
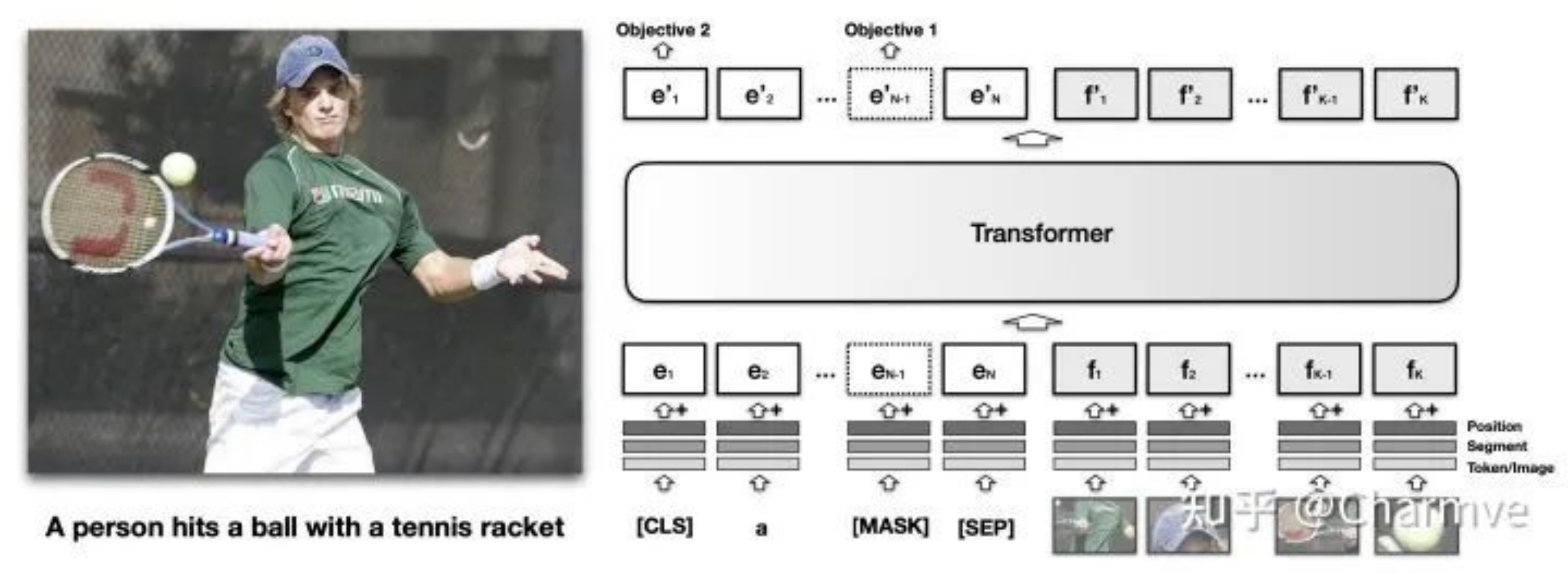
 图 1. VisualBERT 在文本和图像嵌入的组合上进行了训练。(图片来源:Li et al. 2019)
图 1. VisualBERT 在文本和图像嵌入的组合上进行了训练。(图片来源:Li et al. 2019)
与BERT 中的文本嵌入类似,VisualBERT 中的每个视觉嵌入也总结了三种嵌入,标记化特征Fo, 分割嵌入FsFs和位置嵌入Fp,准确地说:
- Fo是由卷积神经网络为图像的边界区域计算的视觉特征向量;
- Fs是一个段嵌入,用于指示嵌入是否用于视觉而不是文本;
- Fp是用于对齐边界区域顺序的位置嵌入。
该模型在 MS COCO 图像标题数据集上进行训练,文本和图像作为输入来预测文本标题,使用两个基于视觉的语言模型目标:
- 传销与图像。该模型需要预测被屏蔽的文本标记,而图像嵌入总是不被屏蔽。
- 句子图像预测。当提供一张图片和两个相关的标题时,两个标题中的一个可能是一个随机不相关的标题,概率为 50%。要求模型区分这两种情况。
根据消融实验,最重要的配置是在早期将视觉信息融合到转换器层中,并在 COCO 字幕数据集上预训练模型。从预训练的 BERT 初始化和采用句子图像预测训练目标的影响相对较小。

图 2 VisualBERT 在 NLVR 上的消融研究结果。(图片来源:Li et al. 2019)
