作者:杜伟
在大模型领域,阿里持续发力,用技术和思路创新走出一条不一样的路。
时至今日,大模型已经成为整个 AI 产学界追逐的技术「宠儿」,炼大模型如火如荼,各式各样参数不一、任务导向不同的大模型层出不穷。大模型具备效果好、泛化能力强等特点,进一步增强了 AI 的通用性,成为 AI 技术和应用的新基座。
具体到 NLP、CV 领域,基于文本、图像、语音和视频等单一模态的大模型在各自下游任务上不断取得 SOTA 结果,有时甚至超越人类表现。单模态单任务似乎走到了极致。同时现实世界中的这些模态并不总是独立存在,更多地是以跨模态的形式出现。
基于这些,预训练大模型逐渐朝着大一统方向发展,希望单个模型能够同时处理文本、图像、音频、视频等多模态任务,即使现有模型无法做到也要留出能力空间。
目前,业界已经出现一些能够处理多模态任务的通用模型,比如 DeepMind 的通用图文模型 Flamingo 和通才智能体 Gato,MSRA 的 BEiT-3 等。这些都展现出了大模型突破单一模态和单一任务的巨大潜力,但在实现全模态全任务的通用性上依然面临技术难点。大模型的训练与落地应用也受到算力限制。
在国内,阿里达摩院一直以来深耕多模态预训练,并率先探索通用统一大模型。去年,阿里达摩院先后发布多个版本的多模态及语言大模型,在超大模型、低碳训练技术、平台化服务、落地应用等方面实现突破。其中使用 512 卡 V100 GPU 实现全球最大规模 10 万亿参数多模态大模型 M6,同等参数规模能耗仅为此前业界标杆的 1%,极大降低大模型训练门槛。
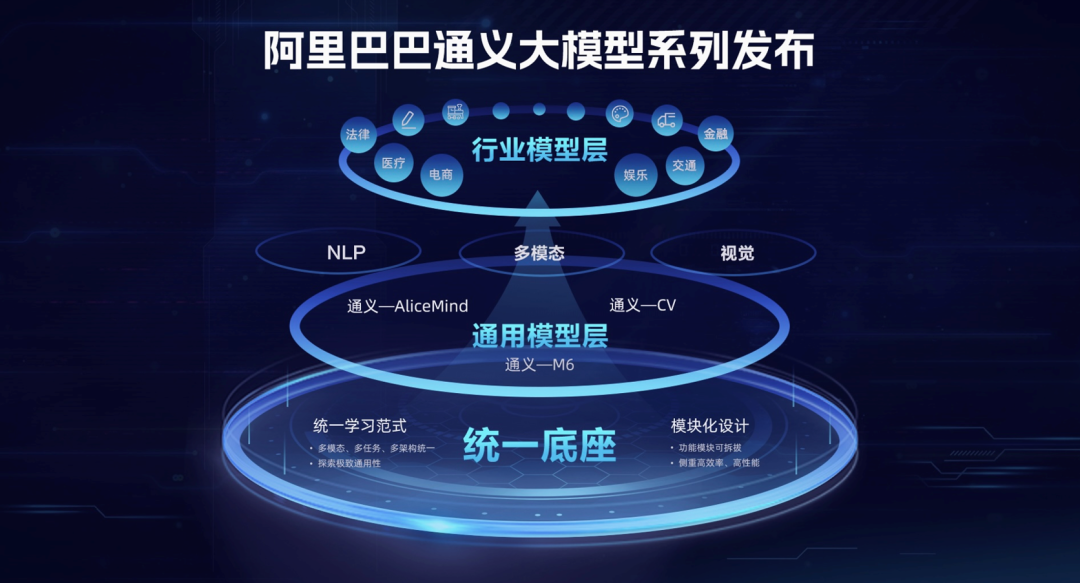
阿里探索大模型通用性及易用性的努力并没有止步于此。9 月 2 日,在阿里达摩院主办的世界人工智能大会「大规模预训练模型」主题论坛上,阿里巴巴资深副总裁、达摩院副院长周靖人发布阿里巴巴最新「通义」大模型系列,其打造了国内首个 AI 统一底座,并构建了通用与专业模型协同的层次化人工智能体系,将为 AI 从感知智能迈向知识驱动的认知智能提供先进基础设施。
