

项目地址: https://gthub.com/timothyhtimothy/fast-vqa
论文链接: https://arxiv.org/abs/2207.02595
导读
在ECCV 2022上,商汤科技-南洋理工大学联合AI研究中心S-Lab提出的端到端高效视频质量评估方法,通过采样一种新型的“碎片(fragments)”作为用于视频质量评估的深度神经网络的输入,在达到高效率的同时得以保留视频中的质量相关信息,并进一步根据“碎片”的特征设计了基于Transformer结构的碎片注意力网络。其所提出的模型仅利用以往方法1/200的计算资源即可达到更加准确的视频质量评估能力,并首次得以训练一个对视频质量敏感的骨干网络,这一预训练的骨干网络进一步在其他下游质量敏感的任务上具有优良的效果。
贡献
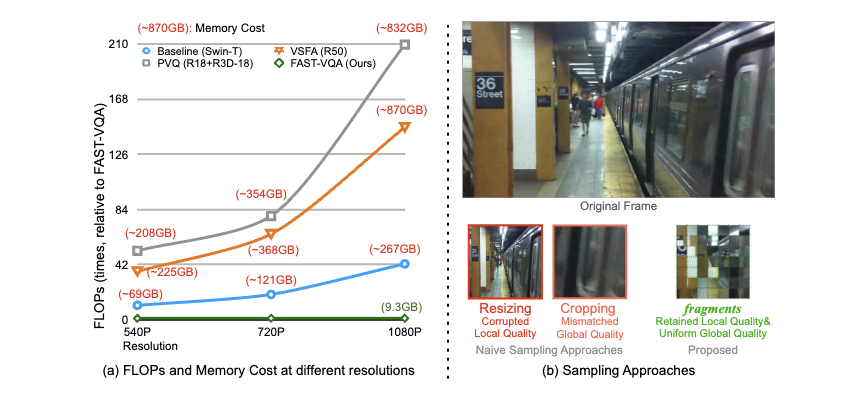
近年来,随着拍摄器材的进步,越来越多用户选择自己拍摄视频记录生活,而且这些视频往往拥有很高的分辨率(720P,1080P 等)。
由于这些视频并非经由特定类型的人工失真产生而且不存在一个高质量参考视频,基于手工特征的传统视频质量评估方法往往很难获得很好的效果;目前行业内最主流的方法是选择利用神经网络预训练的特征对主观分数进行回归,然而对于高分辨率的视频,提取这样的特征需要非常多的计算资源,即使是使用常见的ResNet-50,对于一个10s、1080P的视频需要81838GFLops,这几乎是不可以接受的。
另外,如果直接对这些视频进行端到端的训练,单个视频就需要消耗200GB以上的显存,因此很多方法不得不选择分段或逐帧进行特征预提取。
