

论文地址:https://arxiv.org/pdf/2112.00719.pdf
项目网站:https://di-mi-ta.github.io/HyperInverter
开源代码:https://github.com/VinAIResearch/HyperInverter
摘要
近年来,对生成对抗网络(GAN)潜在空间的探索和利用,使得图像处理领域取得了惊人的进展。 要将GAN潜在空间探索的语义方向应用于真实世界的图像,常用的做法是“先反转,后编辑”。GAN逆映射是该途径的第一步,旨在将图像真实地映射到GAN模型的潜码。不幸的是,大多数现有的GAN逆映射方法至少不能满足下面三个要求之一:高重建质量、可编辑性和快速推理。本文提出了一种新颖的两阶段策略,可以同时满足所有要求。在第一阶段,我们训练一个编码器将输入图像映射到StyleGAN2 W WW空间,W WW空间具有出色的可编辑性,但重建质量较低。在第二阶段,我们通过利用一组超网络在逆映射过程中恢复丢失的信息来补充初始阶段的重建能力。超网络分支以及在具有出色可编辑性的W WW空间中进行的逆映射,这两个步骤相互补充以产生高质量重建。我们的方法完全基于编码器,因此推理速度极快。在两个具有挑战性的数据集上进行的大量实验证明了我们方法的优越性。
现有方法
在给定输入图像的情况下,确定GAN模型的潜码有两种通用方法:
- 通过编码器推断:例如 pSp、e4e、Restyle等;
- 通过迭代优化:例如PTI、SG2 W+ 等。
基于优化的方法通常能够比基于编码器的方法更准确地执行重建,但它需要对每个新图像进行优化或微调,所以会消耗更多的计算时间,这对于可编辑性就有所限制。
方法
