
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于模型的离线选项、深度学习稀疏专家模型综述、嵌入空间Transformer分析、用GFlowNets统一生成式模型、选择性标注让语言模型成为更好的少样本学习器、基于掩码视觉建模的端到端视频-语言Transformer实证研究、大规模深度学习网络拓扑、常识性问答的大规模精细化生成、基于特征点引导GAN的人脸表情翻译
1、[LG] MO2: Model-Based Offline Options
S Salter, M Wulfmeier, D Tirumala, N Heess, M Riedmiller, R Hadsell, D Rao
[DeepMind]
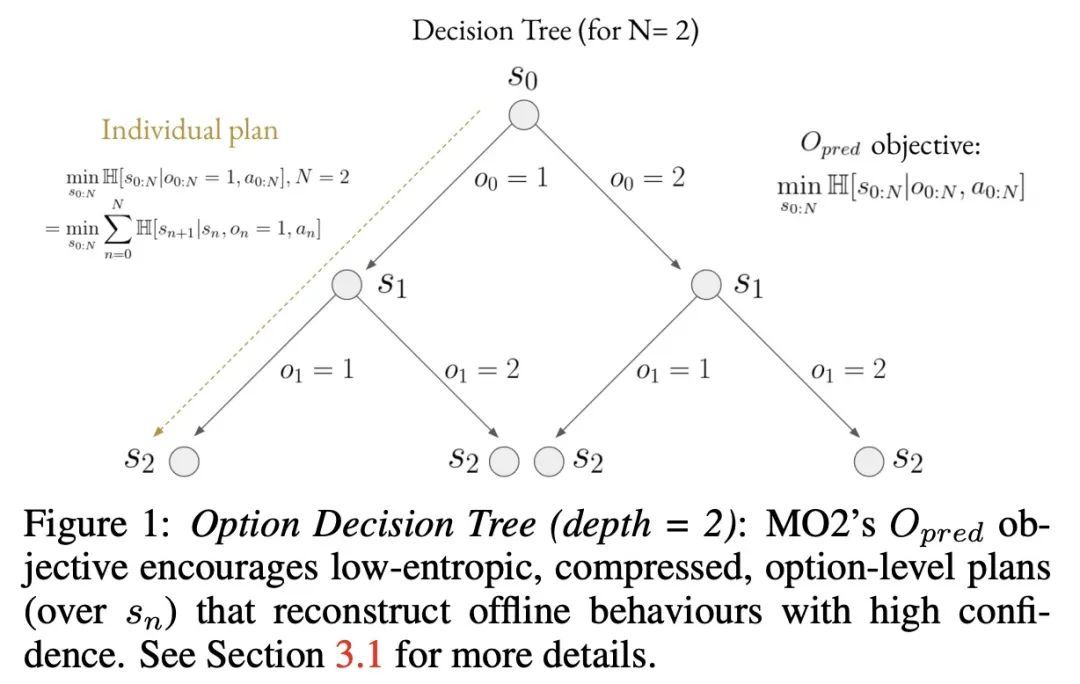
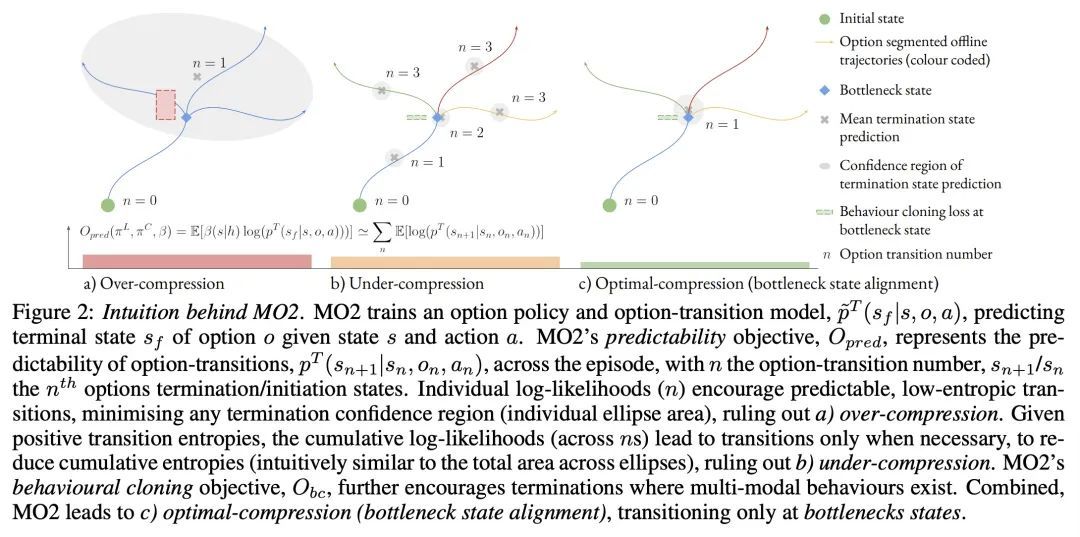
MO2: 基于模型的离线选项。从过去的经验中发现有用的行为,并将其迁移到新任务的能力,被认为是自然体现智能的一个核心组成部分。受神经科学的启发,发现在瓶颈状态下的切换行为一直是人们追求的目标,以归纳跨任务的最小描述长度的规划。之前的方法要么只支持在线的、策略性的、瓶颈状态的发现,限制了样本效率,要么是离散的状态动作域,限制了适用性。为解决该问题,本文提出基于模型的离线选项(MO2),一种离线后知框架,支持在连续状态动作空间中进行样本高效的瓶颈选项发现。一旦在源域上离线学习了瓶颈选项,就会在线迁移以改善迁移域上的探索和价值估计。实验表明,在具有稀疏、延迟奖励的复杂长跨度连续控制任务中,MO2的特性是至关重要的,使其性能超过最近其他选项学习方法。额外的消融进一步证明了其对选项可预测性和信用分配的影响。
The ability to discover useful behaviours from past experience and transfer them to new tasks is considered a core component of natural embodied intelligence. Inspired by neuroscience, discovering behaviours that switch at bottleneck states have been long sought after for inducing plans of minimum description length across tasks. Prior approaches have either only supported online, on-policy, bottleneck state discovery, limiting sample-efficiency, or discrete state-action domains, restricting applicability. To address this, we introduce Model-Based Offline Options (MO2), an offline hindsight framework supporting sample-efficient bottleneck option discovery over continuous state-action spaces. Once bottleneck options are learnt offline over source domains, they are transferred online to improve exploration and value estimation on the transfer domain. Our experiments show that on complex long-horizon continuous control tasks with sparse, delayed rewards, MO2's properties are essential and lead to performance exceeding recent option learning methods. Additional ablations further demonstrate the impact on option predictability and credit assignment.
