
论文标题:UniTAB: Unifying Text and Box Outputs for Grounded Vision-Language Modeling
论文地址:https://arxiv.org/abs/2111.12085
代码地址:https://github.com/microsoft/UniTAB
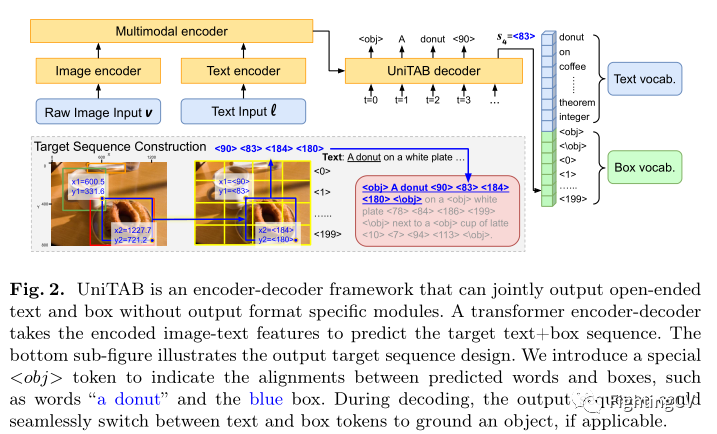
作者使用构建在单模态图像和文本编码器之上的Transformer编码器-解码器架构来实现 UniTAB,如下图所示。对于图像,作者使用 ResNet-101对原始图像输入 v 进行编码,并将网格特征展平作为视觉表示。对于文本,使用将输入文本 l 编码为隐藏词特征。作者使用一个 6 层的 Transformer 编码器,它接收concat的图像和文本特征序列作为输入,以及用于生成输出序列的 6 层Transformer 解码器。解码器以自回归方式生成输出token,类似于语言建模。UniTAB 解码器可以从文本和方框词汇中生成token,如下图右侧所示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