VisualBERT 当时在 NLVR 和 Flickr30K 上的表现优于 SoTA,但在 VQA 上与 SoTA 仍有一些性能差距。
SimVLM (Simple Visual Language Model; Wang et al. 2022 ) 是一个简单的前缀语言模型,其中前缀序列像 BERT 一样使用双向注意力进行处理,但主输入序列像GPT一样只有因果注意力。图像被编码为前缀标记,这样模型就可以充分利用视觉信息,然后以自回归方式生成相关文本。
受ViT和CoAtNet的启发,SimVLM 将图像分割成更小的块,形成扁平的 1D 块序列。他们使用由 ResNet 的前 3 个块组成的卷积阶段来提取上下文补丁,并且发现这种设置比简单的线性投影效果更好。
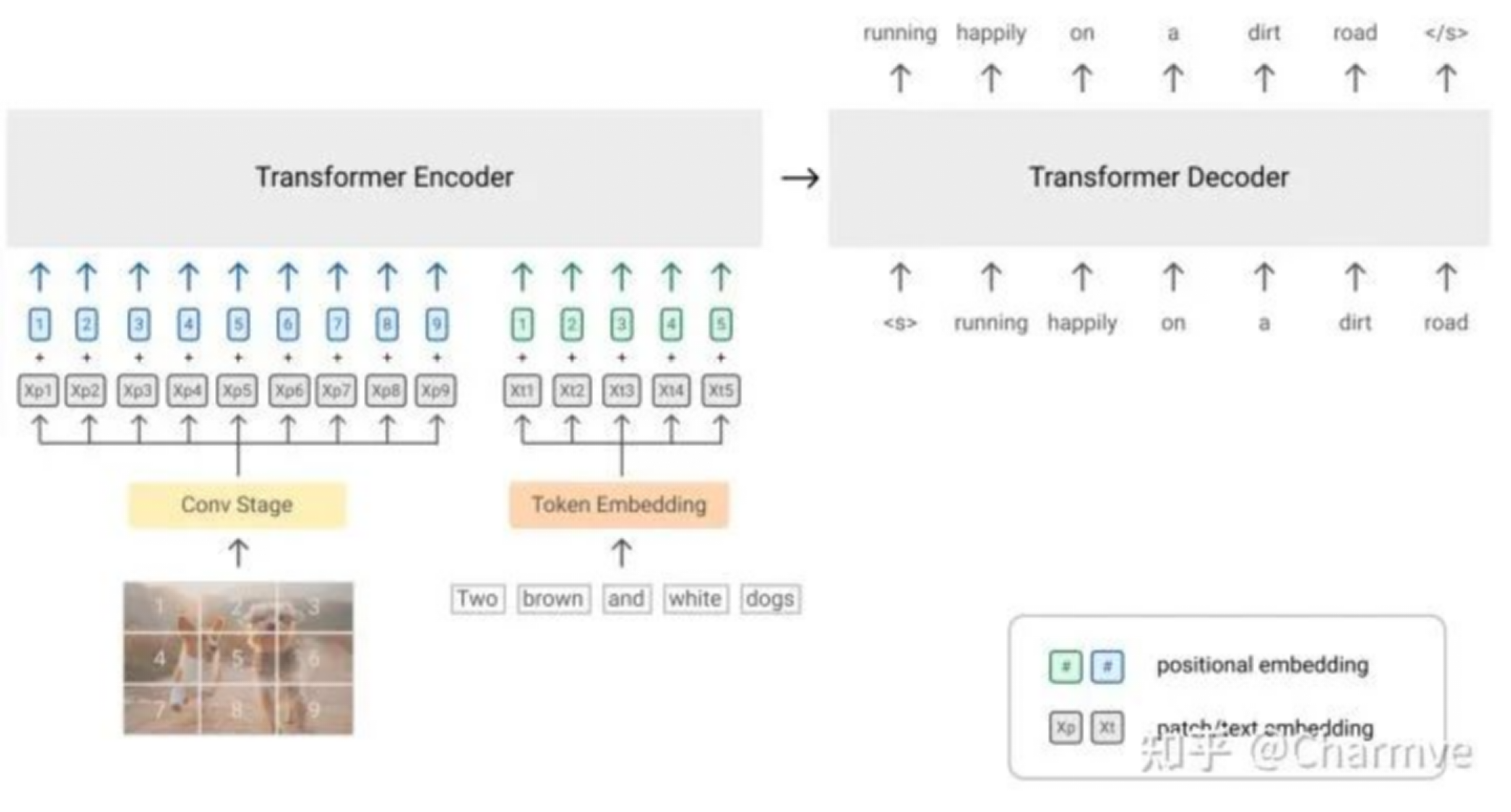
图 3. SimVLM 的训练架构,其中图像块由交叉注意编码器处理,文本解码器具有因果注意。(图片来源:Wang et al. 2022)
SimVLM 的训练数据由来自 ALIGN ( Jia et al. 2021 )的大量图像-文本对和来自 C4 数据集的纯文本数据 ( Raffel et al. 2019 ) 组成。他们在每批中混合了两个预训练数据集,包含 4,096 个图像-文本对 (ALIGN) 和 512 个纯文本文档 (C4)。
