

论文链接:https://arxiv.org/abs/2207.11148
项目主页:https://infinite-nature-zero.github.io/
导读
为了满足人类可以在天空中自我飞行的愿望,敢于创新的发明家们都给出了自己的答卷,从炫酷的翼装飞行再到无人机和穿越机的速度与激情,在天空中俯瞰世界的角度可谓是令人向往,观察到的自然风景也是人间绝美,这大概也是飞行这项运动本身独具的魅力吧。作为AI研究者,我们可以使用AI的方法和工具直接跳过飞行,生成飞行中所观察到的画面,这就是本文介绍的论文主题:感知视角视频合成(perceptual view generation),本文来自谷歌研究院、康奈尔大学和加州伯克利大学。提出了一种基于自监督学习的视频感知视角合成方法,可以仅通过单张图像开始生成炫酷流畅的风景穿越视频,下面是本文方法的视频生成效果,看完立马觉得手里的无人机不香了。
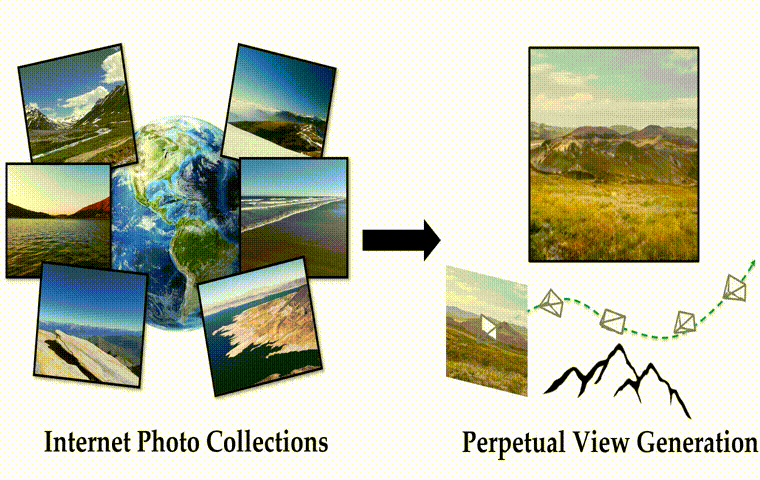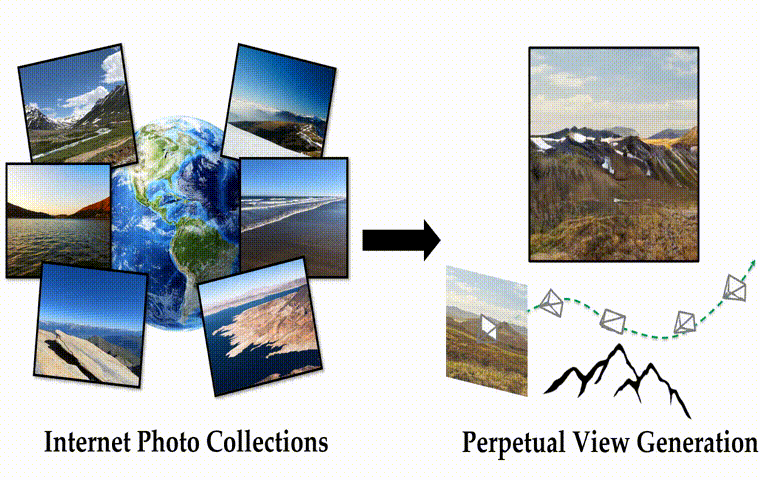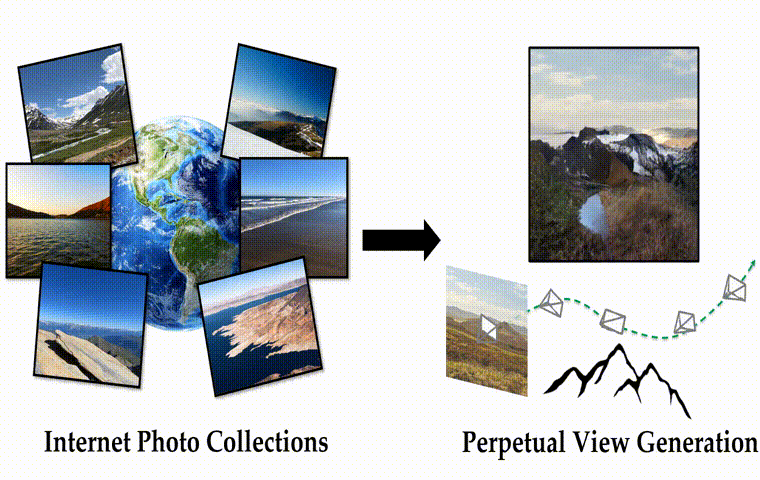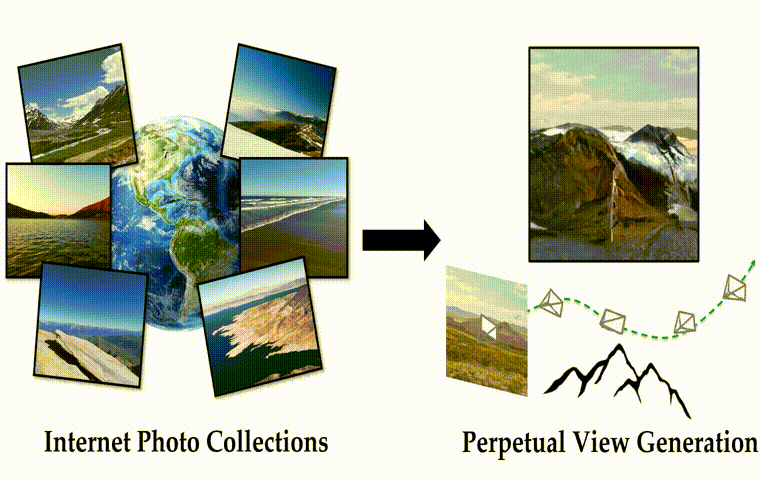
