

论文链接: https://arxiv.org/pdf/2207.02204.pdf
代码链接: https://github.com/rshaojimmy/SeqDeepFake
项目主页: https://rshaojimmy.github.io/Projects/SeqDeepFake
导读
本文提出检测并还原DeepFake篡改序列(Seq-DeepFake)任务。相比于现有基于二分类 (真/假) 的 DeepFake 检测, 本文将其拓展到检测篡改序列, 提出 DeepFake 篡改序列检测这个新的研究课题,建立并开源了全球首个 Seq-DeepFake数据集。基于此数据集,本文进一步提出Seq-DeepFake Transformer(SeqFakeFormer)来准确地检测篡改序列。根据检测出的篡改序列,我们可以逆序还原出原始人脸。
贡献
由于生成模型的快速发展,高保真度的人脸图片和视频可以非常容易地生成。但是恶意使用生成模型产生难辨真假的虚假人脸图片或者视频进而导致虚假信息传播的现象也逐渐引起了广泛关注,这就是越来越严重的DeepFake问题。
解决DeepFake问题最常见的方式是学习一个二分类模型来进行真/假判别(如图1左)。如今由于人脸编辑App的流行,我们能非常方便地对人脸图片进行多步序列DeepFake篡改。
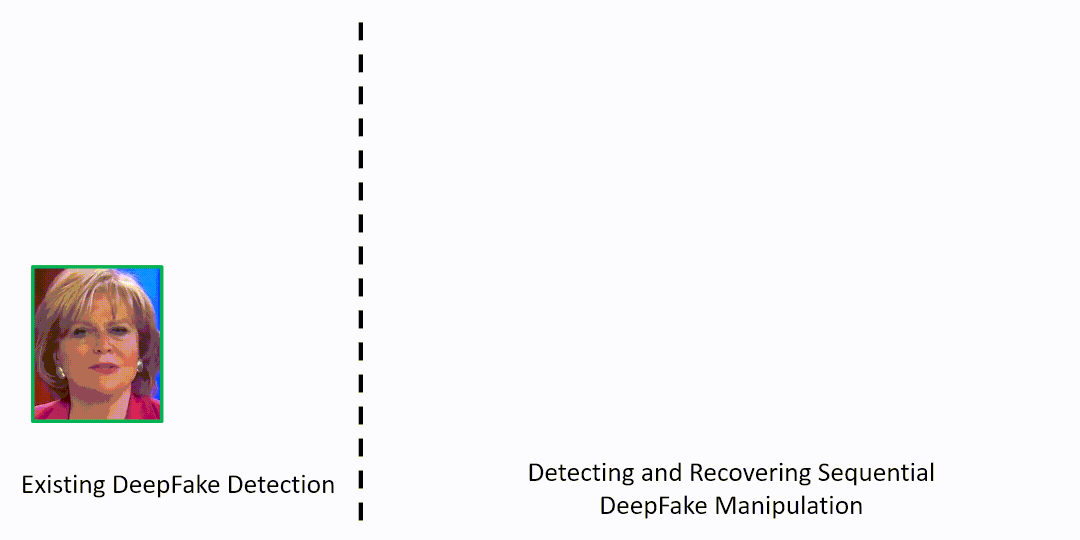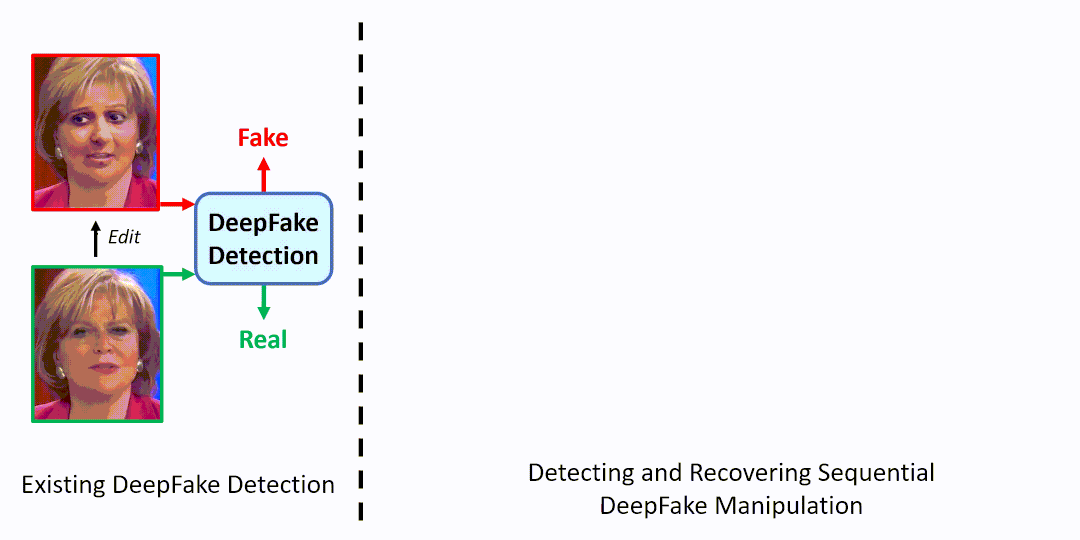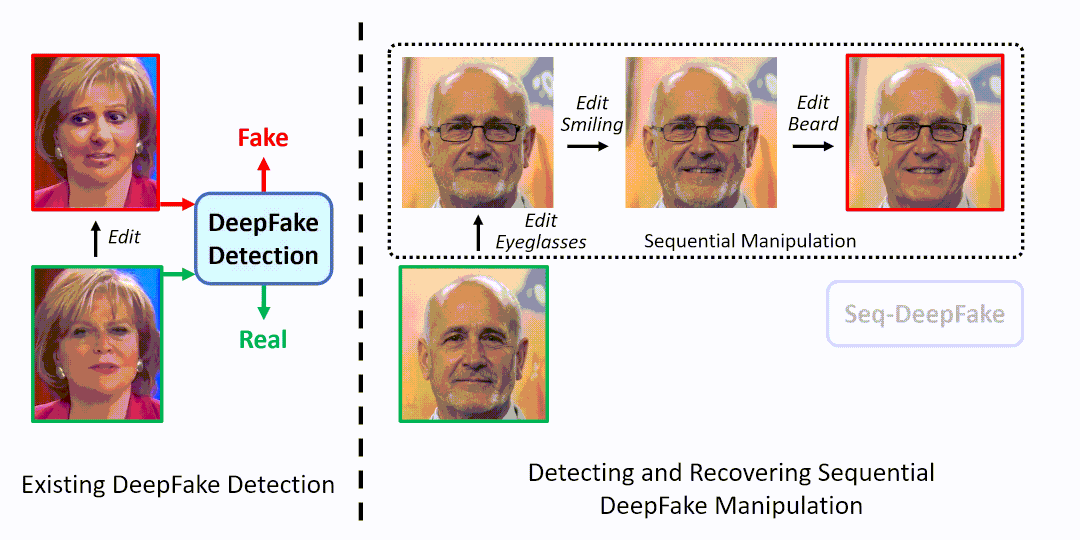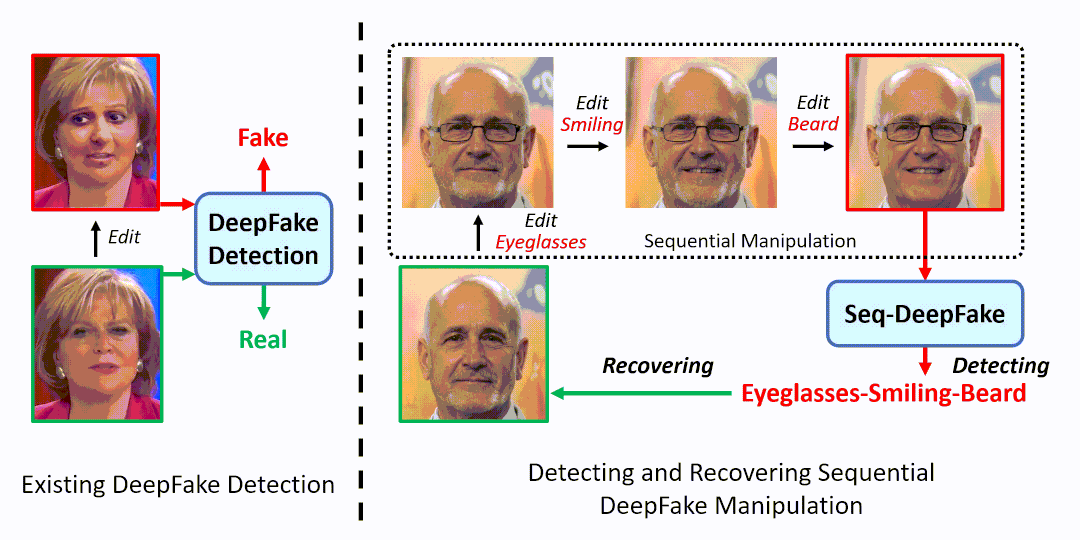