本文提出了一种完全基于编码器的方法,通过使用两阶段策略和超网络来优化生成器的权重以解决StyleGAN逆映射问题。第一阶段将输入图像x通过标准编码器映射到GAN的潜在空间,然后在第二阶段对生成器进行优化,使其适应重建的潜码,以保留原始图像细节,同时允许可编辑性。该方法在几乎实时运行的同时具有高保真重建和出色的可编辑性。
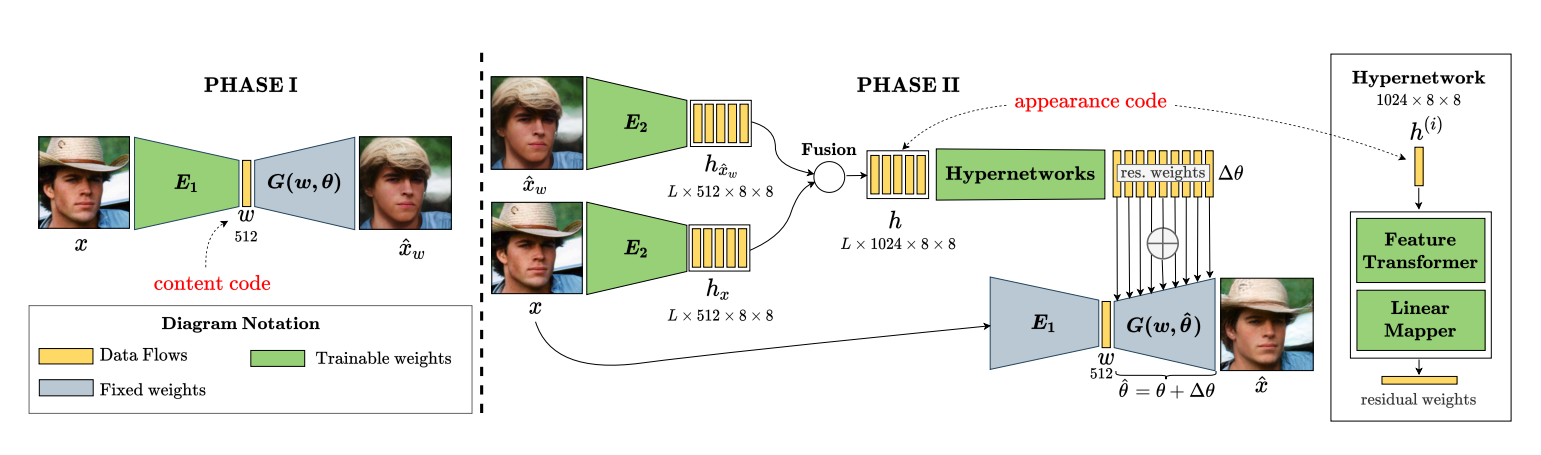
阶段Ⅰ:从图像到内容代码
在StyleGAN中,用于逆映射的W空间比W+ 空间的编辑能力更出色。 因此,作者选择W空间来定位我们的潜码。
给定输入图像x,训练编码器E1将x回归到相应的潜码w(w的大小为 R512),w具有编码图像中主要语义的内容代码的作用。 通过将潜码w传递给生成器来重建图像^x w。对于之后的图像编辑任务,我们可以在可解释的语义方向上遍历这个潜码来操作图像。
在这一阶段,本文使用一组损失函数来确保真实的重建。重建损失\( L_{rec} \)定义为:
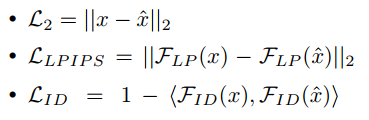
- \( L_2 \)测量输入图像和重建图像之间的像素级相似性;
- \( L_{LPIPS} \)是感知损失,其中\( F_{LP} \)表示感知特征提取器;
- \( L_{ID} \),这里的\( F_{ID} \)是特定于类的特征提取器网络,〈 , 〉表示两个特征嵌入向量之间的余弦相似度。
由于潜码w的维数相对较低,重建的图像在感知上与输入图像不同,这使得编辑结果缺乏说服力。为了解决这个问题,作者提出了第二阶段,通过用新的权重细化生成器来进一步提高重建质量。
阶段Ⅱ:融合外观代码通过超网络改进生成器
这个阶段的目标是恢复输入图像x的缺失信息,从而减少输入图像和重建图像之间的差异。本文创建了一个单向前向传递网络,通过检查当前输入x和重建^x w来学习改进生成器G。使用单向前向传递网络可以保证非常快的运行时间。