https://arxiv.org/abs/2209.01947


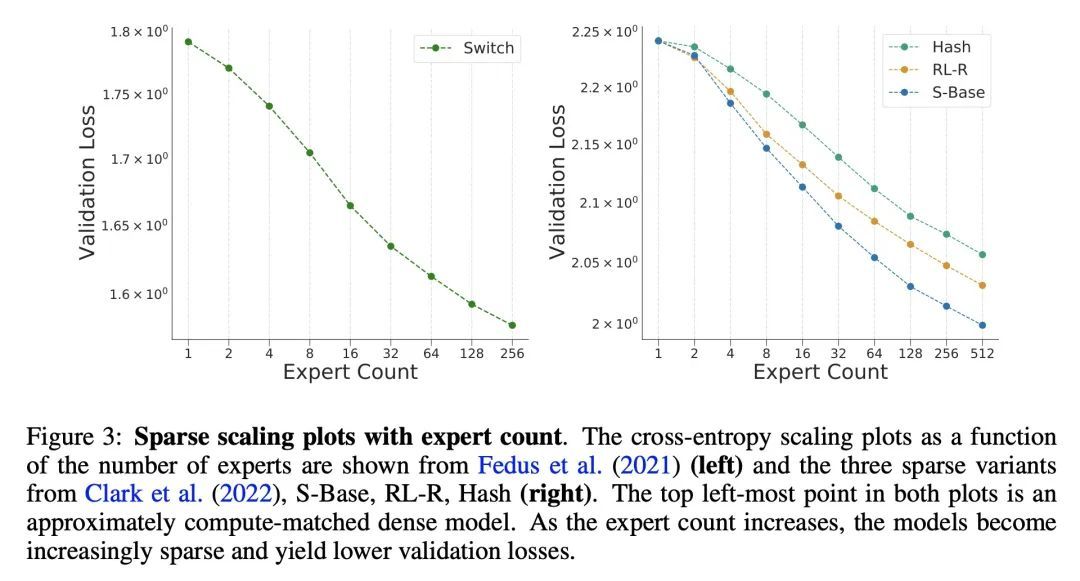
2、[LG] A Review of Sparse Expert Models in Deep Learning
W Fedus, J Dean, B Zoph
[Google Brain & Google Research]
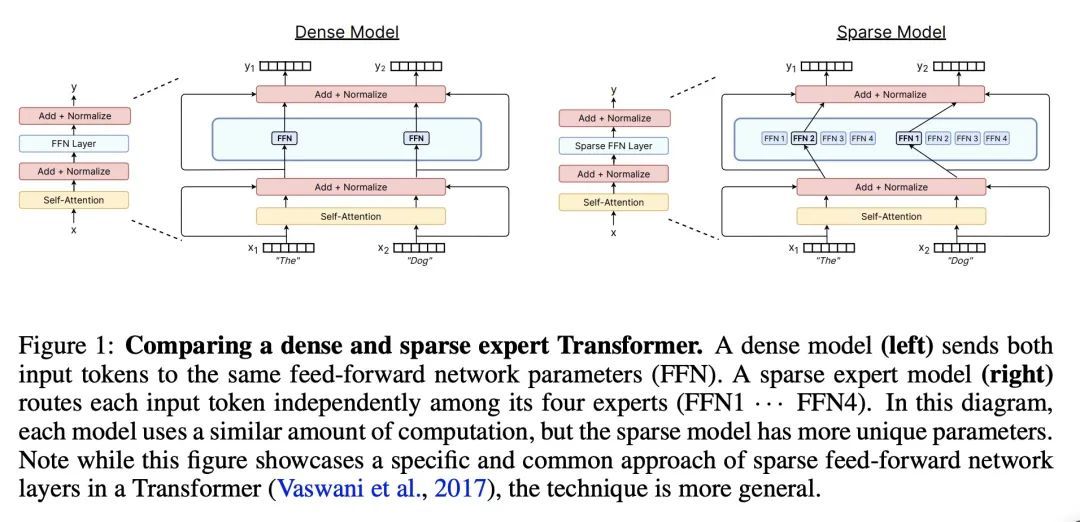
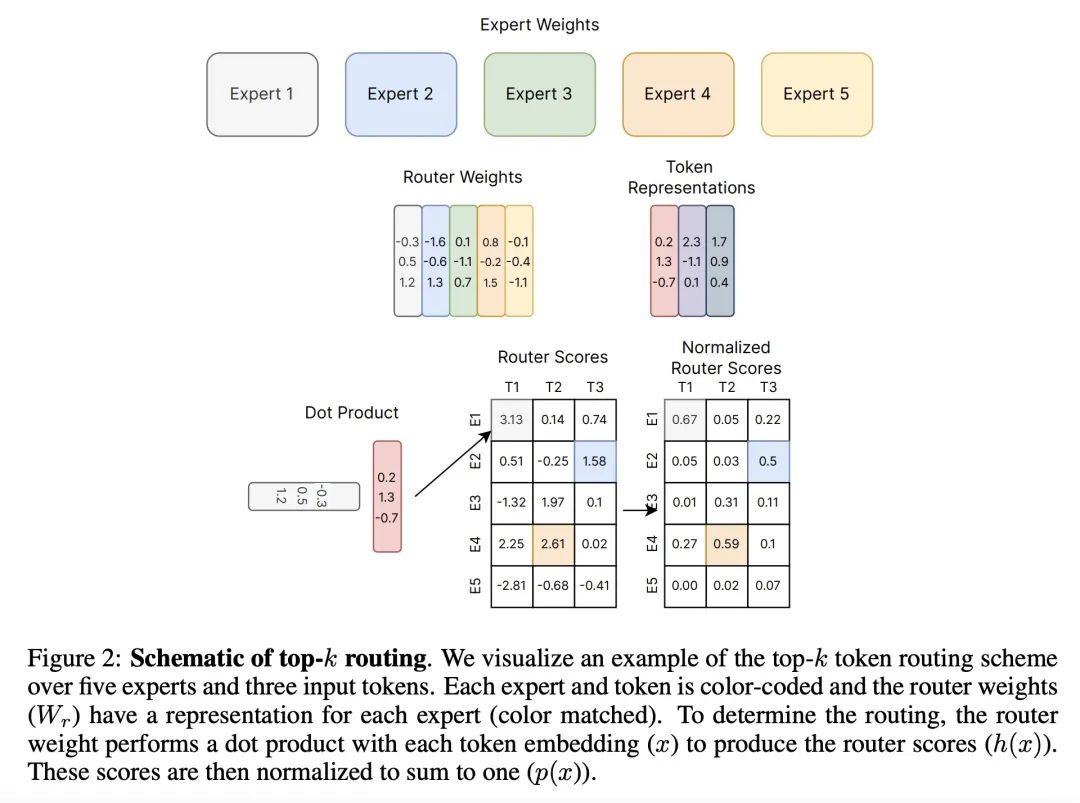
深度学习稀疏专家模型综述。稀疏专家模型是个有30年历史的概念,作为深度学习的一种流行架构重新出现。这类架构包括Mixture-of-Experts、Switch Transformers、Routing Networks、BASE层等,它们的统一理念是每个例子都是由参数的一个子集作用的。通过这样做,稀疏程度将参数数量与每个实例的计算量相分离,从而允许建立极其庞大但高效的模型。由此产生的模型在不同的领域,如自然语言处理、计算机视觉和语音识别,都有明显的改进。本文回顾了稀疏专家模型的概念,提供了常见算法的基本描述,介绍了深度学习时代的进展,并在最后强调了未来工作的领域。
Sparse expert models are a thirty-year old concept re-emerging as a popular architecture in deep learning. This class of architecture encompasses Mixture-of-Experts, Switch Transformers, Routing Networks, BASE layers, and others, all with the unifying idea that each example is acted on by a subset of the parameters. By doing so, the degree of sparsity decouples the parameter count from the compute per example allowing for extremely large, but efficient models. The resulting models have demonstrated significant improvements across diverse domains such as natural language processing, computer vision, and speech recognition. We review the concept of sparse expert models, provide a basic description of the common algorithms, contextualize the advances in the deep learning era, and conclude by highlighting areas for future work.