如图1右所示,我们可以对一张人脸图片,先后进行【添加眼镜-加入笑容-去掉胡须】的序列篡改。为解决此新型DeepFake问题,本文提出检测并还原DeepFake篡改序列(Seq-DeepFake)任务。
此任务和现有的DeepFake检测的区别在于:1)不同于现有DeepFake检测专注于二分类,Seq-DeepFake任务要求检测不同长度和顺序的篡改序列(如图1右所示的长度为3的篡改序列),2)除了篡改检测,Seq-DeepFake还可以根据检测出的篡改序列,逆序还原出原始人脸。
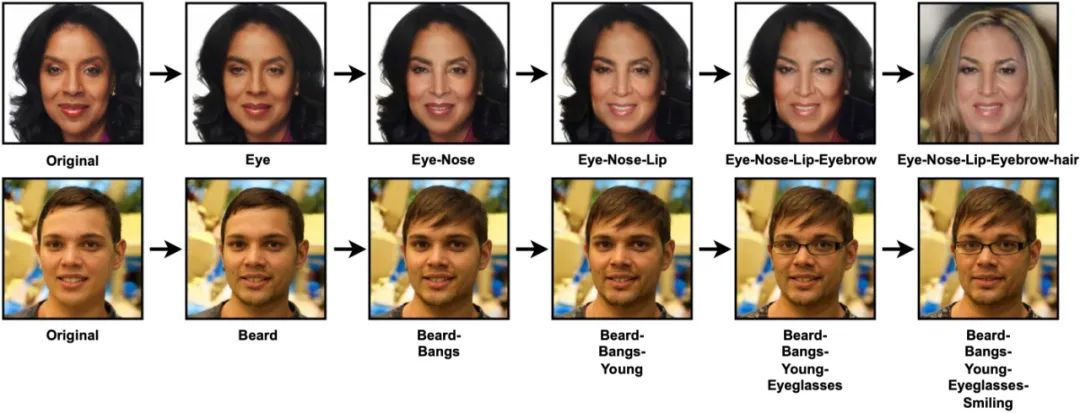
图2. Seq-DeepFake 样例

图3. Seq-DeepFake 数据集
为了支持对 Seq-DeepFake研究,本工作贡献了全球首个 Seq-DeepFake数据集。图2为 Seq-DeepFake的一个样例。对于数据集中的一张人脸图片,我们可以通过长度1~5的不同序列进行篡改。
方法
为了更全面的研究此问题,本文考虑了两种不同的篡改方法,即人脸部件序列篡改(sequential facial components manipulation)[1] 和人脸属性序列篡改 (sequential facial attributes manipulation) [2] (分别对应于图2和图3的第一排与第二排)。
如图2所示,人眼很难察觉原始人脸和篡改人脸之间的区别,而进一步检测出不同的篡改序列则难度更大。图3展示了 Seq-DeepFake 整体统计信息。在此数据集中,人脸部件序列篡改总共35,166张图片,包含了28种不同长度的篡改序列。人脸属性序列篡改总共49,920张图片,包含了26种不同长度的篡改序列。

图4. 不同篡改序列对于人脸篡改的影响