作者团队提出了一种基于自监督视图生成训练范式的算法框架InfiniteNature-Zero,通过对单张图像进行采样和渲染其中的虚拟相机轨迹,模型可以从单个视图的图像集合中学习到稳定的视图变换模式。到了测试阶段,尽管模型在训练时从未见过视频数据,却能够生成包含有数百个逼真视角转换镜头和多样性丰富的飞行视角视频。除了具有良好的观赏性,InfiniteNature-Zero生成的视频也可以应用在很多内容创建和虚拟现实应用中。
贡献
先前已有风景图像合成的工作,但大都局限于有限的静态视角合成,此外仍遵循监督学习的范式进行训练,这增大了数据集收集的难度。如果想通过之前的工作来合成具有动态视角的视频,恐怕需要更大规模的监督数据集,收集起来更加费时费力。因而本文作者开始设想,能不能仅靠静态图像来合成视频呢,因为在互联网上有海量的自然风景照片,展示了世界各地的奇妙风景,并且其中包含了包含山峰、湖泊、森林等多种自然景观,拥有更加丰富的生成元素,从数据集的角度考虑已经不成问题。关键是如何设计一种方法来模拟相机穿越视角,并通过合适的方法对未来视角进行估计,同时还需要兼顾视频中的高低频细节以及画面的真实感和多样性。
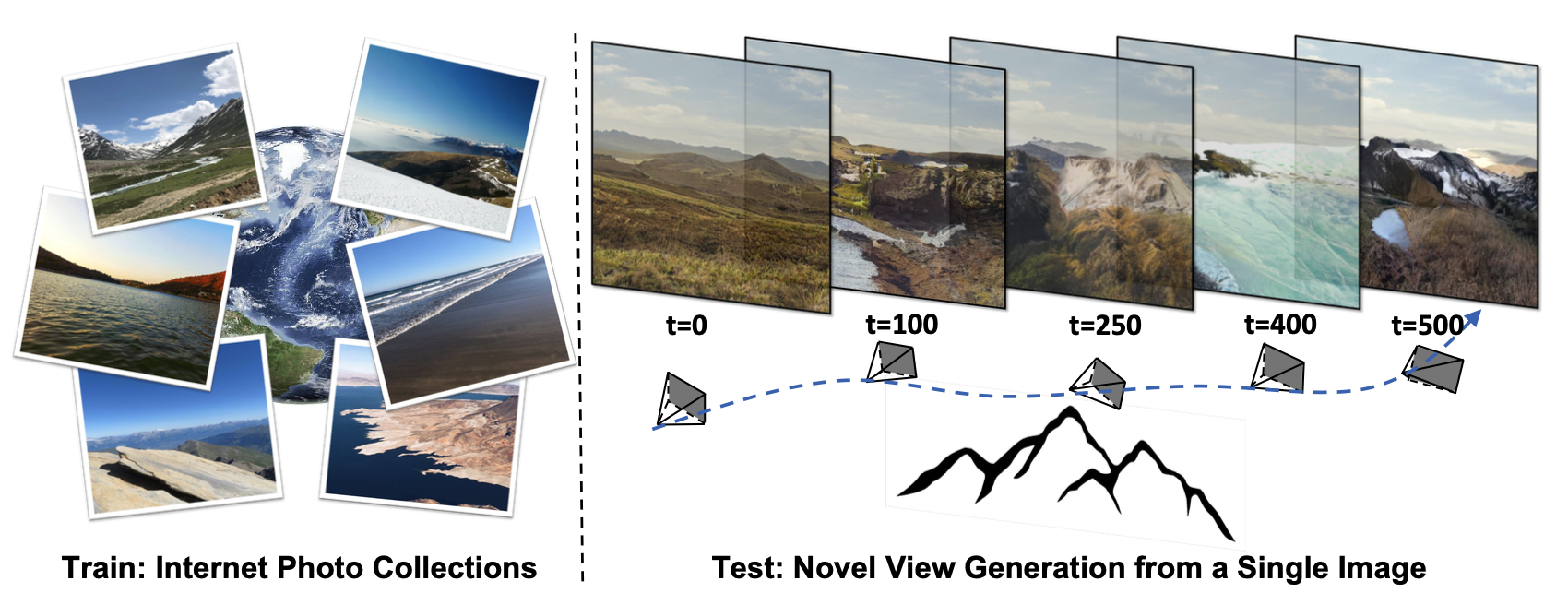
本文提出了一种仅靠单视角图像集合学习视频感知视角的算法框架InfiniteNature-Zero,无需每个场景的信息以及相机的视角信息。由于网络使用的信息非常少,因此作者团队设计了一种利用循环虚拟相机轨迹的自监督视角合成策略,在这一策略中,参与训练的结束序列帧和起始帧应该是一样的,这为网络提供了一种可供训练的监督信号。其次,为了学习时间跨度较长的新颖视图序列,作者还采用了一种基于对抗学习的视图生成训练技术,鼓励生成的虚拟视角更加逼真和稳定。