然而,预提取的特征不能针对性根据视频质量评估任务进行更新,在视频质量评估上的能力限制。如果对预先对视频进行降分辨率或者切片,可以解决效率问题,但本质上改变了视频的质量,因此也没有被主流方法采用。
总的来说,目前的深度视频质量评估方法无论是准确性和效率大多都无法令人满意。
方法
针对以上提出的问题,我们决定设计一种新的高效的、同时又具有质量敏感性的采样方式,并将采样之后的结果作为一个端到端神经网络的输入,以设计一个真正的完全基于深度学习的视频质量评估方法。因此,自然而然地,我们的方法分为两个部分:第一部分,我们设计了碎片(fragments)这种采样的方式,在保留质量信息的同时降低输入的尺度;第二部分,我们针对碎片以及视频质量评估的特点改良现有的神经网络,并设计了碎片注意力网络。两个部分共同组成了提出的FAST-VQA方法。
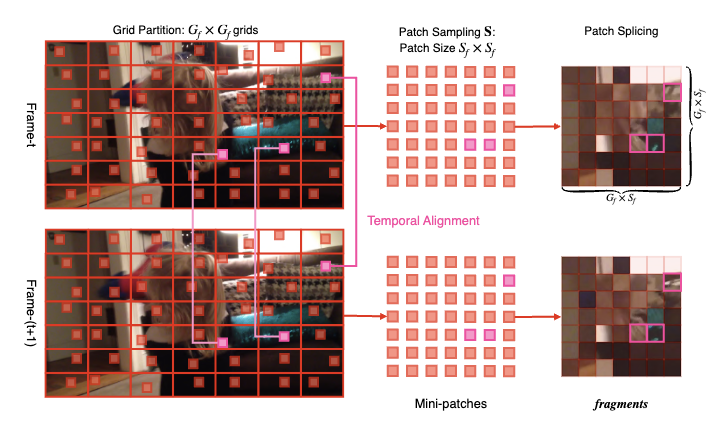
第一部分:基于网格的迷你切片采样(碎片采样)
鉴于采样的目的是保留对视频质量的敏感性,我们依次探讨对视频质量有明显影响的四个重要原则,并根据这些原则逐步介绍我们碎片采样方案的设计流程。整个碎片采样的流程图见上图。
- 第一个原则:采样的质量需要具有全局代表性
一个视频的不同区域质量往往不同。如果我们只采集视频某个空间区域的内容,采样本身可能就会改变视频的质量。因此,我们需要确保采样具有一定的均匀性。为了实现这一点,我们对视频进行了空间的网格划分(Grid Partition),将视频划分成 个网格,以便于下一步在网格内进行需要的采样。 表示第 帧的第 个网格,公式如下:
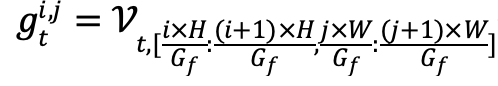
- 第二个原则:每个网格的采样必须对局部质量敏感