现有的人脸编辑算法基本基于 Generative Adversarial Network (GAN)。在GAN的隐空间中难以达到完美的语义分解[3],这会导致在编辑一种人脸部件/属性后,会间接影响其他人脸部件/属性。
我们可以从图2中观察到,步骤‘Eye-Nose’编辑鼻子后会导致前一步的眼睛和嘴巴部位的变动。由此,我们可以从此空间关系中发掘出 Seq-DeepFake 的空间篡改痕迹 ( spatial manipulation traces )。
再者,如图4所示,改变篡改先后顺序(图4(a) 中鼻子和眼睛,和(b)中留海和微笑的先后顺序)会产生不同的篡改结果(图4(a) 中不同的注视方向,和(b)中不同的刘海数量), 这说明篡改顺序会进一步影响篡改所影响的空间关系。也就是说,我们可以在空间篡改痕迹的基础上捕捉到序列篡改痕迹( sequential manipulation traces ), 并最终据此检测出 DeepFake 篡改序列。
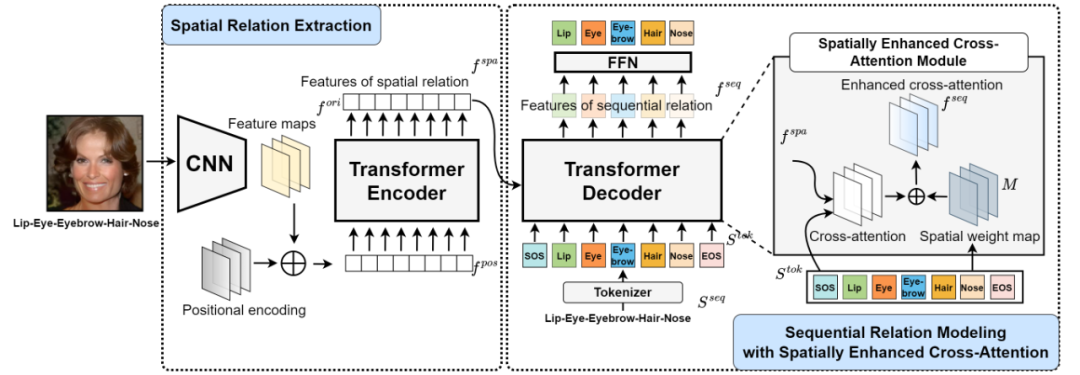
图5. 提出的Seq-DeepFake Transformer (SeqFakeFormer)
根据上述观察,我们把Seq-DeepFake看成是一种特殊的image-to-sequence problem (例如 image caption),并提出Seq-DeepFake Transformer (SeqFakeFormer)来检测篡改序列(图5)。