首先将输入图像x和重建图像^xw 编码为中间特征,并将它们融合成一个公共特征张量h,输入到一组超网络中,得到一组残差权重。然后,使用残差权重更新生成器G中的相应卷积层,来产生一组新的权重Δ θ(这里作者只考虑预测G GG的主要卷积层、跳过偏差和其他层的权重)。更新后的生成器的卷积权重^θ = θ + Δθ。 最终的重建图像由阶段Ⅰ的内容代码w通过更新的生成器G(w, ^ θ)生成。经过优化的生成器的重建^ x比当前重建图像^xw 更接近输入图像x。
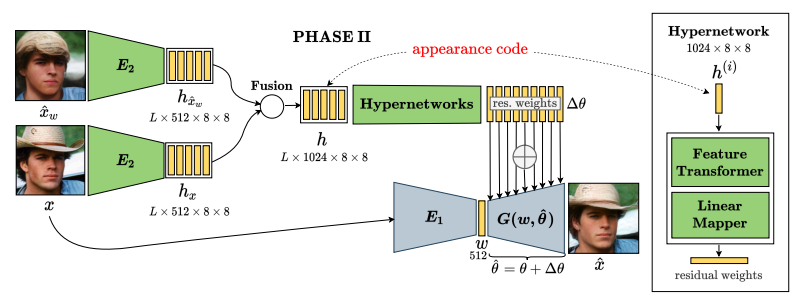 下图是超网络的设计细节。具体来说,每个超网络包含两个主要模块,特征Transformer和线性映射器。 特征Transformer是一个小型卷积神经网络,用于将外观代码转换为隐藏特征。线性映射器用于从隐藏特征到卷积权重的最终映射。本文使用两个小矩阵而不是单个大矩阵来进行权重映射,以保持超网络中的参数数量可管理。
下图是超网络的设计细节。具体来说,每个超网络包含两个主要模块,特征Transformer和线性映射器。 特征Transformer是一个小型卷积神经网络,用于将外观代码转换为隐藏特征。线性映射器用于从隐藏特征到卷积权重的最终映射。本文使用两个小矩阵而不是单个大矩阵来进行权重映射,以保持超网络中的参数数量可管理。
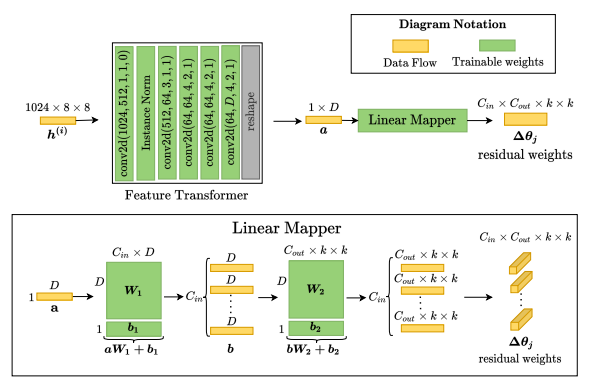
图表符号:conv2d(输入通道,输出通道,内核大小,步幅,填充)。为简单起见,图中省略了每个 conv2d 层之后的ReLU激活层。
在这一阶段,除了阶段Ⅰ的重建损失之外,作者还使用了非饱和GAN损失。由于我们在这个阶段修改了生成器的权重,所以这种损失有助于确保生成图像的真实性。
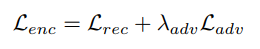