除此之外,本文方法的唯一一个要求是需要一个预训练的单目深度估计网络(monocular depth network)来计算初始帧与后续帧的视差信息,但是该深度估计网络不需要在本文的数据集上进行训练,从这个意义上来说,本文方法可以认为是完全自我监督的。因此作者将本文方法命名为InfiniteNature-Zero,即从零开始生成无限自然。
方法
3.1 问题定义及方案流程
本文中,作者将感知视角合成任务定义为如下形式:首先给定一个起始RGB图像\( I_0 \),然后指定一段随机摄像头移动轨迹 \( \left(c_{1}, c_{2}, \ldots, c_{t}, \ldots\right) \),其中摄像机视角参数 \( c_t \) 可以通过算法生成或者通过用户直接指定。随后要求模型生成与摄像机轨迹序列一一对应的图像序列\( \left(\hat{I}_{1}, \hat{I}_{2}, \ldots, \hat{I}_{t}, \ldots\right) \)。
本文所提InfiniteNature-Zero方法的关键思想是从训练图像开始采样和渲染虚拟的相机轨迹,通过估计每一帧图像的深度信息,并将其变换到下一个视图,如下图所示,作者生成了两条相机轨迹,初始时刻与变换时刻的视角变换可以清晰地通过两帧图像的深度图展示出来。