https://arxiv.org/abs/2209.01667

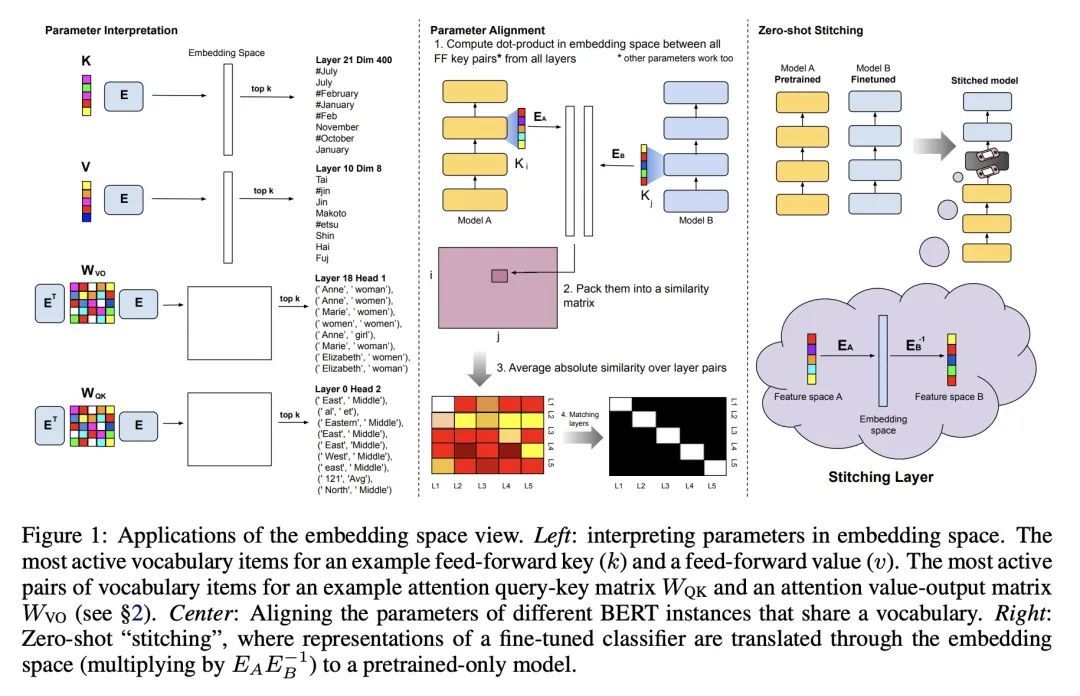
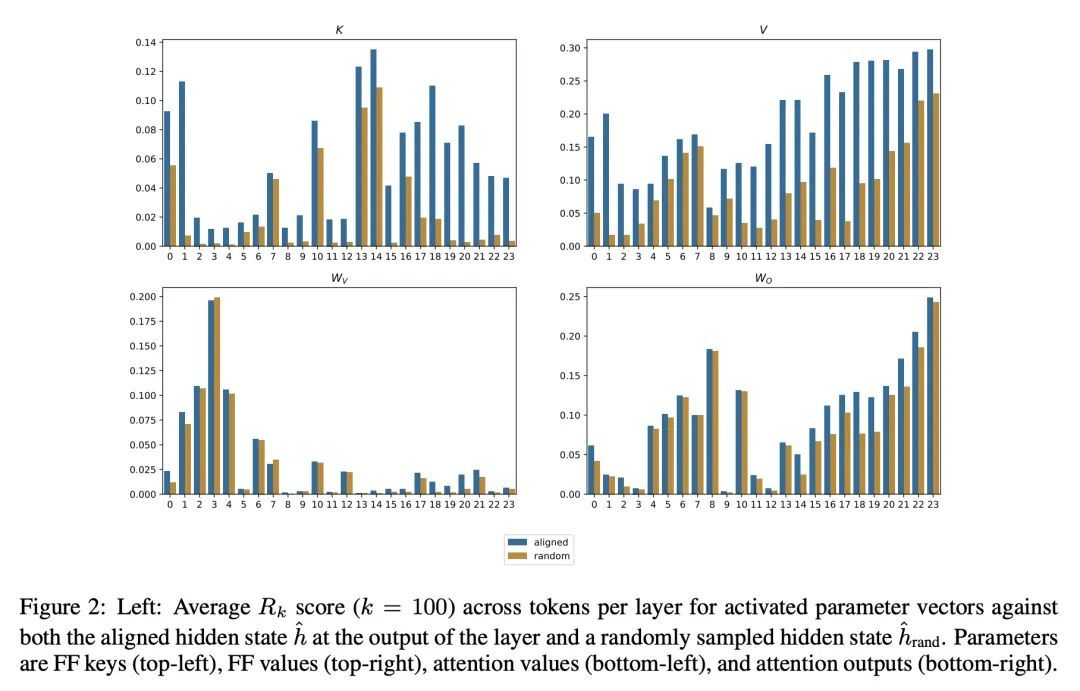
3、[CL] Analyzing Transformers in Embedding Space
G Dar, M Geva, A Gupta, J Berant
[Tel-Aviv University & Allen Institute for Artificial Intelligence]
嵌入空间Transformer分析。对基于Transformer的模型的理解,已经引起了极大的关注,因为它们是整个机器学习的最新技术进步的核心。虽然大多数可解释性方法依赖于在输入上运行模型,但最近的工作表明,对于某些Transformer参数和两层注意力网络来说,zero-pass方法,即不通过前向/后向通道直接解释参数是可行的。本文提出一种理论分析,即训练好的Transformer的所有参数都通过投射到嵌入空间来解释,也就是它们所操作的词汇项的空间。本文推导出一种简单的理论框架来支持所提出的论点,并为其有效性提供了大量证据。首先,一个经验性的分析表明,预训练和微调模型的参数都可以在嵌入空间中得到解释。其次,本文提出所提框架的两个应用:(a)对齐共享词汇不同模型的参数,以及(b)通过"翻译"微调分类器的参数到只经过预训练的不同模型的参数,构建一个无需训练的分类器。总的来说,本文发现为解释方法打开了大门,这些方法至少部分地从模型的细节中抽象出来,只在嵌入空间中操作。
Understanding Transformer-based models has attracted significant attention, as they lie at the heart of recent technological advances across machine learning. While most interpretability methods rely on running models over inputs, recent work has shown that a zero-pass approach, where parameters are interpreted directly without a forward/backward pass is feasible for some Transformer parameters, and for two-layer attention networks. In this work, we present a theoretical analysis where all parameters of a trained Transformer are interpreted by projecting them into the embedding space, that is, the space of vocabulary items they operate on. We derive a simple theoretical framework to support our arguments and provide ample evidence for its validity. First, an empirical analysis showing that parameters of both pretrained and fine-tuned models can be interpreted in embedding space. Second, we present two applications of our framework: (a) aligning the parameters of different models that share a vocabulary, and (b) constructing a classifier without training by ``translating'' the parameters of a fine-tuned classifier to parameters of a different model that was only pretrained. Overall, our findings open the door to interpretation methods that, at least in part, abstract away from model specifics and operate in the embedding space only.