为了实现大模型的融会贯通,阿里达摩院在国内率先构建 AI 统一底座,在业界首次实现模态表示、任务表示、模型结构的统一。通过这种统一学习范式,通义统一底座中的单一 M6-OFA 模型,在不引入任何新增结构的情况下,可同时处理图像描述、视觉定位、文生图、视觉蕴含、文档摘要等 10 余项单模态和跨模态任务,并达到国际领先水平。这一突破最大程度打通了 AI 的感官,受到学界和工业界广泛关注。近期 M6-OFA 完成升级后可处理超过 30 种跨模态任务。
通义统一底座中的另一组成部分是模块化设计,它借鉴了人脑模块化设计,以场景为导向灵活拆拔功能模块,实现高效率和高性能。
周靖人表示,「大模型模仿了人类构建认知的过程,通过融合 AI 在语言、语音、视觉等不同模态和领域的知识体系,我们期望多模态大模型能成为下一代人工智能算法的基石,让 AI 从只能使用‘单一感官’到‘五官全开’,且能调用储备丰富知识的大脑来理解世界和思考,最终实现接近人类水平的认知智能。」

通义统一底座中统一学习范式的实现背后离不开阿里达摩院的多模态统一底座模型 M6-OFA,相关研究被 ICML 2022 接收,代码、模型和交互式服务也已开源。

-
论文地址:https://arxiv.org/pdf/2202.03052.pdf
-
开源地址:https://github.com/OFA-Sys/OFA
-
交互式 Demo 地址:https://huggingface.co/OFA-Sys
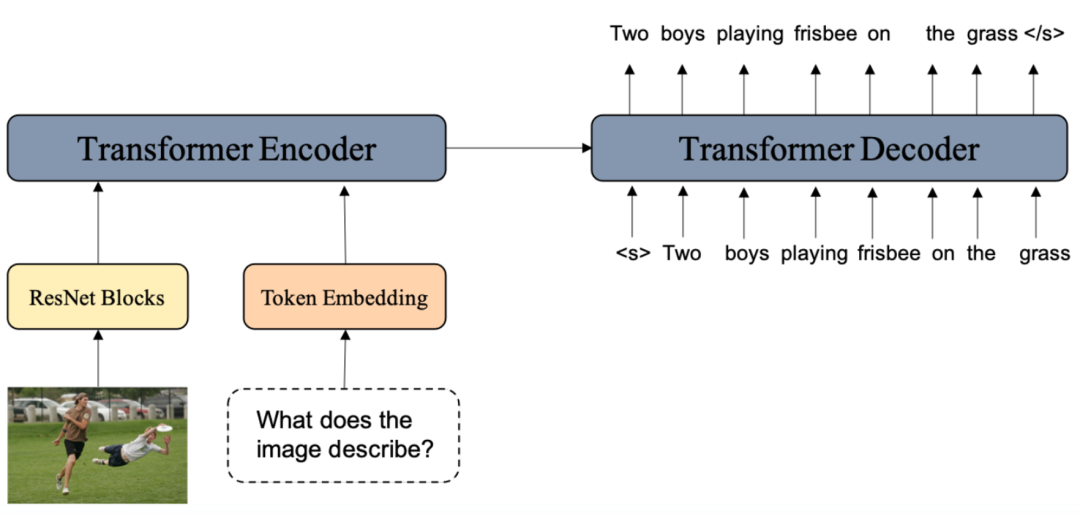
先来看架构统一。M6-OFA 整体采用了经典的 Transformer Encoder-Decoder,外加一个 ResNet Blocks。通过这种架构完成所有任务,让预训练和微调采用相同的学习模式,无需增加任何任务特定的模型层。
如下图所示,ResNet Blocks 用于提取图像特征,Transformer Encoder 负责多模态特征的交互,Transformer Decoder 采用自回归方式输出结果。
