
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:基于可微算法的学习、预训练Transformer的知识神经元、参数化CAD草图生成式模型、语义分割泛化学习、基于参数化似然比的分布鲁棒模型
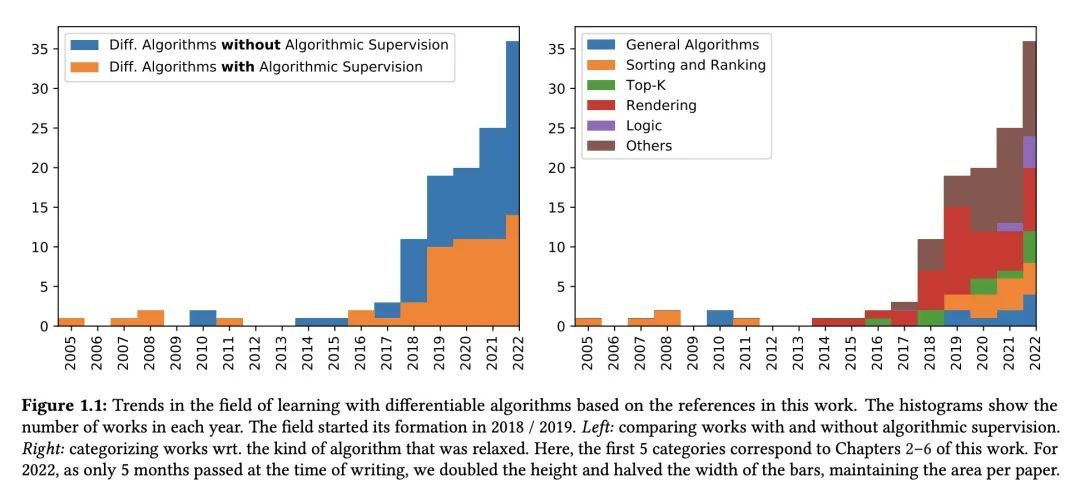
1、[LG] Learning with Differentiable Algorithms
F Petersen
[University of Konstanz]
基于可微算法的学习。经典算法和机器学习系统,如神经网络,在日常生活中应用都很丰富。经典的计算机科学算法适用于精确执行精确定义的任务,如在大的图中寻找最短路径,而神经网络允许从数据中学习,以预测更复杂的任务中最可能的答案,如图像分类,这无法简化为精确的算法。为了获得两方面的优势,本论文探讨了将这两个概念结合起来,从而形成更鲁棒、性能更好、更易解释、更加计算高效和更加数据高效的架构。本文正式提出了算法监督的概念,允许神经网络从算法中学习或与算法结合起来。当把一个算法整合到一个神经结构中时,重要的是该算法是可微的,这样该结构就可以进行端到端的训练,并且梯度可以以一种有意义的方式通过算法传播回来。为了使算法具有可微分性,本文提出一种基于扰动变量和以闭合形式近似期望值(无需采样)的连续松弛算法的一般方法。此外,本文还提出了可微算法,如可微排序网络、可微渲染器和可微逻辑门网络。最后,本文提出了用算法学习的替代训练策略。
Classic algorithms and machine learning systems like neural networks are both abundant in everyday life. While classic computer science algorithms are suitable for precise execution of exactly defined tasks such as finding the shortest path in a large graph, neural networks allow learning from data to predict the most likely answer in more complex tasks such as image classification, which cannot be reduced to an exact algorithm. To get the best of both worlds, this thesis explores combining both concepts leading to more robust, better performing, more interpretable, more computationally efficient, and more data efficient architectures. The thesis formalizes the idea of algorithmic supervision, which allows a neural network to learn from or in conjunction with an algorithm. When integrating an algorithm into a neural architecture, it is important that the algorithm is differentiable such that the architecture can be trained end-to-end and gradients can be propagated back through the algorithm in a meaningful way. To make algorithms differentiable, this thesis proposes a general method for continuously relaxing algorithms by perturbing variables and approximating the expectation value in closed form, i.e., without sampling. In addition, this thesis proposes differentiable algorithms, such as differentiable sorting networks, differentiable renderers, and differentiable logic gate networks. Finally, this thesis presents alternative training strategies for learning with algorithms.