https://arxiv.org/abs/2209.02535


4、[LG] Unifying Generative Models with GFlowNets
D Zhang, R T. Q. Chen, N Malkin, Y Bengio
[Mila & Facebook AI Research]
用GFlowNets统一生成式模型。已经有很多深度生成式模型的框架,每个框架都有自己的特定训练算法和推理方法。本文就现有的深度生成式模型和GFlowNet框架之间的联系做了一个简短的说明,揭示了它们重叠的特征,并通过马尔科夫轨迹学习的视角提供了一个统一观点。这为统一训练和推理算法提供了一种手段,并为构建生成式模型的聚合提供了一条途径。
There are many frameworks for deep generative modeling, each often presented with their own specific training algorithms and inference methods. We present a short note on the connections between existing deep generative models and the GFlowNet framework, shedding light on their overlapping traits and providing a unifying viewpoint through the lens of learning with Markovian trajectories. This provides a means for unifying training and inference algorithms, and provides a route to construct an agglomeration of generative models.
https://arxiv.org/abs/2209.02606

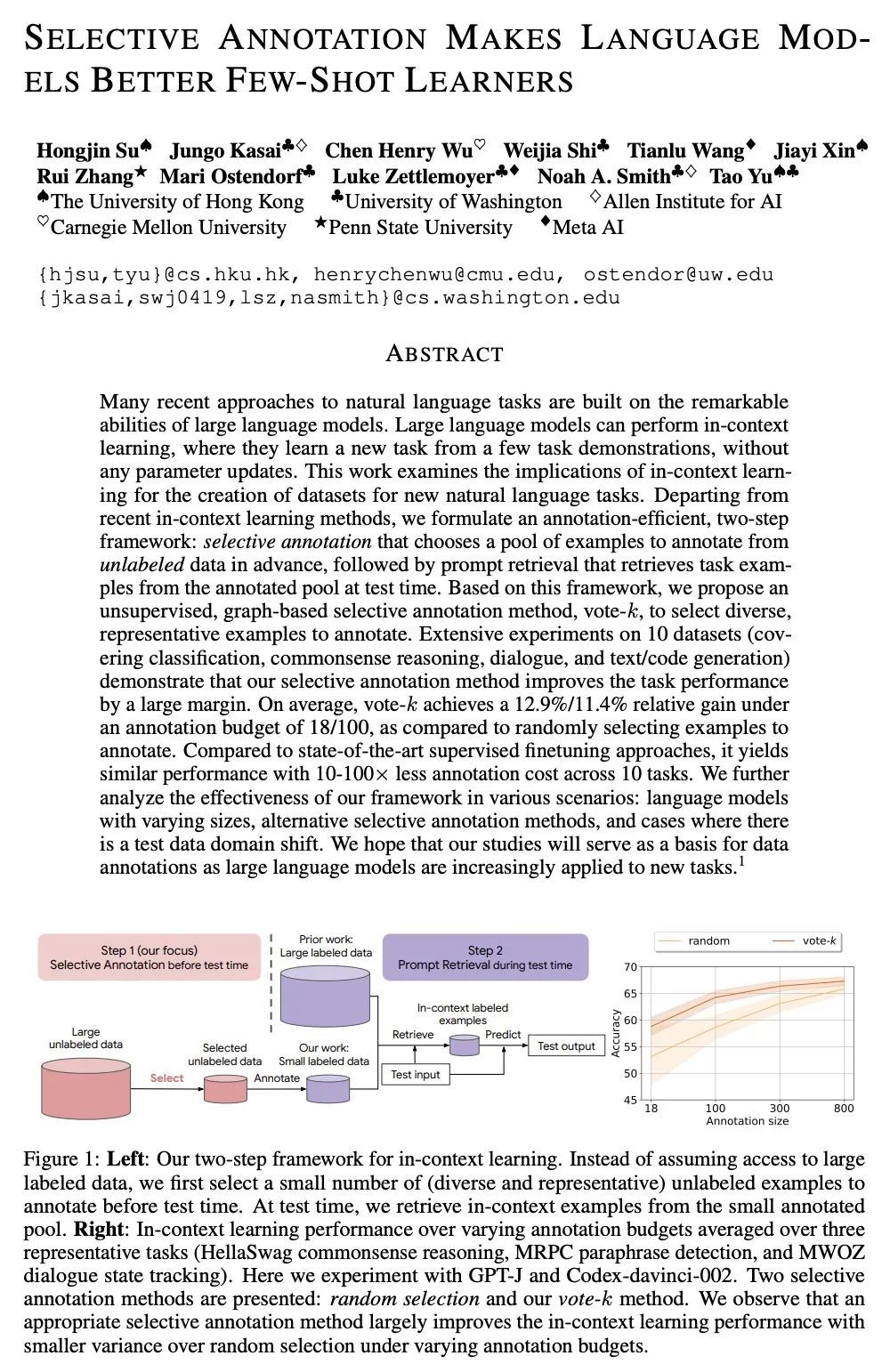
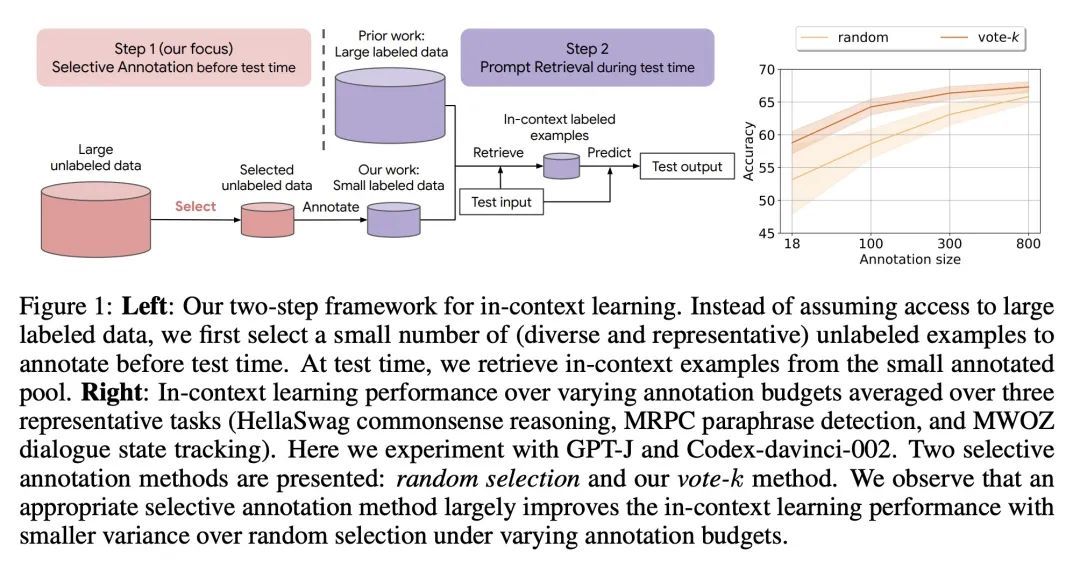
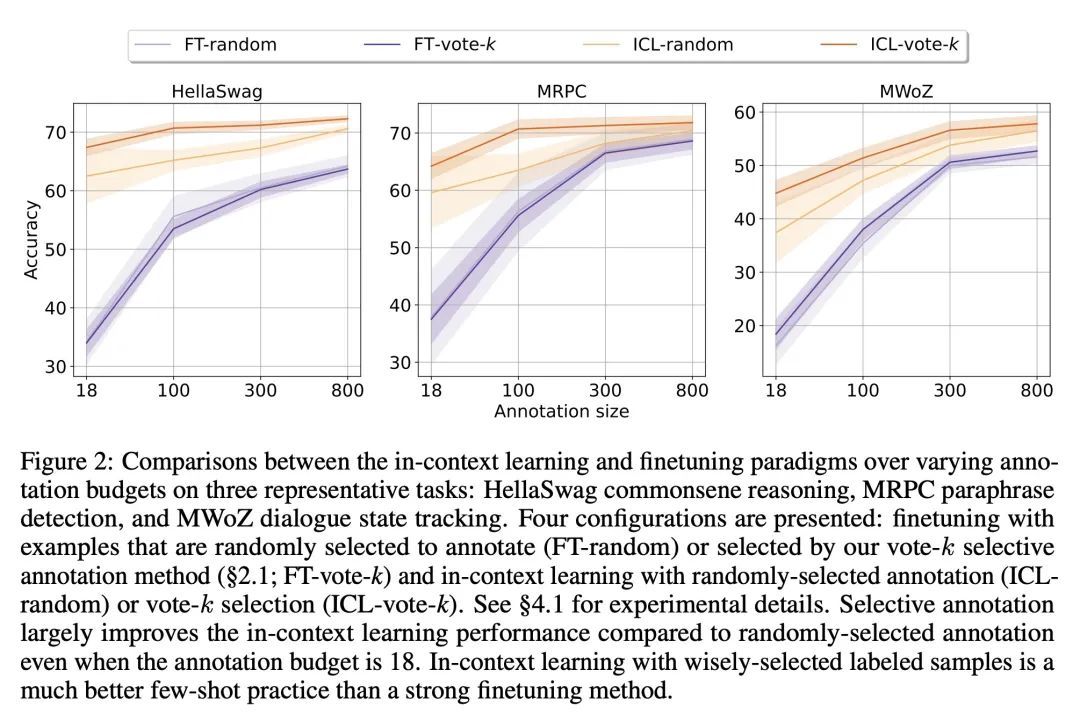
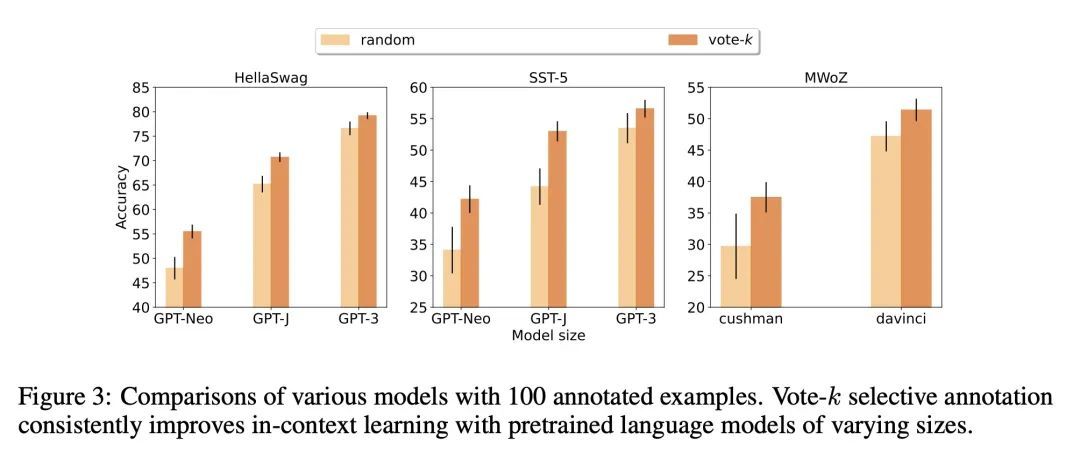
5、[CL] Selective Annotation Makes Language Models Better Few-Shot Learners
H Su, J Kasai, C H Wu, W Shi...
[The University of Hong KongUniversity of Washington & CMU & Penn State University & Meta AI]
选择性标注让语言模型成为更好的少样本学习器。最近许多处理自然语言任务的方法都建立在大型语言模型的卓越能力之上。大型语言模型可以进行上下文学习,从一些任务演示中学习新的任务,而不需要任何参数更新。本文研究了上下文学习对创建新的自然语言任务的数据集的影响。从最近的上下文学习方法出发,本文制定了一种标注高效的两步框架:选择性标注,事先从未标记数据中选择一个样本池进行标注,然后进行提示检索,在测试时从标注池中检索任务样本。基于该框架,本文提出一种无监督的、基于图的选择性标注方法voke-k,来选择不同的、有代表性的样本来进行标注。在10个数据集(涵盖分类、常识推理、对话和文本/代码生成)上进行的广泛实验表明,所提出的选择性标注方法在很大程度上提高了任务性能。平均来说,在18/100的标注预算下,vote-k实现了12.9%/11.4%的相对收益,与随机选择标注的样本相比。与最先进的有监督微调方法相比,在10个任务中以10-100倍少的标注成本获得了类似的性能。本文进一步分析了该框架在各种情况下的有效性:具有不同规模的语言模型、替代性的选择性标注方法,以及存在测试数据域漂移的情况。
Many recent approaches to natural language tasks are built on the remarkable abilities of large language models. Large language models can perform in-context learning, where they learn a new task from a few task demonstrations, without any parameter updates. This work examines the implications of in-context learning for the creation of datasets for new natural language tasks. Departing from recent in-context learning methods, we formulate an annotation-efficient, two-step framework: selective annotation that chooses a pool of examples to annotate from unlabeled data in advance, followed by prompt retrieval that retrieves task examples from the annotated pool at test time. Based on this framework, we propose an unsupervised, graph-based selective annotation method, voke-k, to select diverse, representative examples to annotate. Extensive experiments on 10 datasets (covering classification, commonsense reasoning, dialogue, and text/code generation) demonstrate that our selective annotation method improves the task performance by a large margin. On average, vote-k achieves a 12.9%/11.4% relative gain under an annotation budget of 18/100, as compared to randomly selecting examples to annotate. Compared to state-of-the-art supervised finetuning approaches, it yields similar performance with 10-100x less annotation cost across 10 tasks. We further analyze the effectiveness of our framework in various scenarios: language models with varying sizes, alternative selective annotation methods, and cases where there is a test data domain shift. We hope that our studies will serve as a basis for data annotations as large language models are increasingly applied to new tasks.