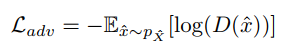
实验
重建结果
作者将本文方法与当前最先进的StyleGAN逆映射方法的重建结果进行了定量和定性比较。
定量比较
作者使用了一组不同的指标来衡量重建质量。包括像素级L2损失、LPIPS、PSNR 和MS-SSIM,还使用了FID 和KID指标来评估重建图像的真实性。
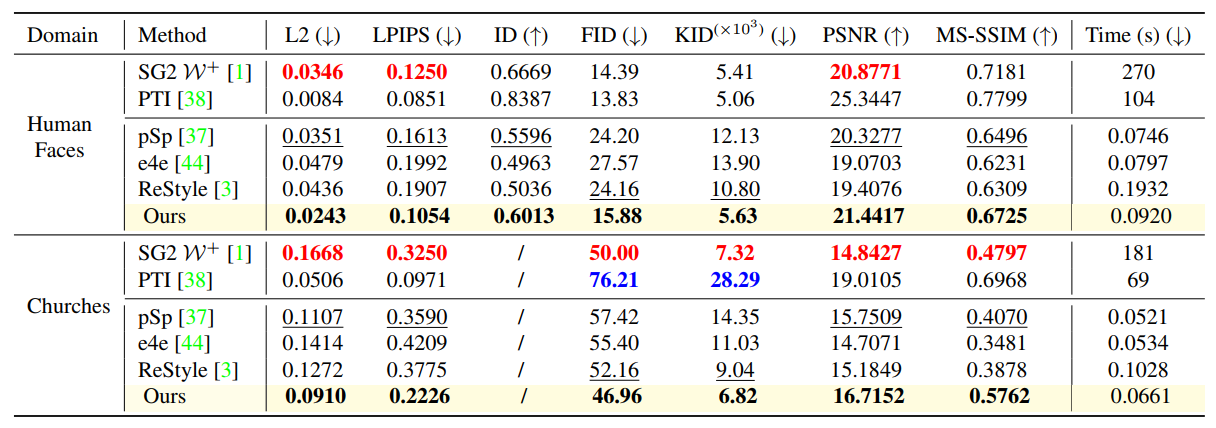
这里箭头向下就表示数值越小越好,箭头向上就表示数值越大越好。最优和次优分别用加粗和下划线标记。
定性比较
然后是重建结果的定性比较。

- 对于人脸,本文的方法能够很好的保留细节,例如帽子、手部;
- 在教堂数据集上,本文的方法在失真和感知方面也明显优于其他方法。由于PTI 受到失真感知权衡的影响,因此来自PTI 的图片并不完全真实。
编辑结果
定量比较
为了定量评估编辑能力,本文在每种逆映射方法上应用相同的编辑幅度γ γγ,作者选择的两个编辑方向分别是年龄和姿势。然后测量年龄编辑的年龄变化量 和姿势编辑的偏航角度变化量(以度为单位)。这里作者使用DEX VGG模型进行年龄回归,使用预训练的FacePoseNet进行头部姿势估计。
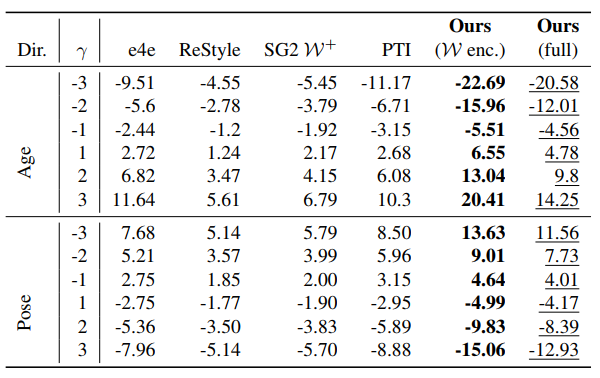
最优和次优分别用加粗和下划线标记。
- 阶段Ⅰ的编码器完成的逆映射取得了最显着的效果,因为它适用于高度可编辑的W WW空间潜码;
- 阶段Ⅱ改进后,仍然保留了编辑能力,虽然不如阶段Ⅰ的结果好,但也优于其他所有的方法。
定性比较

- 由于本文方法的重建效果比其他基于编码器的方法更稳健,因此可以提供更好的编辑结果。本文的方法能够执行合理的编辑,同时保留非编辑的属性,例如背景。