过去的视频质量方法大多证明,一旦对视频进行降采样等操作,就会降低对于例如清晰度、噪声、模糊等局部质量相关问题的敏感性。因此,为了保留对局部纹理质量的敏感性,我们在每个网格中随机采集原始清晰度的迷你切片,如下公式所示:
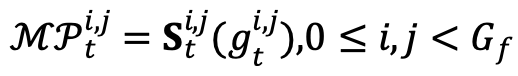
- 第三个原则:采样应当对时域质量敏感
时域质量同空域质量一样,也影响观察者对于视频质量的感知,而时域上的质量问题(例如抖动、闪烁)等,又往往与相邻帧之间的变化相关。因此,采样时应尽量保证原始视频中帧与帧之间的变化保留在采样之中,这就需要不同帧中的随机采样保持对齐。因此,我们提出时序对齐约束,公式如下:
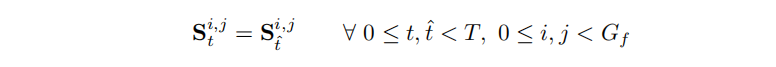
- 第四个原则:采样仍然应当保留一定的场景信息
深度视频质量评价最重要的优势是可以理解场景信息,而往往单独的迷你切片已经不足以反映整个视频的场景。然而,切片之间的上下文关系却可以帮助理解原始视频的场景。因此,不同于常见的将各个采样分别输入神经网络的做法,我们在输入神经网络前先按照采样的位置关系将迷你切片全部拼接在一起,得到最终的总采样,并命名为“碎片”(fragments)。

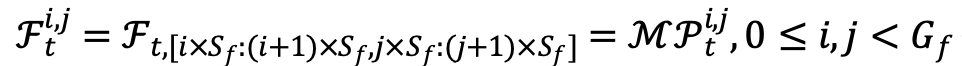
第二部分:为“碎片”改造现有的神经网络
“碎片”本身是基于切片(patch)的输入形式。近年来,随着 Vision Transformers 的发展,越来越多的网络本身已经隐式地在计算时将输入划分为切片进行处理。因此,这些网络非常适合作为基础的骨干网络,用于处理“碎片”这种输入形式。考虑到视频质量评估本身的任务特征,即对局部信息和局部关系极为敏感,我们选择了基于 Video Swin Transformer 系列中最轻的骨干网络 Swin-Tiny 作为我们的基线骨干网络。