https://arxiv.org/abs/2209.01975
另外几篇值得关注的论文:
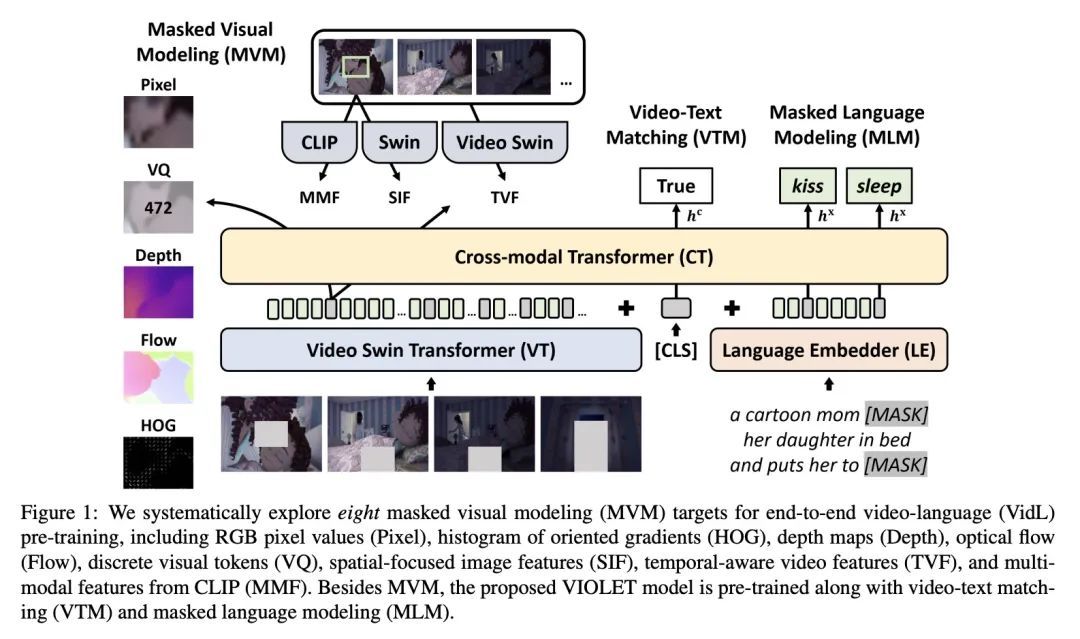
[CV] An Empirical Study of End-to-End Video-Language Transformers with Masked Visual Modeling基于掩码视觉建模的端到端视频-语言Transformer实证研究
T Fu, L Li, Z Gan, K Lin, W Y Wang, L Wang, Z Liu
[UC Santa Barbara & Microsoft]
https://arxiv.org/abs/2209.01540

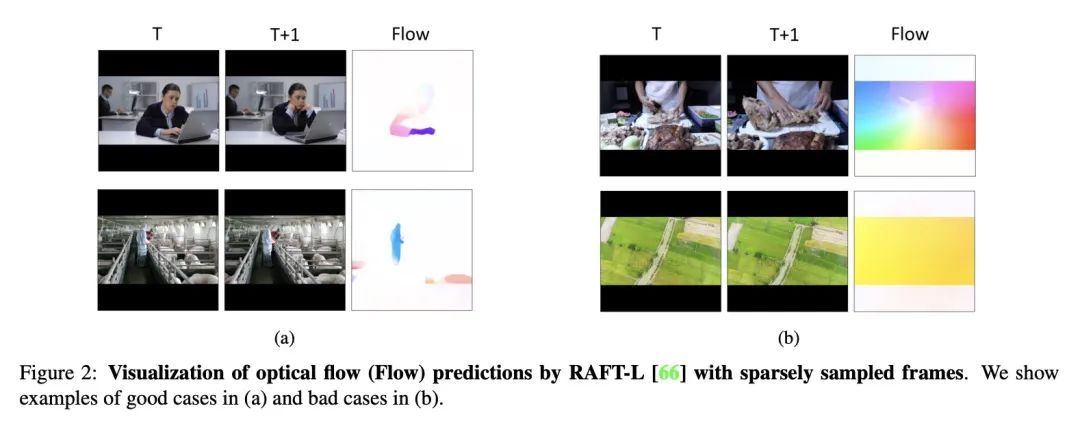
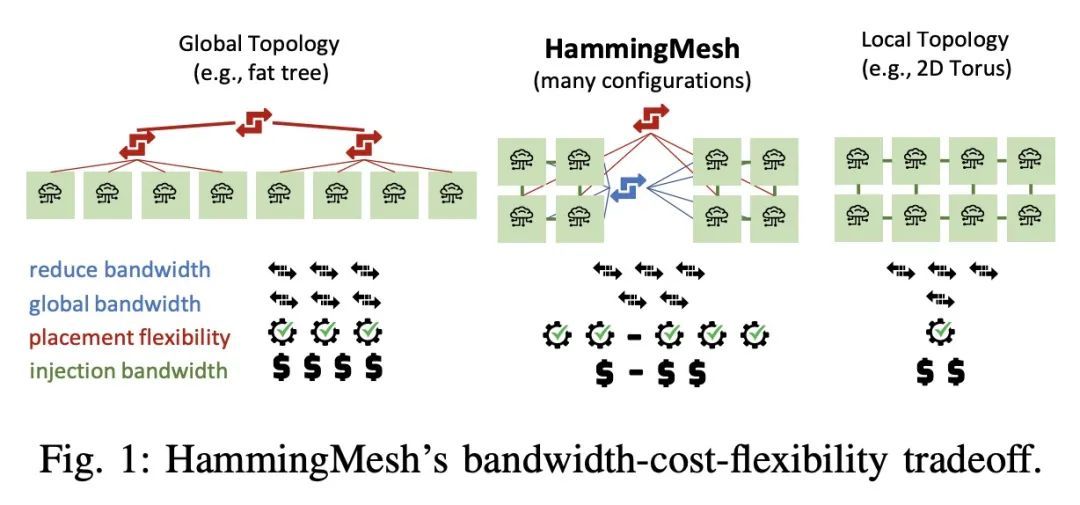
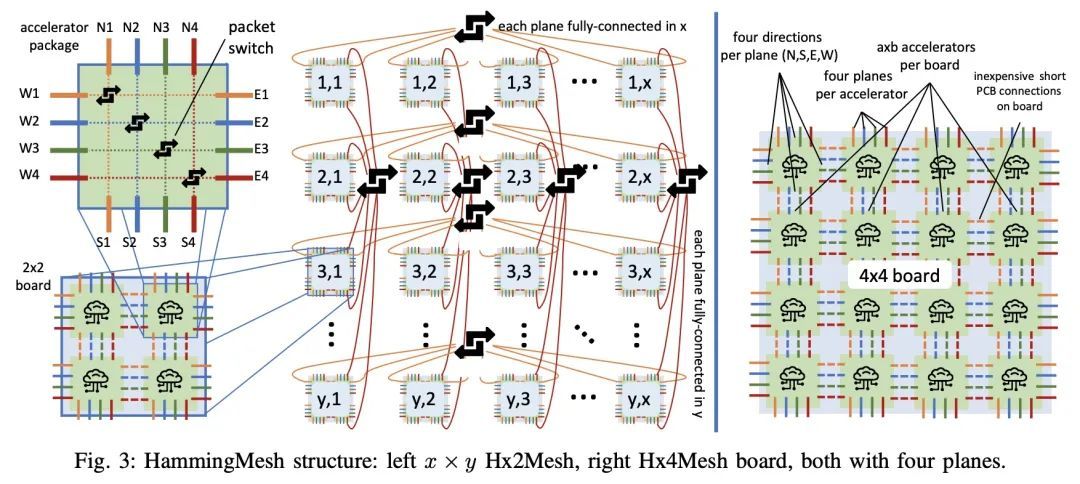