- 与SG2 W+ 相比,本文的方法编辑效果显着,并且具有更少的伪影,例如胡须。原因是本文的方法使用了具有出色编辑能力的W空间,而SG2 W+ 使用了扩展W+ 空间,可编辑性较低。
- PTI 在人脸域上可以很好地进行编辑操作,但在教堂数据集上,PTI 受到失真感知权衡的影响,重建的图像并不真实,导致这些图像的后期编辑效果不佳。
用户调查
作者还做了一项用户调查,将本文的方法与另外两种基于编码器的逆映射方法进行了比较。参加测试的人员根据重建和编辑质量这两个标准将这三个方法进行排名,然后以百分比的形式展现出来。
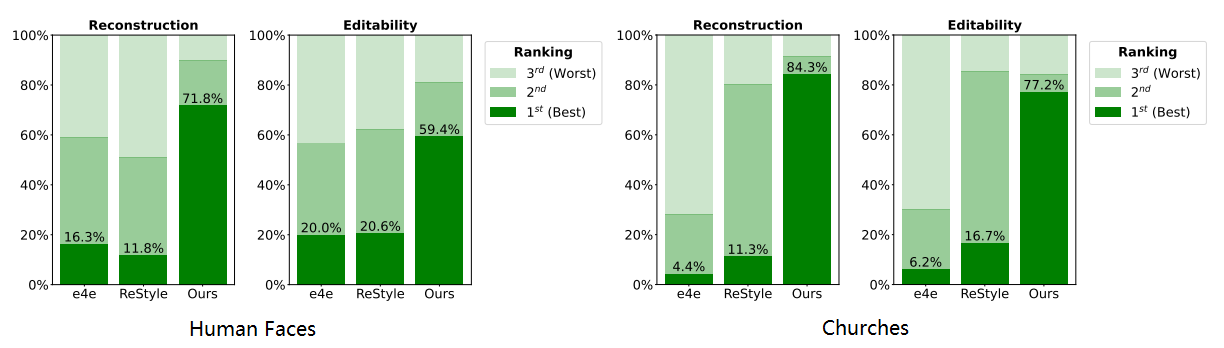
从图中可以看出,无论是重建质量,还是编辑质量,本文的方法都优于另外两种方法,并且有较大的差距。
消融实验
阶段Ⅱ的必要性
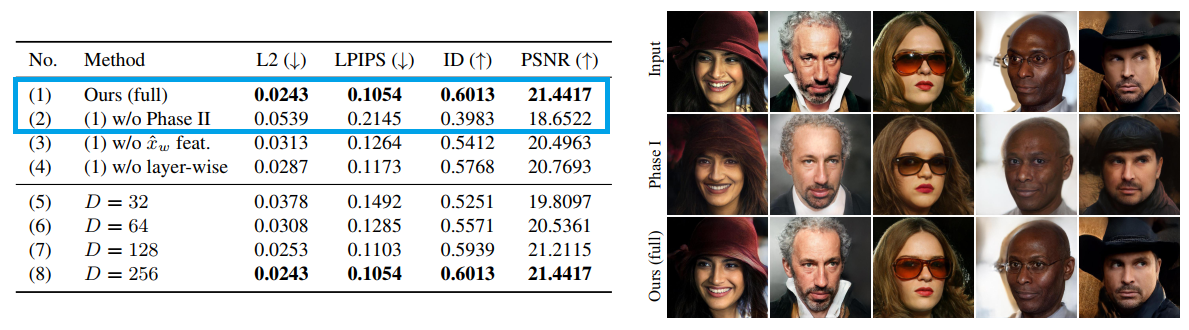
从左侧表中可以看出,如果没有阶段Ⅱ,重建的质量会下降,这里展示的量化指标能够说明这一点。 在右侧可视化图中,我们可以看到重建的图像丢失了各种细节,例如帽子、领口、眼镜。 相比之下,通过阶段Ⅱ的改进,能够更真实地恢复输入图像。
融合外观代码的有效性
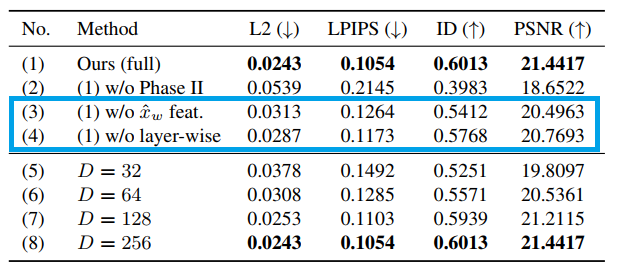
(3) 是不同时使用输入图像和初始重建图像的特征,而仅使用输入图像特征的结果。(4) 是不使用分层设计的外观代码(h hh∈R RR L×1024×8×8),而是使用共享代码(h hh∈R RR 1024×8×8)的结果。从表中可以看出,本文的完整版本结果都优于这些简化版。
超网络中超参数D的不同选择
超网络设计中的隐藏维度D DD对模型性能有明显影响。
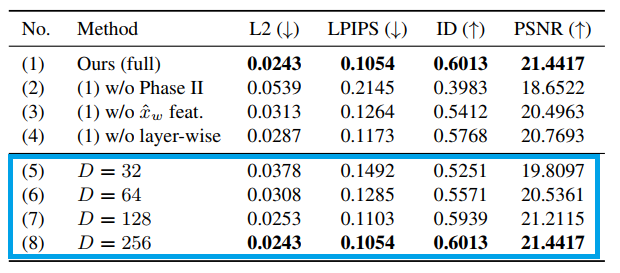
表中的第 (5)—(8) 行研究了D DD的不同选择,从结果可以看出D DD = 256 是最佳选择。