对于模态统一,M6-OFA 构建了一个涵盖不同模态的通用词表,以便模型使用该词表表示不同任务的输出结果。其中 BPE 编码的自然语言 token 用于表示文本类任务或图文类任务的数据;图片中连续的横纵坐标编码为离散化 token,用于表示视觉定位、物体检测的数据;图片中的像素点信息编码为离散化 token,用于表示图片生成、图片补全等任务的数据。
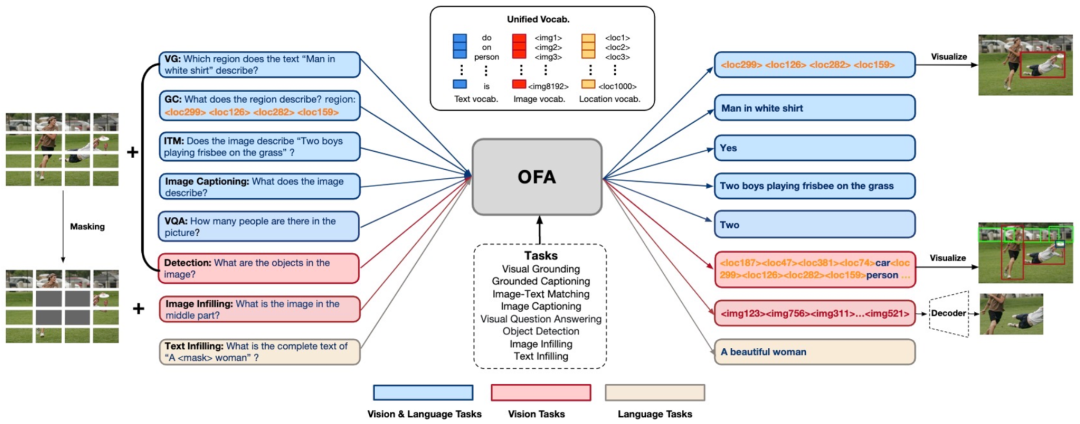
最后是任务统一,通过设计不同的 instruction,M6-OFA 将涉及多模态和单模态(即 NLP 和 CV)的所有任务都统一建模成序列到序列(seq2seq)任务。M6-OFA 覆盖了 5 项多模态任务,分别为视觉定位、定位字幕、图文匹配、图像字幕和视觉问答(VQA);2 项视觉任务,分别为检测和图像填补;1 项文本任务,即文本填补。
今年 2 月,M6-OFA 统一多模态模型在一系列视觉语言任务中实现了 SOTA 性能,在 Image Caption 任务取得最优表现,长期在 MSCOCO 榜单排名第一;在视觉定位任务中的 RefCOCO、RefCOCO + 和 RefCOCOg 三个数据集均取得最优表现,以及在视觉推理任务的数据集 SNLI-VE 上取得第一。OFA 的 VQA 分数达到 82.0,效果名列前茅。文本生成图像(text2Image)在 COCO 数据集上超越了此前基线模型,当时的 Case 对比也优于 GLIDE 和 CogView。并且,OFA 模型展现出一定的零样本学习新任务的能力。
下图展示了 M6-OFA 的 text2Image 和 VQA 任务的跨模态生成结果。

在更大规模的文生图的数据进行微调后,模型也取得了通用领域文生图任务的优异表现,尤其擅长艺术创作,如下图所示:

目前业界普遍认为,人脑本身由不同的模块组成,大脑中拥有储备各种知识和处理不同模态信息的能力模块,人类思考时只调用与特定任务相关的模块,正这种机制保证了人脑的高速运行。通义统一底座的另一组成部分「模块化设计」正是借鉴了这种运行机制。