相比于 ResNet-50等传统网络形式,Swin-Tiny 使用互不重叠的降采样方式,这使得我们可以轻易的将切片的边界与 Swin-Tiny 降采样区域的边界进行对应。我们还进行了下边两个改进,最终得到了碎片注意力网络(FANet),更加适合以“碎片”作为输入。
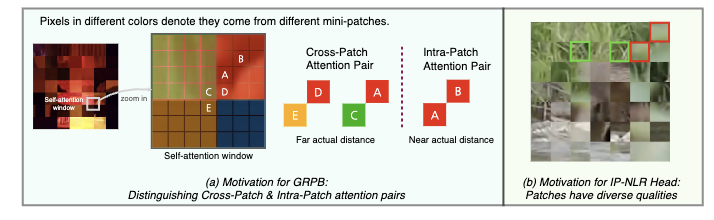
- 门控相对位置偏差(GRPB)
如果不考虑 Swin-Tiny 的自注意力层,同一组碎片中各个迷你切片之间的操作是完全相互独立的,因此,除自注意力层之外的其他层都被原样保留下来。然而,基于 Swin-Tiny 本身的窗自注意力(Window Self-Attention,WSA)结构的特点,我们观察到在同一个窗内会出现来自于不同的迷你切片的像素。尽管对来自不同迷你切片的像素进行自注意力本身是合理且有效的,基线网络中设计的相对位置偏差(RPB)并没有办法正确表示和学习它们之间的相对位置关系。由于RPB本身是以一对像素的相对位置作为索引,我们设计将RPB一分为二:对于来自同一切片中的像素对,我们沿用一个真实位置偏差表以表示它们之间的位置关系;对于来自不同切片的像素对,我们则采用另一个伪位置偏差表来表示它们之间的位置关系。总的GRPB的公式如下:
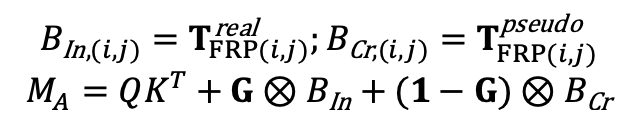
- 切片内非线性质量回归(IP-NLR)
在骨干网络提取特征后,现有的用于分类等任务的神经网络常常会先对特征进行池化,再进行线性的回归;然而,这种方式并不适合基于“碎片”的质量评价任务,因为不同的碎片中往往包含差距很大的质量信息,而这些质量信息具有相当的局部性,一旦池化后会被破坏。因此,我们设计了“先非线性回归,再池化”的方案,即IP-NLR,如下公式所示:
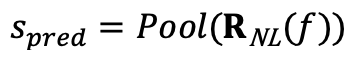
实验
我们首先在大型公开视频质量评估数据集LSVQ上进行训练,并用同一个模型比较在不同测试集上的测试结果。两个版本的模型,FAST-VQA和FAST-VQA-M,都实现了非常好的性能,超过了现有的最佳方法PVQ。FAST-VQA在仅需要1/210计算复杂度的情况下比PVQ提升了10%,而FAST-VQA-M则更加高效,不仅在1秒钟之内就可以在CPU上进行推理,还同样超过了PVQ这一方法。
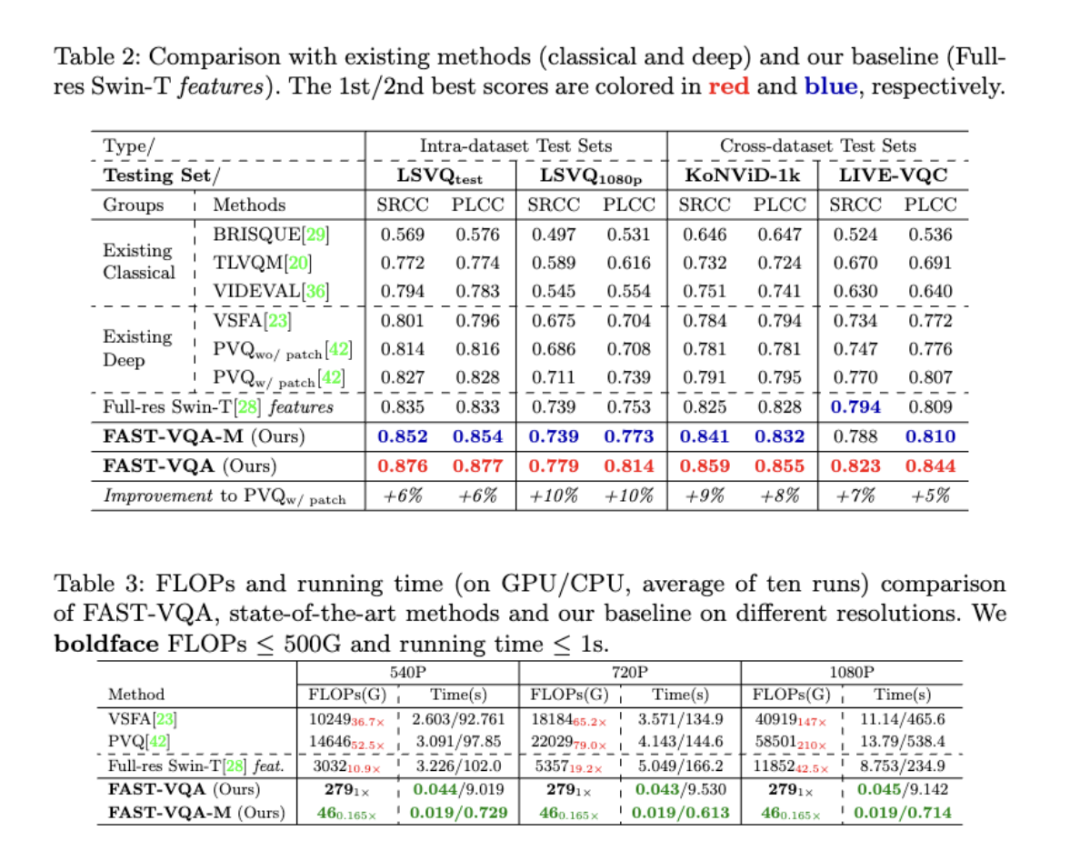
这些实验结果证明了基于“碎片”和端到端深度学习的FAST-VQA方法不仅足够快,性能上也十分优秀。
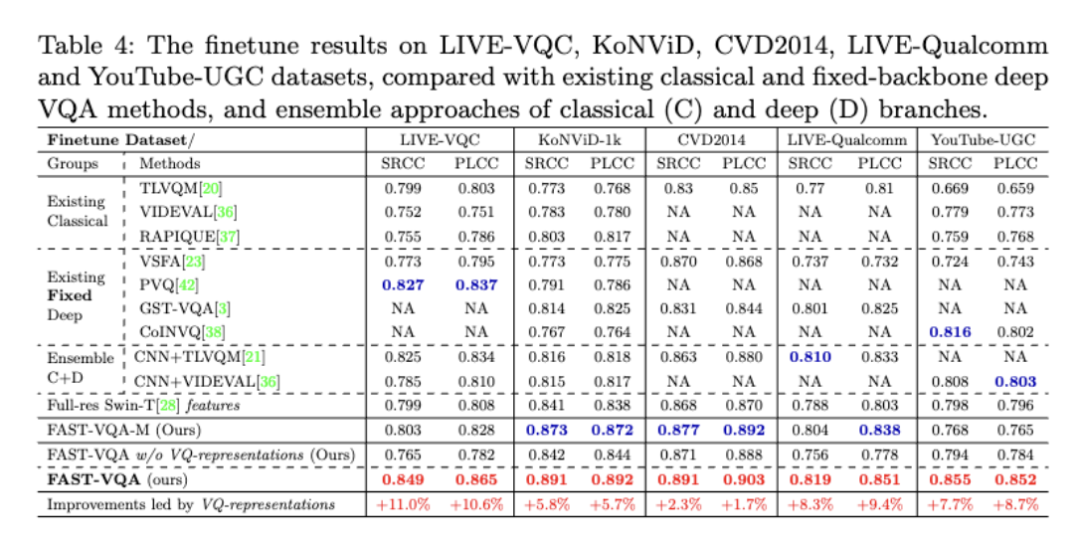
由于“碎片”采样的功劳,所采取的方案可以对骨干网络的权重进行更新,这使得FAST-VQA可以先在大型数据集上预训练以获得与视频质量相关的知识,再在小型数据集上进行调优以适应不同的场景。通过这一全新的方式,FAST-VQA在五个不同特点的小规模VQA数据集上同样达到了最优性能,且复杂度远低于参与对比的其他深度方法。
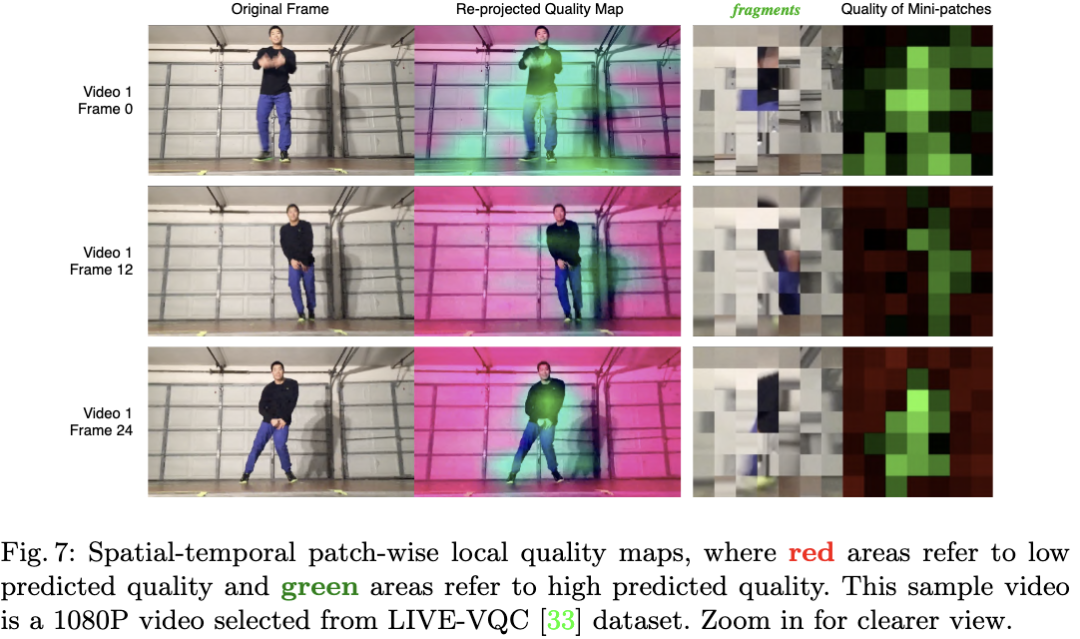
由于IP-NLR实际上对每个迷你切片进行独立的质量回归,FAST-VQA除了可以得到总的视频质量分数之外,还可以生成局部视频质量图,如下图所示。局部视频质量图进一步证明了这一方法无论是对于底层特征(例如清晰度)还是内容信息(跳舞人的手部)都具有强大的感知能力,进一步证明了这一方法的有效性。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