此外,作者还设计了一种策略,即认为给定的虚拟相机轨迹是自身循环的,这就天然形成了起始帧和结束帧相同的设定,因而可以在这两帧之上设置重构损失作为自监督信号。这种自监督训练模型使得网络可以在视图生成过程中感知视角的几何形变和完成对细节的学习。此外,为了保证生成虚拟相机轨迹的稳定性,作者在原始视角和最终渲染图像上加入了一个对抗损失进行优化。
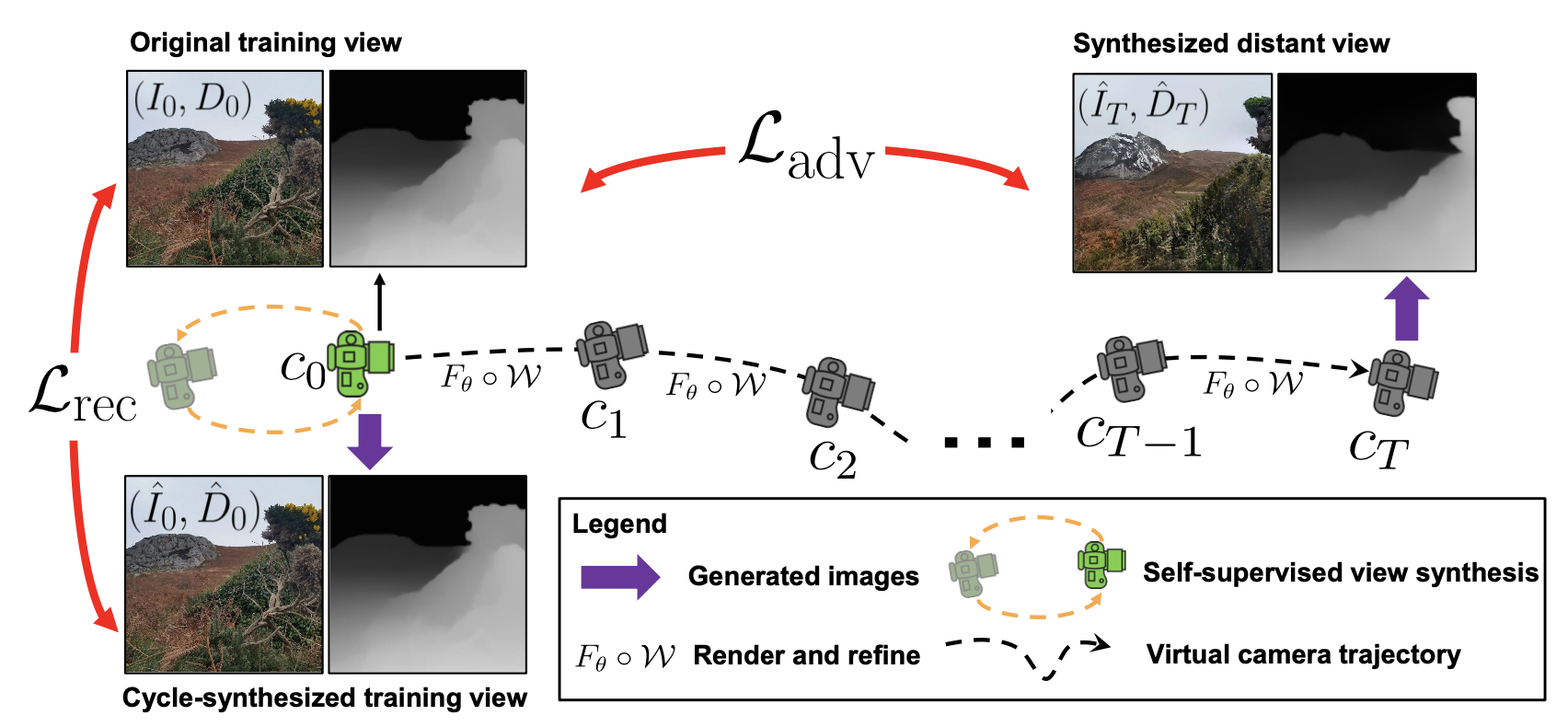
3.2 自监督视角合成
借助循环机制,本文所提自监督合成方案可以概括为:将每个已知的真实风景图像作为其之前图像的“下一个新视角”,然后使用网络模拟“前一个视角”的输入图像即可。最终将循环结束时的最终渲染视角与第一个真实视角图像计算重构自监督损失就完成了整体的步骤。而在实际实现时,我们可以考虑最简单的情况,即只需要生成出一张具有虚拟视角的图像即可构成整个循环。下图展示了这种循环渲染步骤的中间过程。
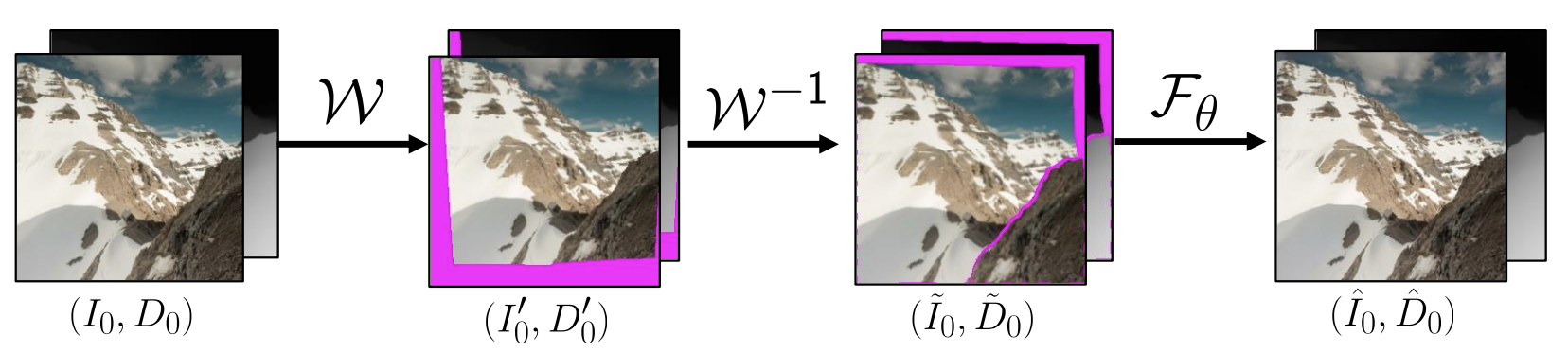
为了实现上述方案,作者首先使用一个预训练的单目深度估计网络得到起始视角图像 \( I_0 \) 的深度信息 \( D_0 \),随后在每个相机参数的最大值范围内随机采样得到一个与起始视角接近的新视角,随后通过将 \( (I_0, D_0) \)) 渲染到新视角图像 \( \left(I_{0}^{\prime}, D_{0}^{\prime}\right)=\mathcal{W}\left(\left(I_{0}, D_{0}\right), T\right) \)来合成虚拟相机轨迹,其中T 为新视角的位置参数。为了填补视角转换带来的内容缺失,作者根据深度信息 \( D_0 \) 设计了一个二进制掩码 \( M_{0}^{\prime} \) ,通过该掩码,我们可以轻松的将得到的中间变换视角转换回初始视角\( T^{-1}:\left(\tilde{I}_{0}, \tilde{D}_{0}, \tilde{M}_{0}\right)=\mathcal{W}\left(\left(I_{0}^{\prime}, D_{0}^{\prime}, M_{0}^{\prime}\right), T^{-1}\right) \) ,随后再将转换回的图像送入到一个细化网络 F 中,其对掩码和细节信息进行处理后得到 \( \left(\hat{I}_{0}, \hat{D}_{0}\right)=F_{\theta}\left(\tilde{I}_{0}, \tilde{D}_{0}\right) \),就可以与原图像 \( (I_0, D_0) \) 构成重建损失 \( \mathcal{L}_{\mathrm{rec}} \) 进行监督了。
3.3 对抗视角训练和损失函数
在构成上述的自监督训练框架之后,还需解决一个很重要的问题,如果仅靠简单的中间变化轨迹来训练的话,网络的性能会迅速退化,因此必须设置较长的相机轨迹来训练模型,才能保证生成的视图较为稳定。因此作者对给定的输入图像\( (I_0, D_0) \)随机采样虚拟相机轨迹 \( \left(c_{1}, c_{2}, \ldots, c_{T}\right) \)重复 T 次,从而产生了一系列生成视图\( \left(\hat{I}_{1}, \hat{I}_{2}, \ldots, \hat{I}_{T}\right) \),此外为了避免相机视角出现分布外的情况(例如撞击到山或者水),作者采用了一种路径规划算法来对相机路径进行采样。
在得到虚拟相机轨迹之后,作者发现仍然缺少与这些轨迹相对应的真实视图序列,到底该怎么训练模型呢?作者巧妙地设计了一个对抗损失,它仅需要训练一个判别器来判断真实图像和虚拟轨迹上合成的假图像即可。实现这一想法的一种最直接的做法是将所有 T 个预测\( \left\{\hat{I}_{t}, \hat{D}_{t}\right\}_{t=1}^{T} \) 都视为假样本,然后从真实图像中随机采样 T 个真实图像。但是这种采样策略仍然会导致训练的不稳定,因为此时生成的视角序列与随机采样得到的真实图像之间的像素分布存在着显著差异。