[LG] HammingMesh: A Network Topology for Large-Scale Deep Learning
HammingMesh:大规模深度学习网络拓扑
T Hoefler, T Bonato, D D Sensi, S D Girolamo, S Li, M Heddes, J Belk, D Goel, M Castro, S Scott
[ETH Zurich & Microsoft Corporation]
https://arxiv.org/abs/2209.01346

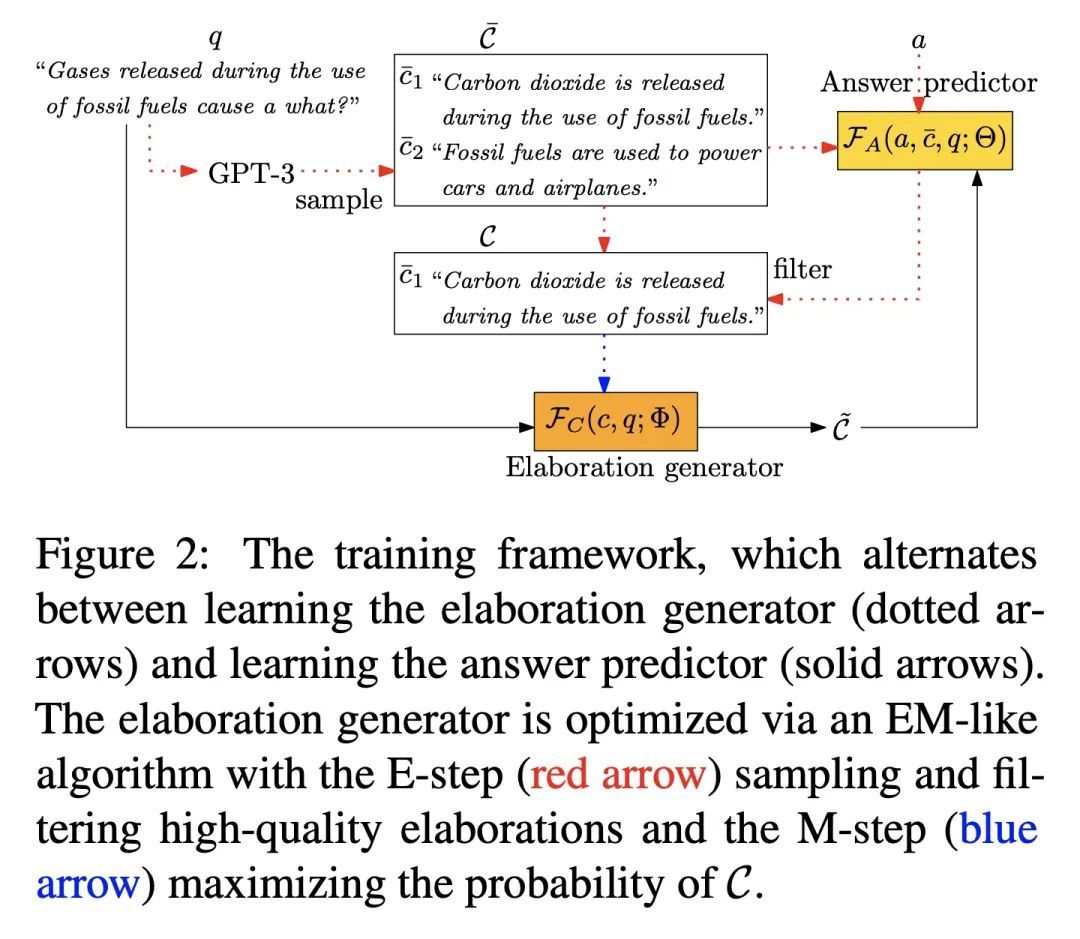
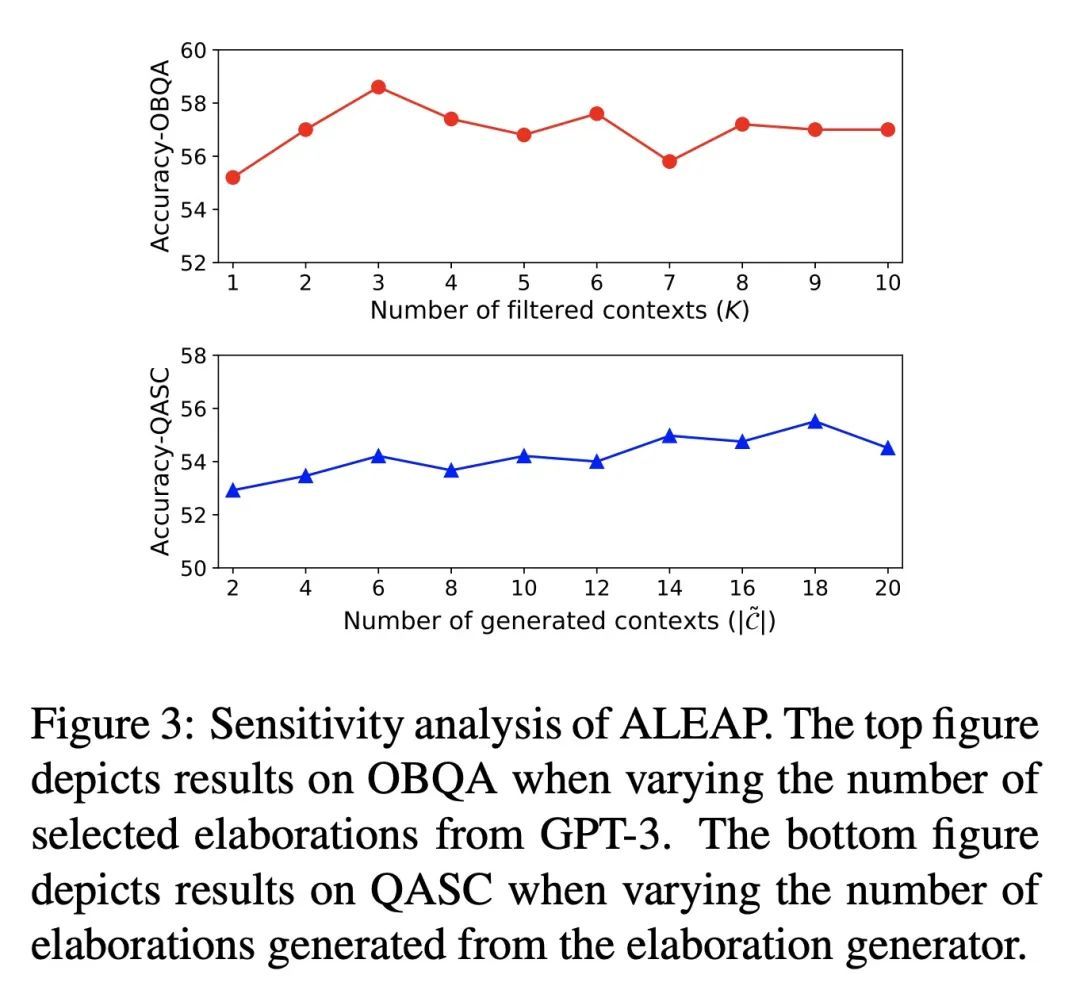
[CL] Elaboration-Generating Commonsense Question Answering at Scale
常识性问答的大规模精细化生成
