
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:Transformer是样本高效的世界模型、无需3D卷积的3D重建、Wordle的精确可解释解决方案、基于图像补全的视觉提示、自然语言处理高效方法综述、生成式文本到图像系统的逻辑感生重排、跨光谱神经辐射场、基于有符号射线距离函数(SRDF)的多视图重建、个性化代码生成模型的探索和评估
1、[LG] Transformers are Sample Efficient World Models
V Micheli, E Alonso, F Fleuret
[University of Geneva]
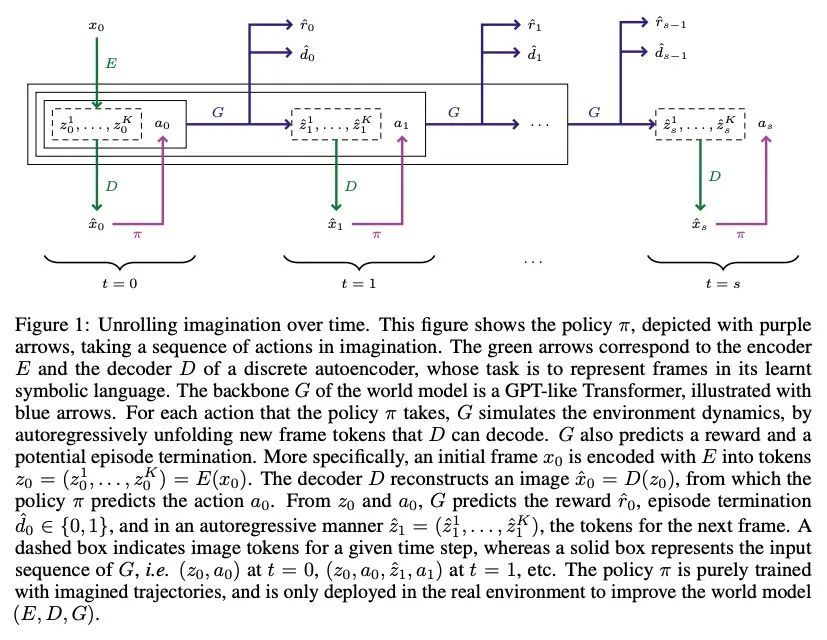
Transformer是样本高效的世界模型。深度强化学习智能体是众所周知的样本效率低下,这大大限制了它们对现实世界问题的应用。最近,设计了许多基于模型的方法来解决这个问题,其中在世界模型的想象中学习是最突出的方法之一。然而,虽然与模拟环境的几乎无限的交互听起来很吸引人,但世界模型必须在很长一段时间内是准确的。在Transformer在序列建模任务中成功的激励下,本文提出了IRIS,一种在由离散自编码器和自回归Transformer组成的世界模型中学习的数据高效的智能体。在Atari 100k基准测试中,IRIS只用了相当于两小时的游戏时间,就取得了1.046的人类归一化平均分,并在26个游戏中的10个游戏中优于人类。所提出方法为没有前瞻搜索的方法设定了一个新的技术状态,甚至超过了MuZero。IRIS的世界模型获得了对游戏机制的深刻理解,从而在一些游戏中实现了像素的完美预测。本文还说明了世界模型的生成能力,在想象训练时提供了丰富的游戏体验。IRIS以最小的调整开辟了一条有效解决复杂环境问题的新道路。
Deep reinforcement learning agents are notoriously sample inefficient, which considerably limits their application to real-world problems. Recently, many model-based methods have been designed to address this issue, with learning in the imagination of a world model being one of the most prominent approaches. However, while virtually unlimited interaction with a simulated environment sounds appealing, the world model has to be accurate over extended periods of time. Motivated by the success of Transformers in sequence modeling tasks, we introduce IRIS, a data-efficient agent that learns in a world model composed of a discrete autoencoder and an autoregressive Transformer. With the equivalent of only two hours of gameplay in the Atari 100k benchmark, IRIS achieves a mean human normalized score of 1.046, and outperforms humans on 10 out of 26 games. Our approach sets a new state of the art for methods without lookahead search, and even surpasses MuZero. To foster future research on Transformers and world models for sample-efficient reinforcement learning, we release our codebase at https://github.com/eloialonso/iris.