而我们合成的虚拟轨迹上的视角图像变化并不明显,为了解决这一问题,作者提出了一种简单有效的方法来稳定训练,具体而言,对于生成的序列,只将最后一个摄像机位置 \( c_T \)出的生成图像作为假样本,将输入图像 \( (I_0, D_0) \) 作为真实样本,这样做可以使得每一批次中的真假样本呈现出大致相似的内容和视角变化。
作者使用StyleGAN[1]模型的一个变体作为整体框架的骨干模块 \( F_{\theta} \),具体来说,\( F_{\theta} \)由一个全局编码器和一个StyleGAN生成器构成。整体生成器和判别器的损失函数为:
\( \mathcal{L}^{F}=\mathcal{L}_{\text {adv }}^{F}+\lambda_{1} \mathcal{L}_{\text {rec }}, \quad \mathcal{L}^{D}=\mathcal{L}_{\text {adv }}^{D}+\lambda_{2} \mathcal{L}_{R_{1}} \)
其中\( \mathcal{L}_{\text {adv }} \) 和\( \mathcal{L}_{\text {adv }}^{D} \) 是标准的GAN损失。\( \mathcal{L}_{\text {rec }} \) 是真实图像与其对应的循环合成视图之间的重构损失。
实验
本文的实验分别在两个包含自然风景的公共数据集上进行,其中LHQ数据集是从互联网上收集的,包含有90000多张风景照片。以及ACID数据集,该数据集是一个空中海岸线图像数据集,其中包含有相机参数丰富的自然场景数据。在实验评估的对比方法部分,作者选用了一些目前较为先进的视图和视频合成方法,包括几何视图合成方法CFVS[2]和PixelSynth[3]等方法。
