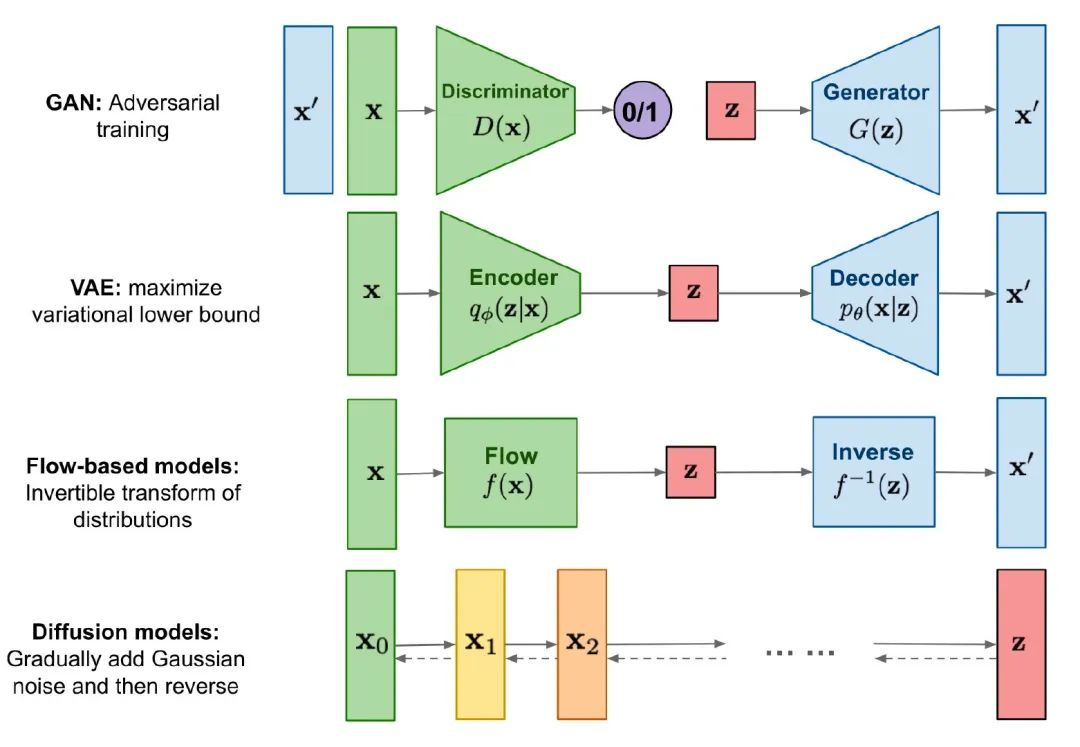
不过随之而来的,就是它训练过程消耗资源大(每一个小步都需要训练),同时生成的速度也慢(一步一步生成)。
正因为它存在缺点,在理论上还有很多研究可以做,同时它优秀的效果,使AIGC可以更进一步。
想想在过去,在移动互联网时代中,UGC撑起了多少应用吧:微博、知乎、B站、头条、抖音。。如果AI能增加UGC的效率,或者直接生产内容,会是什么样呢?再想想未来,在元宇宙里,如果不需要那么多人力去建模,那未来是不是能来的更快一些呢?
听到这里,是不是开始exciting了!
那就开始学习吧!
学习资料汇总
下面是我收集的靠谱学习资料:
HuggingFace推荐的博客:
代码+公式:https://huggingface.co/blog/annotated-diffusion
介绍和Paper汇总:https://github.com/heejkoo/Awesome-Diffusion-Models
知乎讨论:https://www.zhihu.com/question/536012286
B站视频:
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