https://arxiv.org/abs/2209.00588



2、[CV] SimpleRecon: 3D Reconstruction Without 3D Convolutions
M Sayed, J Gibson, J Watson, V Prisacariu, M Firman, C Godard
[Niantic & UCL & Google]
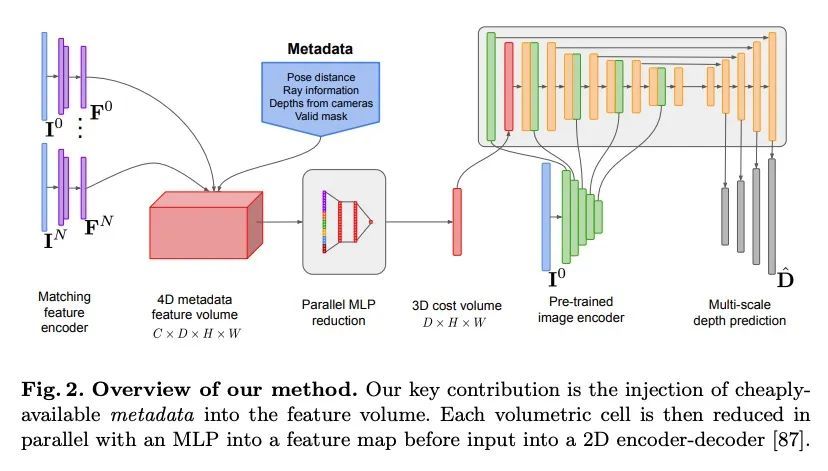
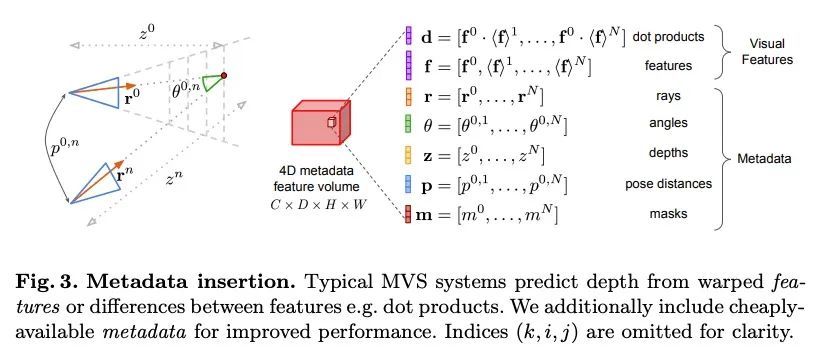
SimpleRecon:无需3D卷积的3D重建。传统上,从摆放的图像中进行的3D室内场景重建分为两个阶段:每图像的深度估计,然后是深度合并和表面重建。最近,出现了一系列方法,直接在最终的3D体特征空间中进行重建。虽然这些方法显示了令人印象深刻的重建结果,但它们依赖于昂贵的3D卷积层,限制了它们在资源有限环境中的应用。本文转而回到了传统路线,并展示了专注于高质量多视图深度预测如何用简单的现成的深度融合来实现高精度3D重建的。本文提出一种简单的最先进的多视图深度估计器SimpleRecon,能产生最先进的深度估计和3D重建,而不需要昂贵的3D开销:1)精心设计的2D CNN,受益于强大的图像先验以及平面扫描特征量和几何损失,再加上2)将关键帧和几何元数据整合到成本量中,从而实现深度平面计分。所提出的方法在深度估计方面比目前最先进的方法有明显的领先优势,在ScanNet和7-Scenes的3D重建方面接近或更胜一筹,但仍然允许在线实时低内存重建。
Traditionally, 3D indoor scene reconstruction from posed images happens in two phases: per-image depth estimation, followed by depth merging and surface reconstruction. Recently, a family of methods have emerged that perform reconstruction directly in final 3D volumetric feature space. While these methods have shown impressive reconstruction results, they rely on expensive 3D convolutional layers, limiting their application in resource-constrained environments. In this work, we instead go back to the traditional route, and show how focusing on high quality multi-view depth prediction leads to highly accurate 3D reconstructions using simple off-the-shelf depth fusion. We propose a simple state-ofthe-art multi-view depth estimator with two main contributions: 1) a carefully-designed 2D CNN which utilizes strong image priors alongside a plane-sweep feature volume and geometric losses, combined with 2) the integration of keyframe and geometric metadata into the cost volume which allows informed depth plane scoring. Our method achieves a significant lead over the current state-of-the-art for depth estimation and close or better for 3D reconstruction on ScanNet and 7-Scenes, yet still allows for online real-time low-memory reconstruction. Code, models and results are available at https://nianticlabs.github.io/simplerecon