生成器中哪些层被更新
本文将超网络预测的残差权重可视化,来分析在应用阶段Ⅱ时生成器中的哪些层变化最大。作者选择可视化每层参数之间的平均绝对权重变化量,并将该值与其他层进行比较。
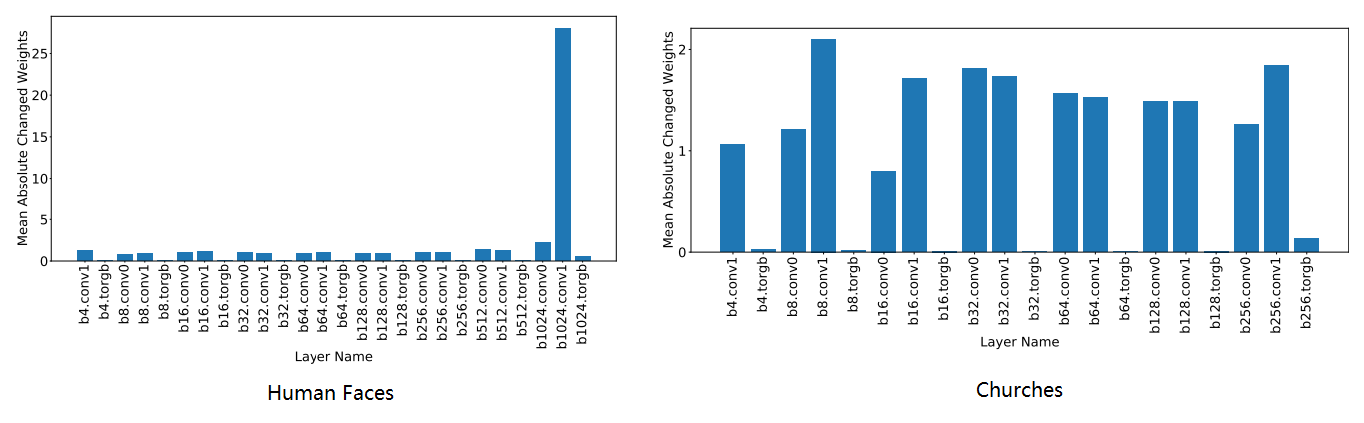
toRGB将一个层中的特征向量投射到RGB颜色空间中,采用1×1卷积。
- 主生成器块中的卷积层比 toRGB块中的卷积层贡献更大;
- 最后一个分辨率(1024×1024)的权重变化明显大于其他分辨率的权重变化。在人脸域上(左侧图),由于阶段Ⅰ总体上对图像进行了很好的重建,因此在阶段Ⅱ,它们主要关注细粒度细节的细化。
应用:真实世界的图像插值
本文提出了一种在两个真实图像之间进行插值的新方法。给定两个输入图像,一个常用的过程是首先通过GAN逆映射找到对应的潜码,计算线性插值潜码,并通过GAN模型得到插值图像。 受两阶段逆映射机制的启发,我们提出了一种新的插值方法,通过插值潜码和生成器权重,而不是仅插值潜码。
将本文的方法与仅插值潜码的方法进行比较, 图中显示了一些定性结果,本文的方法不仅重建了具有正确细粒度细节(例如帽子、背景和手)的输入图像,而且还提供了平滑的插值图像。

总结
- 本文提出了一个完全基于编码器的两阶段GAN逆映射方法,可以重建真实的图像,同时保持可编辑性和快速推理的能力。
- 设计了一种新的网络结构,由一系列超网络组成,用于更新预先训练好的StyleGAN生成器的权重,从而提高重建质量。
- 通过广泛的GAN网络逆映射的基准,证明了所提出方法与现有方法相比的优越性能。
- 提出一种用于真实世界图像插值的新方法,它同时对潜码和生成器权重进行插值。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