具体而言,模块化大一统模型采用模块化 Transformer Encoder-Decoder 结构来统一多模态的理解和生成,同时切分出不同的独立模块,包括基础层、通用层(如不同模态)、任务层到功能性模块(如推理),每个模块间相互解耦,各司其职。
达摩院团队为何会探索这种模块化设计思路呢?现在大规模预训练的 Transformer-based 模型虽然能够很好地解决感知智能相关任务,但缺乏精心设计的纯 Transformer 模型基本无法完成对于实现认知智能的尝试。借鉴人脑的模块化设计成为一种可能通向成功的思路。
在单一 NLP 模块中,最底层为数据表示层,中间层为 Transformer 基础语义表示模块,最上层则是对整个下游划分为不同的任务模块;而对于多模态的模块化,其模态模块涵盖语言、视觉、音频和视频——底部输入层接收各自模态信息,中间层通过跨模态信息融合学习统一语义表示,往上再划分为针对不同模态的具体下游任务。
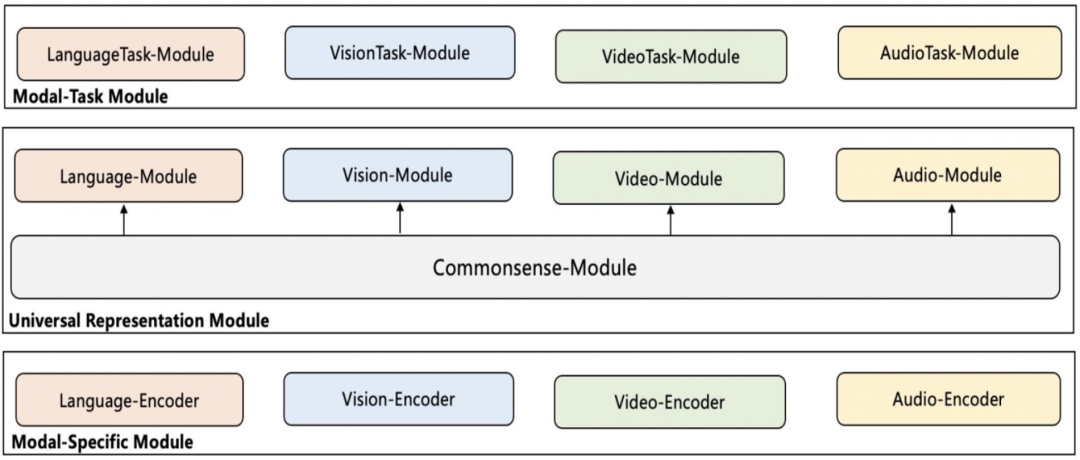
针对不同类型的下游任务,模块化模型可灵活拆拔不同模块进行微调或者进行继续预训练。通过这种方式,大模型能够实现轻量化,并取得较好的微调效果,单模态、多模态任务水平均能得到提升。
大模型最终是要实现落地,满足各行各业的应用需求。因此,阿里达摩院基于其 AI 统一底座构建了通用模型与专业模型协同的层次化人工智能体系。
下图为通义大模型整体架构,最底层为统一模型底座,中间基于底座的通用模型层覆盖了通义 - M6、通义 - AliceMind 和通义 - 视觉,专业模型层深入电商、医疗、娱乐、设计、金融等行业。

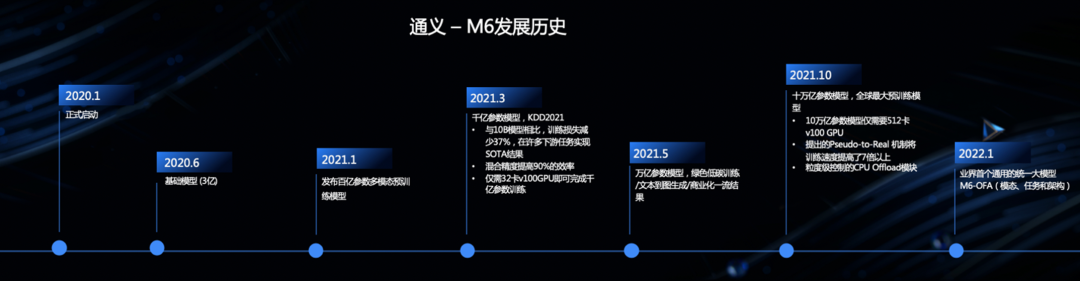
通义 - M6 已经从 2020 年 6 月的 3 亿参数基础模型发展到 2021 年 10 月的 10 万亿参数全球最大预训练模型到 2022 年 1 月的业界首个通用统一大模型 M6-OFA。