https://nianticlabs.github.io/simplerecon/


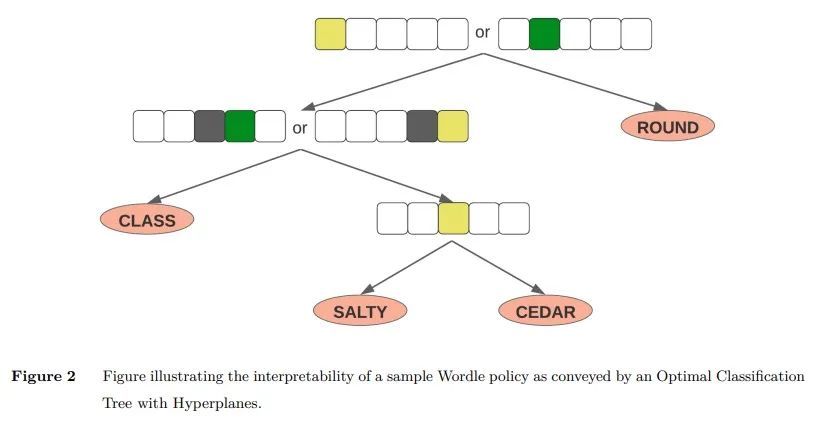
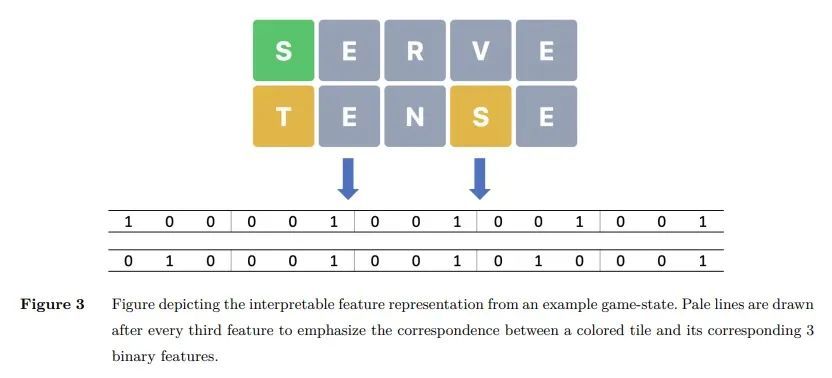
3、[LG] An Exact and Interpretable Solution to Wordle
D Bertsimas, A Paskov
[MIT]
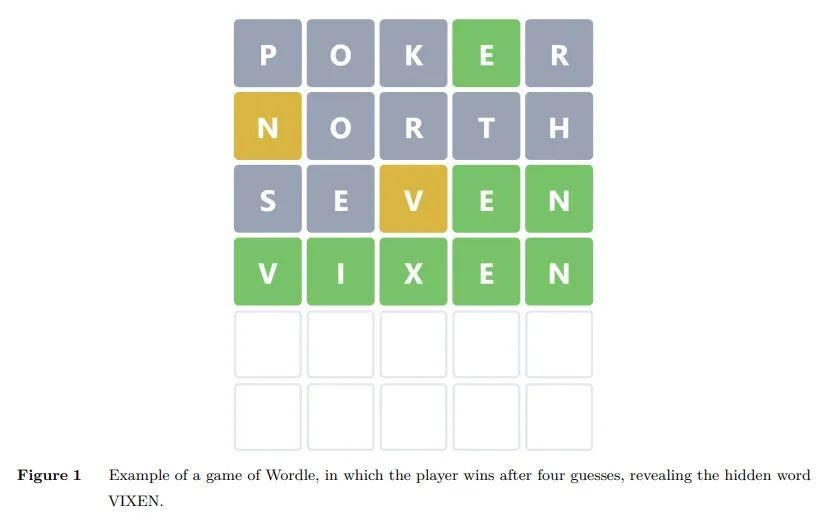
Wordle的精确可解释解决方案。本文提出一种基于精确动态规划的框架来解决Wordle游戏,该游戏经受住了从强化学习到信息论等多种方法的尝试。首先,本文推导出一个游戏的数学模型,提出由此产生的贝尔曼方程,并概述了一系列的优化措施,以使这种方法变得可行。其次,通过用超平面优化分类树,本文提出一种方法,以一种紧凑但可解释的方式展示策略——这是一个令人兴奋的结果,因为这允许读者理解策略并自己寻找新策略。本文给出了一些实验,阐明了为什么一些近似方法难以解决该游戏——而本文框架由于其精确的性质,成功地规避了这一点。实验表明,最好的起始词是SALET,该算法在最多五次猜测中找到所有的隐藏词,从SALET开始的平均猜测次数为3.421。
In this paper, we propose and scale a framework based on Exact Dynamic Programming to solve the game of Wordle, which has withstood many attempts to be solved by a variety of methods ranging from Reinforcement Learning to Information Theory. First, we derive a mathematical model of the game, present the resultant Bellman Equation, and outline a series of optimizations to make this approach tractable. Secondly, using Optimal Classification Trees with Hyperplanes, we present a methodology to showcase the policies in a compact yet interpretable manner – an exciting result as this allows readers to understand the policies and look for novel strategies themselves. We present experiments illuminating why some approximate methods have struggled to solve the game – and which our framework successfully circumvents due to its exact nature. We have implemented our algorithm in wordleopt.com. We show that the best starting word is SALET, the algorithm finds all hidden words in at most five guesses and the average number of guesses starting with SALET is 3.421.