根据消融研究,重要的是同时拥有图像文本和纯文本数据进行训练。PrefixLM 目标优于跨度损坏和幼稚 LM。
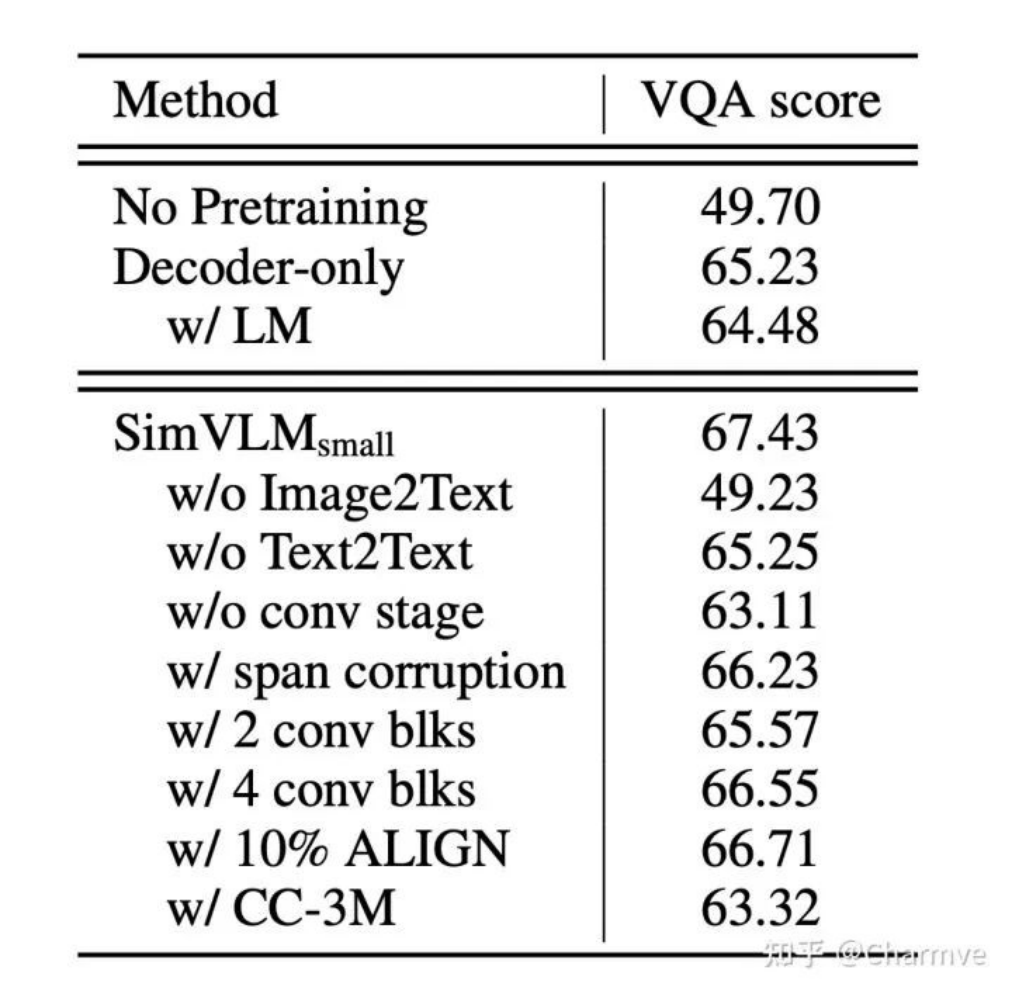
图 4 SimVLM 在 VQA 上的消融研究结果。(图片来源:Wang et al. 2022)
CM3 (Causally-Masked Multimodal Modeling; Aghajanyan, et al. 2022 ) 是一种超文本语言模型,学习生成 CC-NEWS 和维基百科文章的大型 HTML 网页的内容(超文本标记、超链接和图像)。生成的 CM3 模型可以生成丰富的结构化、多模态输出,同时以任意掩码文档上下文为条件。
在架构方面,CM3 是一个自回归模型。然而,为了结合因果和屏蔽语言建模,CM3 还屏蔽了少量长标记跨度,并尝试在序列末尾生成它们。
图 5. 因果屏蔽语言模型如何工作的说明。(图片来源:Aghajanyan 等人,2022 年)
CM3 的训练数据集包含接近 1T 的 Web 数据。在预处理过程中,首先下载图像src并将其大小调整为 256 x 256,并进行随机裁剪。然后它们由VQVAE-GAN进行标记,每张图像产生 256 个标记。这些用空格连接的标记被插入回src属性中。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