通义 - AliceMind 是阿里达摩院开源的深度语言模型体系,包含了通用语言模型 StructBERT、生成式 PALM、结构化 StructuralLM、超大中文 PLUG 、多模态 StructVBERT、多语言 VECO、对话 SPACE 1.0/2.0/3.0 和表格 STAR 1.0/2.0,过程中形成了从文本 PLUG 到多模态 mPLUG 再到模块化统一模型演化趋势。
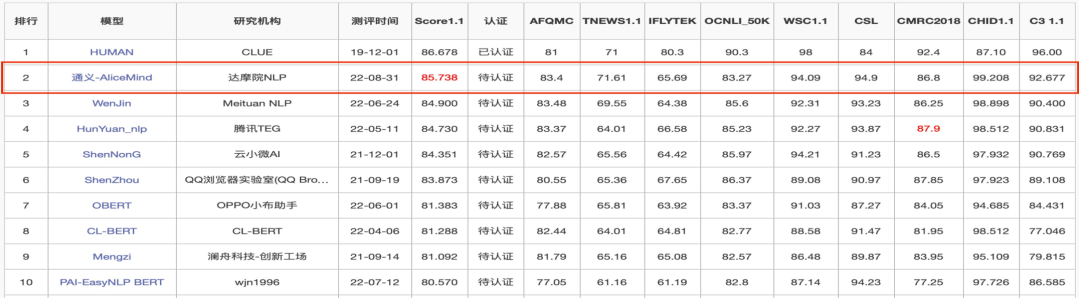
近日,基于 AliceMind/StructBERT 模型结果在中文语言理解测评基础 CLUE 上获得了三榜第一,分别是分类榜单、机器阅读理解榜单和总榜单。
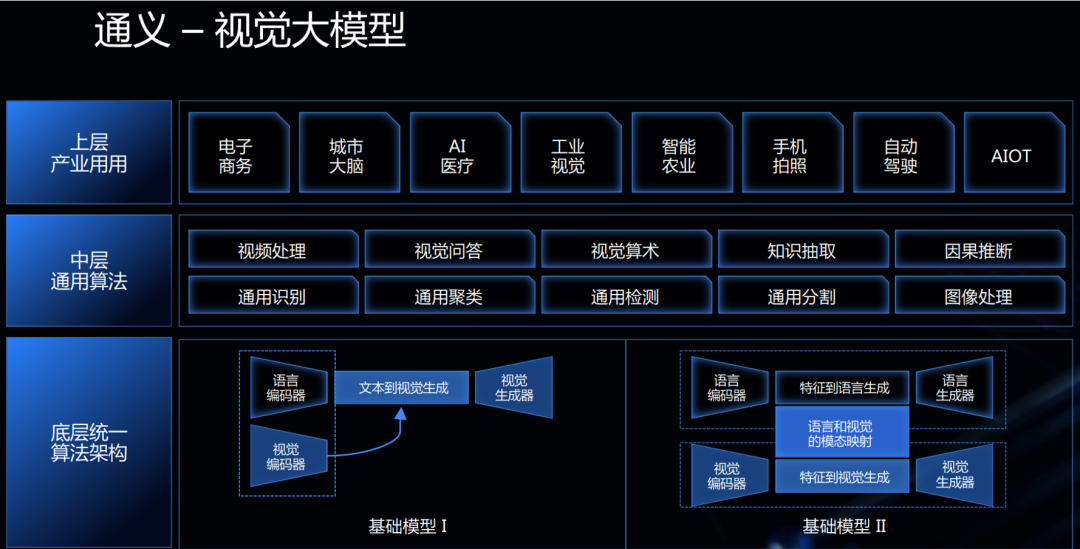
通义 - 视觉大模型自下往上分为了底层统一算法架构、中层通用算法和上层产业应用。据了解,通用 - 视觉大模型可以在电商行业实现图像搜索和万物识别等场景应用,并在文生图以及交通和自动驾驶领域发挥作用。
阿里始终秉持开源开放的理念。此次通义大模型系列中语言大模型 AliceMind-PLUG、多模态理解与生成统一模型 AliceMind-mPLUG、多模态统一底座模型 M6-OFA、超大模型落地关键技术 S4 框架等核心模型及能力已面向全球开发者开源,最新文生图大模型近期将开放体验。其中, 270 亿参数版 AliceMind-PLUG 是目前规模最大的开源语言大模型。
-
https://github.com/alibaba/AliceMind/
-
https://github.com/OFA-Sys/OFA
通过通用与专业领域大小模型的协同,阿里达摩院让通义大模型系列兼顾了效果最优化与低成本落地。然而实现这一切并不容易。
回到通义的设计思路,即通过一个统一的底座模型同时做单模态和跨模态任务,在多模态任务上取得 SOTA 效果的同时也能处理单模态任务。不过,既然希望模型更通用以覆盖更多模态及下游任务,则需要高效地将统一底座下沉到具体场景中的专用模型。这正是模型底座、通用模型与下游专业模型协同的关键。