https://auction-upload-files.s3.amazonaws.com/Wordle_Paper_Final.pdf

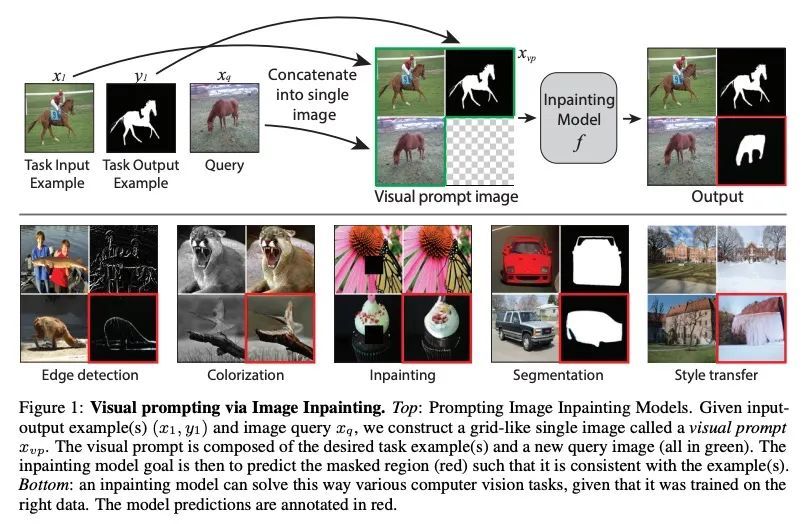
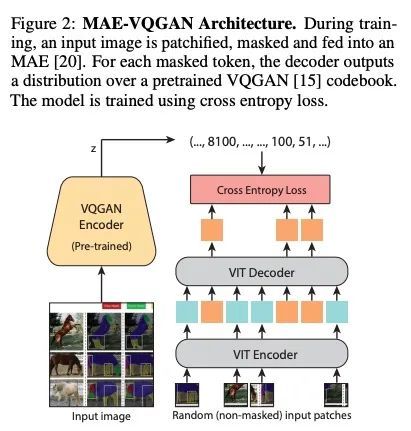
4、[CV] Visual Prompting via Image Inpainting
A Bar, Y Gandelsman, T Darrell, A Globerson, A A. Efros
[UC Berkeley & Tel Aviv University]
基于图像补全的视觉提示。如何使一个预训练好的视觉模型自适应新的下游任务,而不需要特定的微调或任何模型修改?受NLP中提示的启发,本文研究了视觉提示:给定测试时新任务的输入-输出图像样本和新的输入图像,目标是自动生成与给定样本一致的输出图像。本文表明,只要在正确的数据上训练了补全算法,把这个问题当作简单的图像补全——实际上就是在一个串联的视觉提示图像上填补一个洞——就会发现它的效果令人惊讶。本文在策划的新数据集上训练掩码自编码器——来自Arxiv上的学术论文来源的8800个未标记的插图。将视觉提示应用于这些预训练的模型,并在各种下游的图像到图像的任务中展示结果,包括前景分割、单目标检测、着色、边缘检测等。
How does one adapt a pre-trained visual model to novel downstream tasks without task-specific finetuning or any model modification? Inspired by prompting in NLP, this paper investigates visual prompting: given input-output image example(s) of a new task at test time and a new input image, the goal is to automatically produce the output image, consistent with the given examples. We show that posing this problem as simple image inpainting – literally just filling in a hole in a concatenated visual prompt image – turns out to be surprisingly effective, provided that the inpainting algorithm has been trained on the right data. We train masked auto-encoders on a new dataset that we curated – 88k unlabeled figures from academic papers sources on Arxiv. We apply visual prompting to these pretrained models and demonstrate results on various downstream image-to-image tasks, including foreground segmentation, single object detection, colorization, edge detection, etc.
https://arxiv.org/abs/2209.00647


5、[CL] Efficient Methods for Natural Language Processing: A Survey
M Treviso, T Ji, J Lee, B v Aken, Q Cao, M R. Ciosici...