W Wang, V Srikumar, H Hajishirzi, N A. Smith
[University of Washington & Allen Institute for AI]
https://arxiv.org/abs/2209.01232


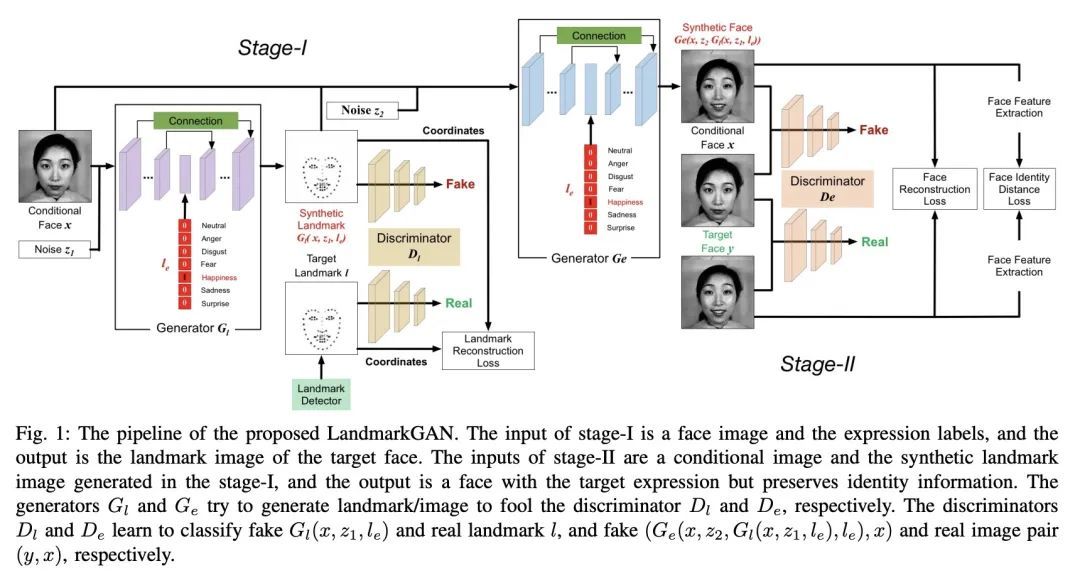
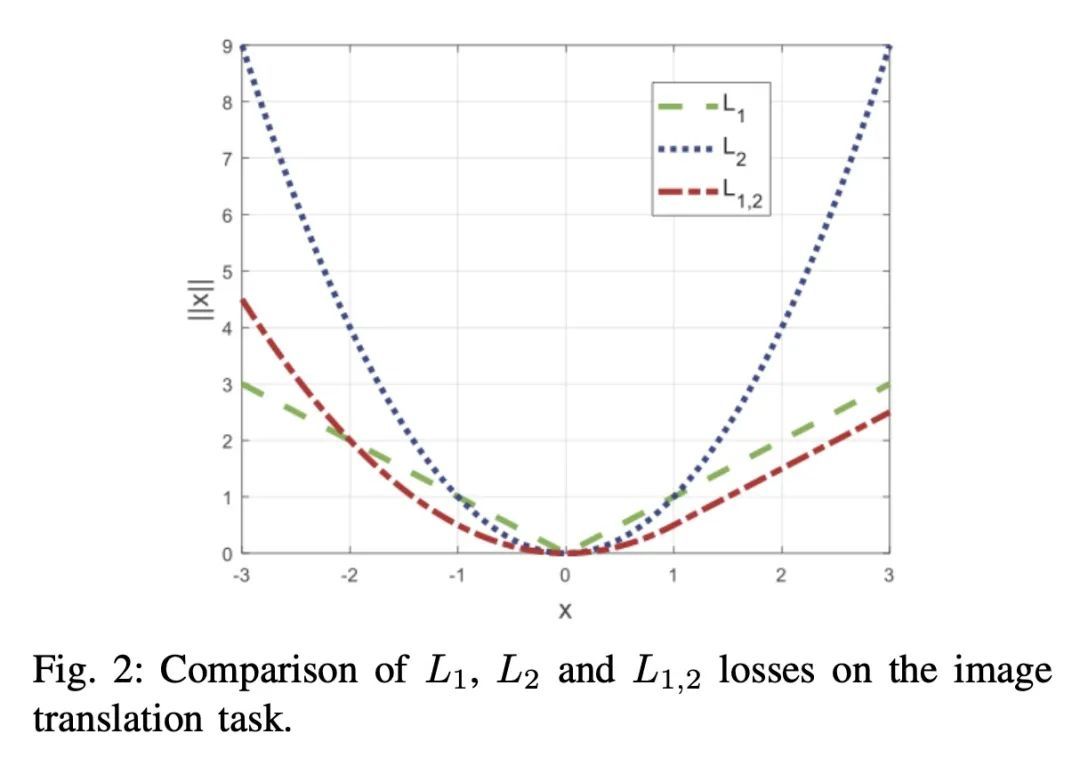
[CV] Facial Expression Translation using Landmark Guided GANs
基于特征点引导GAN的人脸表情翻译
H Tang, N Sebe
[ETH Zurich & University of Trento]
https://arxiv.org/abs/2209.02136

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