受算力资源限制,大模型行业落地不易。近一两年,业界也提出了一些落地思路,即先打造一个基础大模型,再继续训练得到领域模型,最后通过微调构建具体行业任务模型。通义也要走通这样的路,不过希望通过新的大模型架构设计将这一过程做到更快和更高效。
可以这么说,无论是 seq2seq 统一学习范式还是模块化设计思路,阿里达摩院都希望对整个模型架构和统一底座有更深的理解。尤其是模块化思路,通过细分为很多个模块并知道它们能做什么,则真正可以在下游得到很高效且通用性很好的行业应用小模型。
目前,通过部署超大模型的轻量化及专业模型版本,通义大模型已在超过 200 个场景中提供服务,实现了 2%~10% 的应用效果提升。
比如,通义大模型在淘宝服饰类搜索场景中实现了以文搜图的跨模态搜索、在 AI 辅助审判中司法卷宗的事件抽取、文书分类等场景任务中实现 3~5% 的应用效果提升、在开放域人机对话领域通过建立初步具备「知识、情感以及个性、记忆」的中文开放域对话大模型实现了主动对话、广泛话题、紧跟热点等对话体验。
此外,通义大模型在 AI 辅助设计、医疗文本理解等其他领域也有丰富的应用场景。我们来看一组通义大模型在文生图领域的效果展示。比如文艺复兴时期皇家花栗鼠肖像画:



周靖人表示,对达摩院来说一直以来重点都不是把模型的规模做大,而是通过一系列的前沿研究和实践沉淀更通用更易用的大模型底层技术。现阶段,阿里达摩院希望将底座做得更实,将更多模态和任务考虑到统一模型范畴内,通过减少 AI 模型在实际场景落地中的定制化成本,真正体现出大模型的效果。
与此同时,在打造大模型统一底座的基础上,阿里希望通过开源开放,与外界用户和合作方自己共创下游应用。
参考链接:https://blog.csdn.net/AlibabaTech1024/article/details/125215198
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