随后作者分别在短距离视图合成和长距离视图合成两个任务上对方法进行了评估,并通过PSNR、SSIM、LPIPS、FID和KID指标对算法性能进行了展示。这些都是图像合成领域常用的权威指标。
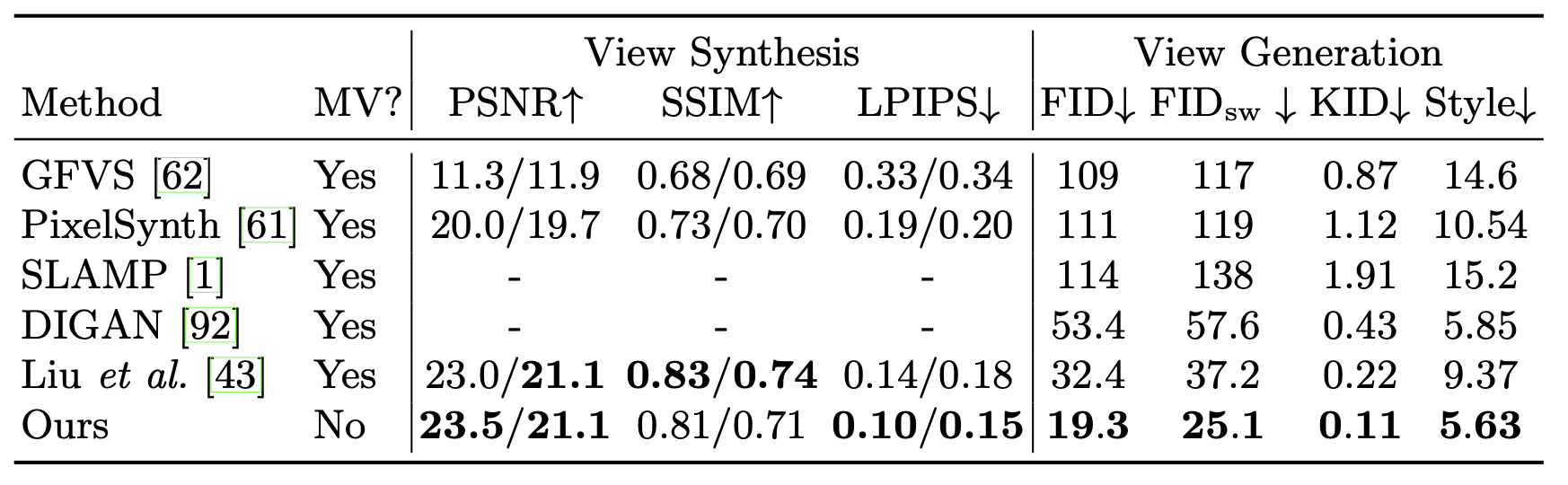
下表展示了本文所提InfiniteNature-Zero方法在ACID数据集上与其他baseline方法的对比效果,虽然InfiniteNature-Zero仅从单张图像出发,但是其几乎在所有指标上都优于其他方法,例如其在FID和KID上的分数最好,表明本文方法在生成的视图方面更加真实,同时有很好的泛化能力。
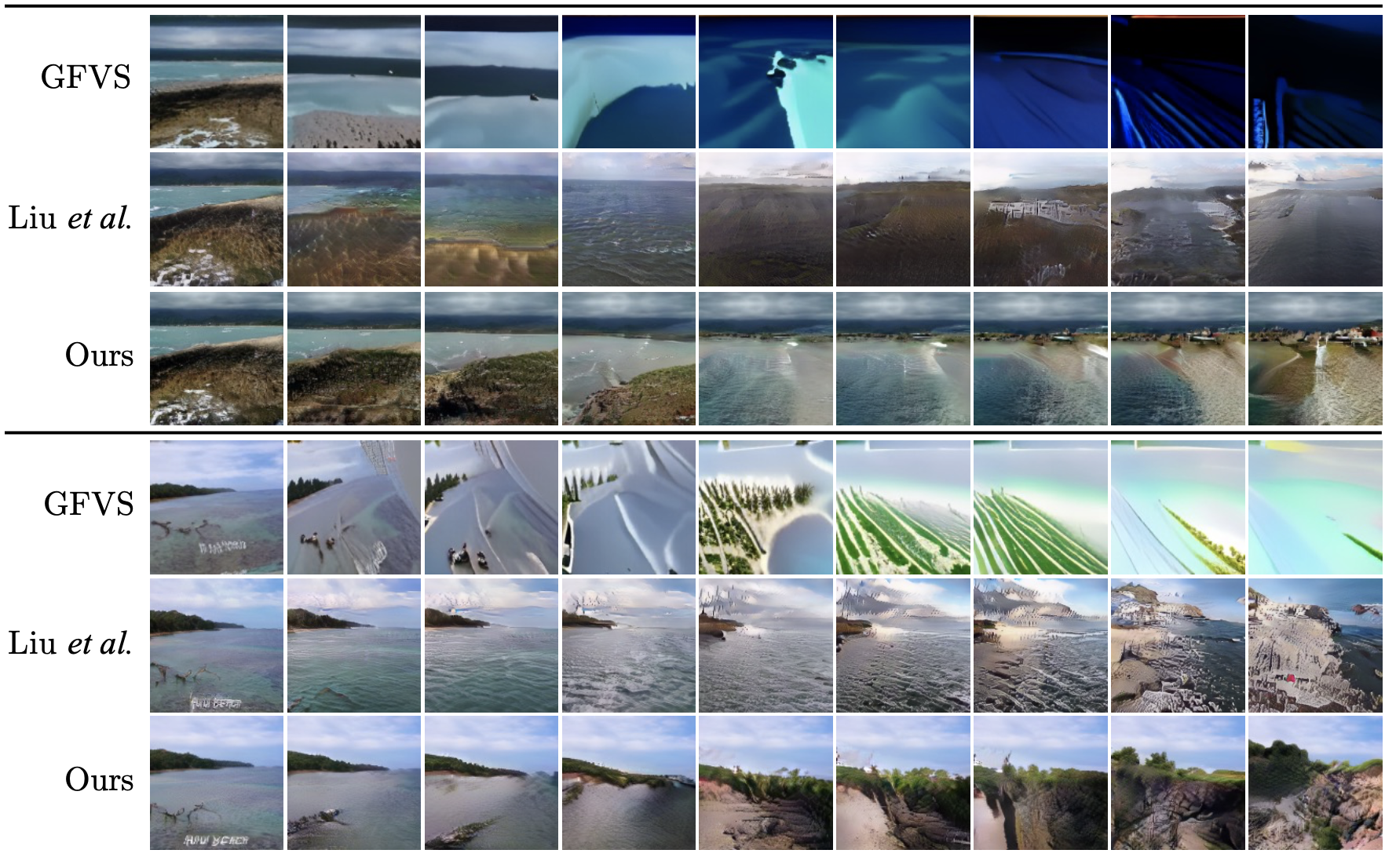
下图展示了本文方法与其他两个baseline方法在ACID数据集上的视觉对比结果。当原始输入和生成视角差距较大时,GFVS方法会迅速退化,而本文方法可以通过增加中间步骤的视图轨迹来缓解这一点,相比之下,本文方法不仅可以生成与起始图像更加一致的新视角,也可以有效的提高合成质量和真实感。
另外作者还展示了一些生成的视频样例如下:


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