[The Hebrew University of JerusalemUniversity of WashingtonStony Brook University & ...]
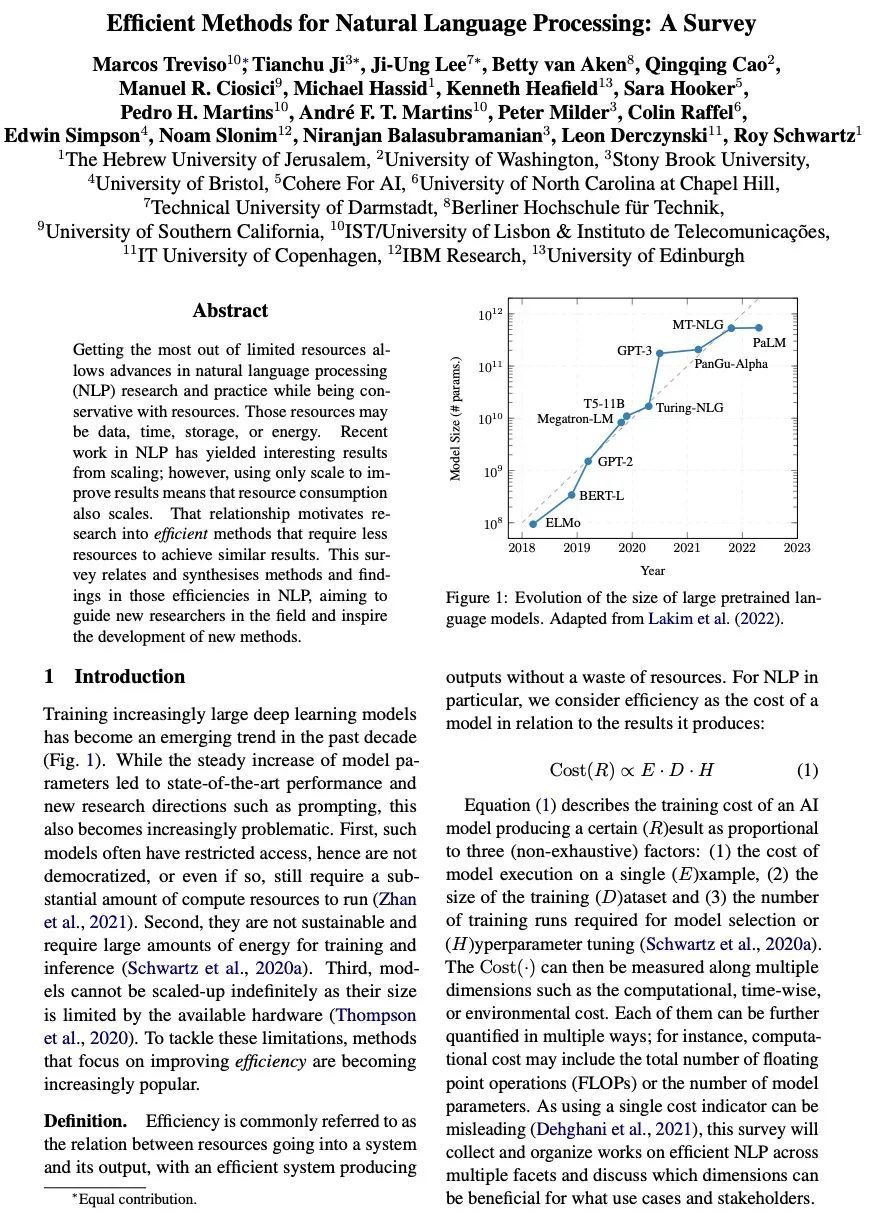
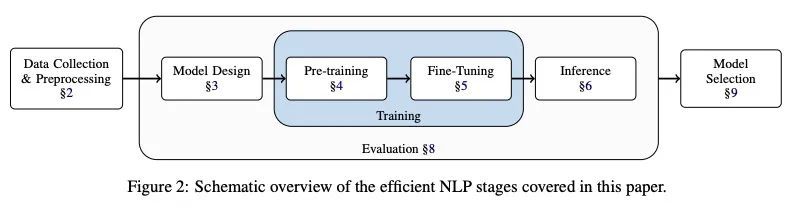
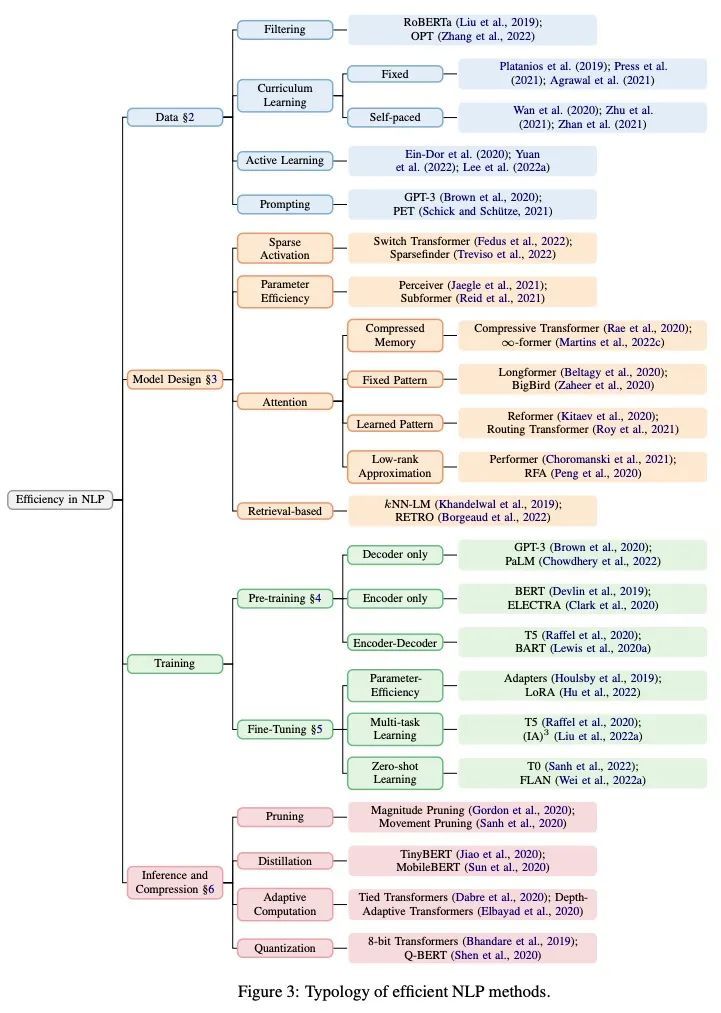
自然语言处理高效方法综述。从有限的资源中获得最大的收益,可以使自然语言处理(NLP)的研究和实践取得进展,同时节约资源。这些资源可能是数据、时间、存储或能源。最近在NLP方面的工作已经从扩展中产生了有趣的结果;然而,只用扩展来改善结果意味着资源消耗也会扩展。这种关系促使人们去研究那些需要更少资源来实现类似结果的高效方法。本文涉及并综合了NLP中那些高效的方法和发现,旨在指导该领域的新研究人员并激发新方法的开发。
Getting the most out of limited resources allows advances in natural language processing (NLP) research and practice while being conservative with resources. Those resources may be data, time, storage, or energy. Recent work in NLP has yielded interesting results from scaling; however, using only scale to improve results means that resource consumption also scales. That relationship motivates research into efficient methods that require less resources to achieve similar results. This survey relates and synthesises methods and findings in those efficiencies in NLP, aiming to guide new researchers in the field and inspire the development of new methods.