SeqFakeFormer由两个关键部分组成:Spatial Relation Extraction 和 Sequential Relation Modeling with Spatially Enhanced Cross-attention。在 Spatial Relation Extraction中,我们首先把人脸图片输入到一个卷积神经网络中得到DeepFake篡改的空间特征,并通过 Transformer Encoder中的 self-attention modules捕捉其空间关系得到空间篡改痕迹。
在Sequential Relation Modeling with Spatially Enhanced Cross-attention中, Transformer Decoder进一步通过空间篡改痕迹与篡改序列标签之间的cross-attention得到序列篡改痕迹。为了适应Seq-DeepFake篡改序列较短的特点,我们在Transformer Decoder中进一步加入了Spatially Enhanced Cross-Attention Module来对每种人脸篡改部件/属性生成不同的空间权重图(spatial weight maps),以此和原始cross-attention map加权进而得到一个更有效的cross-attention过程。
实验
如下图,实验结果表明我们提出的 SeqFakeFormer与为二分类设计的DeepFake检测方法相比,能更准确地检测DeepFake序列篡改。




图6. 基于正确和错误篡改序列得到的人脸还原结果
一旦得到篡改序列后,如图6所示,本任务还可以逆序还原出原始人脸。在图6中,我们可以观察到还原出的人脸非常接近于原始人脸。如果序列的先后顺序错误,即使序列中各元素都已检测正确,原始人脸的还原仍会大概率失败。这进一步说明了正确检测人脸篡改序列的重要性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