https://arxiv.org/abs/2209.00099

另外几篇值得关注的论文:
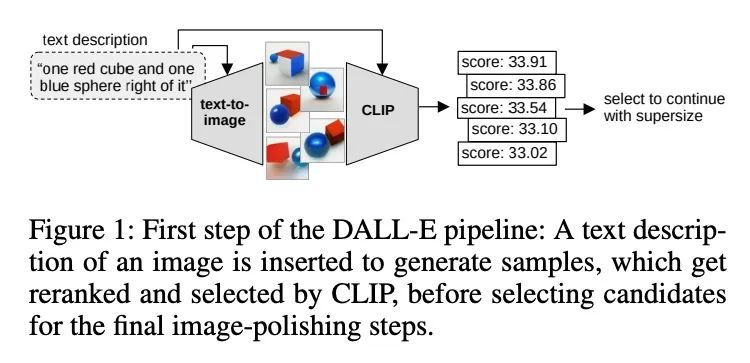
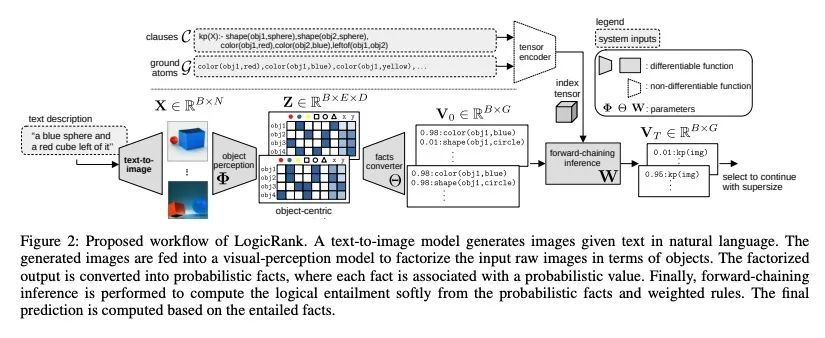
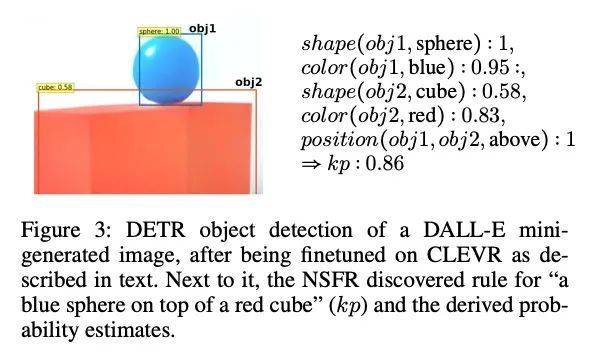
[CL] LogicRank: Logic Induced Reranking for Generative Text-to-Image Systems
LogicRank:生成式文本到图像系统的逻辑感生重排
B Deiseroth, P Schramowski, H Shindo, D S Dhami, K Kersting
[Technische Universitat Darmstadt & Hessian Center for AI & Aleph Alpha]
https://arxiv.org/abs/2208.13518

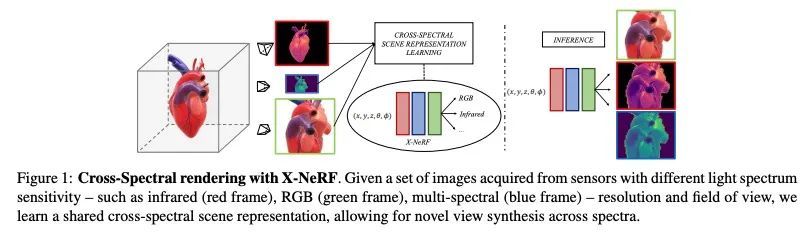
[CV] Cross-Spectral Neural Radiance Fields
跨光谱神经辐射场
M Poggi, P Z Ramirez, F Tosi, S Salti, S Mattoccia, L D Stefano
[University of Bologna]
https://arxiv.org/abs/2209.00648


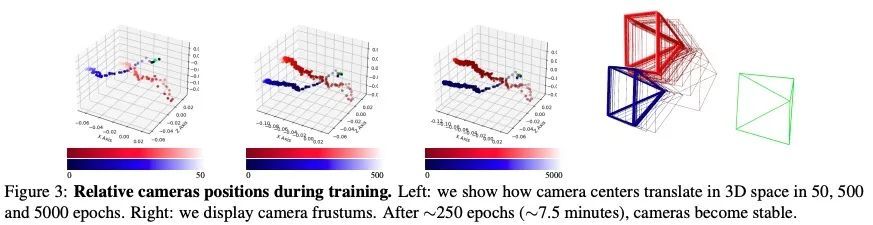
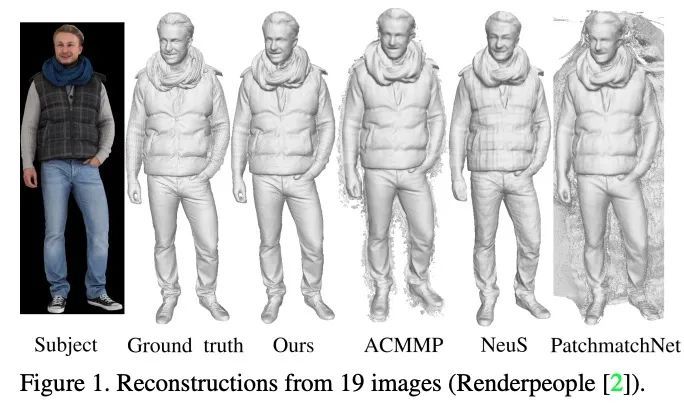
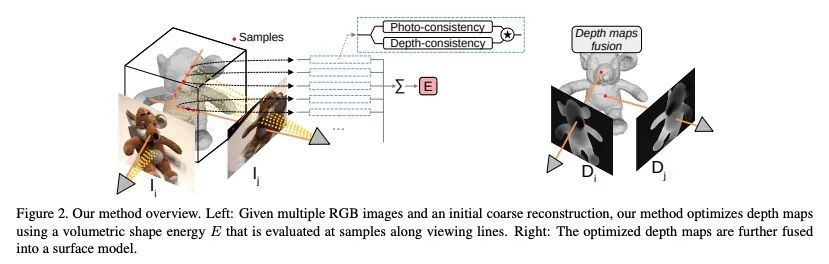
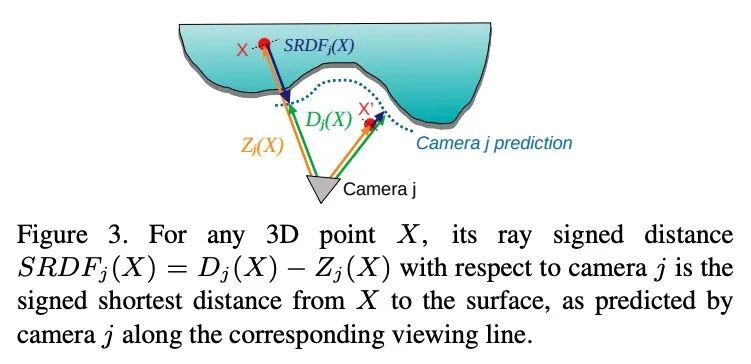
[CV] Multi-View Reconstruction using Signed Ray Distance Functions (SRDF)
基于有符号射线距离函数(SRDF)的多视图重建
P Zins, Y Xu, E Boyer, S Wuhrer, T Tung
[Univ. Grenoble Alpes & Meta Reality Labs]
https://arxiv.org/abs/2209.00082

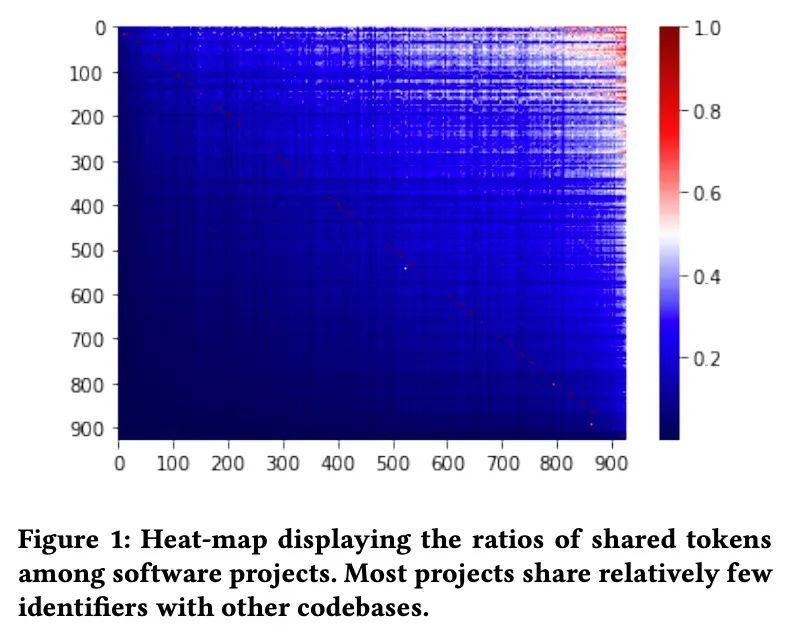
[CL] Exploring and Evaluating Personalized Models for Code Generation
个性化代码生成模型的探索和评估
A Zlotchevski, D Drain, A Svyatkovskiy, C Clement, N Sundaresan, M Tufano
[McGill University & Anthropic & Microsoft]
https://arxiv.org/abs/2208.13928

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