https://arxiv.org/abs/2209.00616


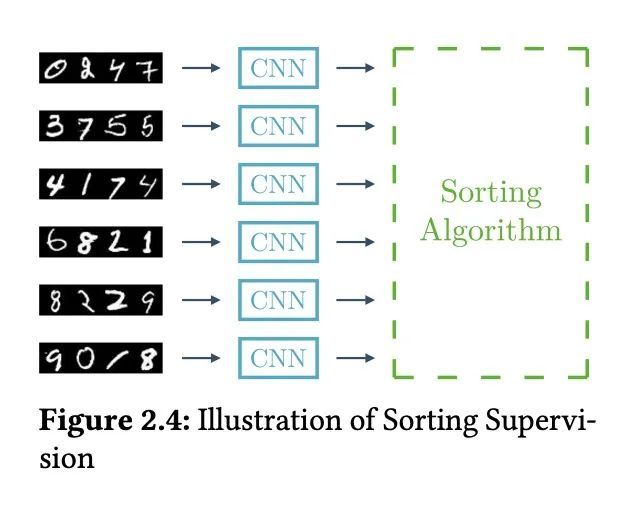
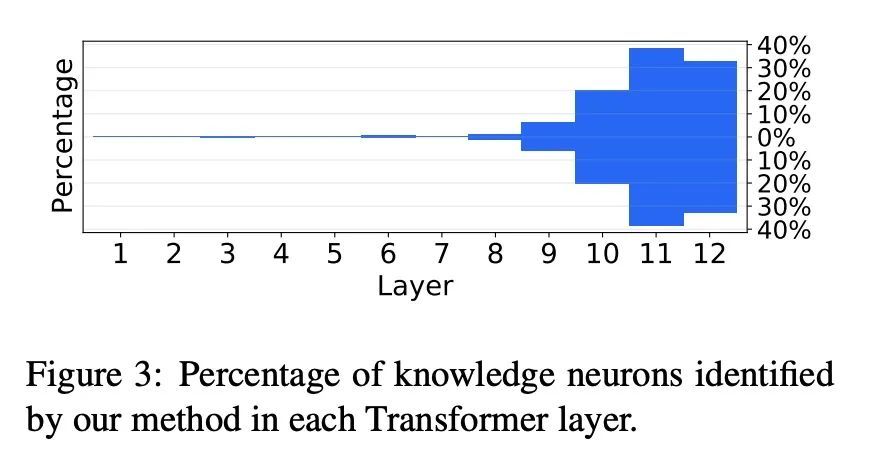
2、[CL] Knowledge Neurons in Pretrained Transformers
D Dai, L Dong, Y Hao, Z Sui, B Chang, F Wei
[Peking University & Microsoft Research]
预训练Transformer的知识神经元。大规模预训练语言模型在回忆训练语料库中呈现的事实性知识方面有令人惊讶的表现。本文通过引入知识神经元的概念,对事实性知识如何存储在预训练Transformer中进行了初步研究。本文研究了BERT的填空任务。给定一个关系事实,提出了一种知识归属的方法来识别表达该事实的神经元。这种知识神经元的激活与它们相应事实的表达是正相关的。在所述案例研究中,本文试图利用知识神经元来编辑(如更新和删除)特定的事实知识,而不需要进行微调。实验结果阐明了对预训练Transformer内知识存储的理解。
Large-scale pretrained language models are surprisingly good at recalling factual knowledge presented in the training corpus (Petroni et al., 2019; Jiang et al., 2020b). In this paper, we present preliminary studies on how factual knowledge is stored in pretrained Transformers by introducing the concept of knowledge neurons. Specifically, we examine the fill-in-the-blank cloze task for BERT. Given a relational fact, we propose a knowledge attribution method to identify the neurons that express the fact. We find that the activation of such knowledge neurons is positively correlated to the expression of their corresponding facts. In our case studies, we attempt to leverage knowledge neurons to edit (such as update, and erase) specific factual knowledge without fine-tuning. Our results shed light on understanding the storage of knowledge within pretrained Transformers. The code is available at https://github.com/ Hunter-DDM/knowledge-neurons.
https://arxiv.org/abs/2104.08696



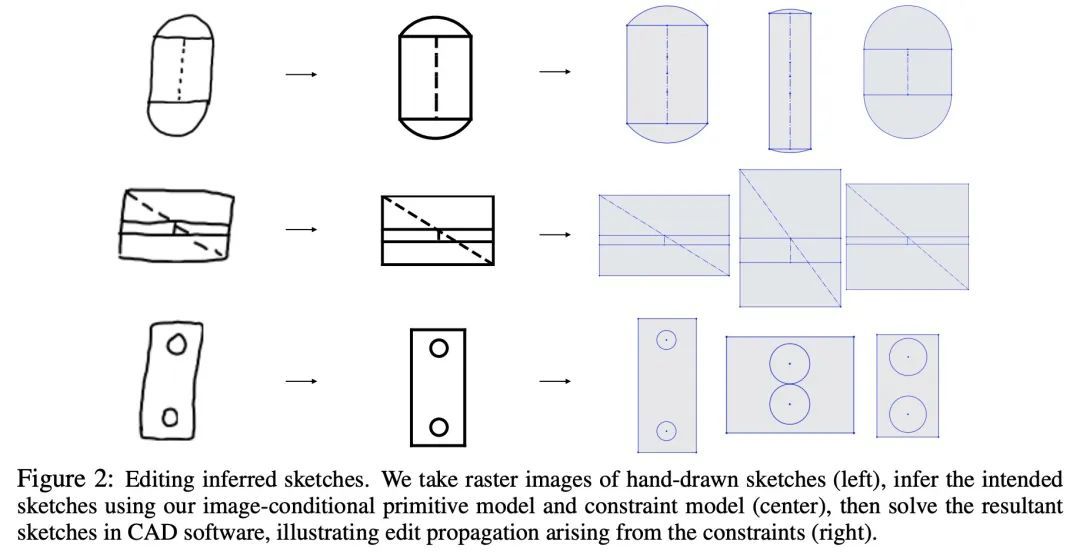
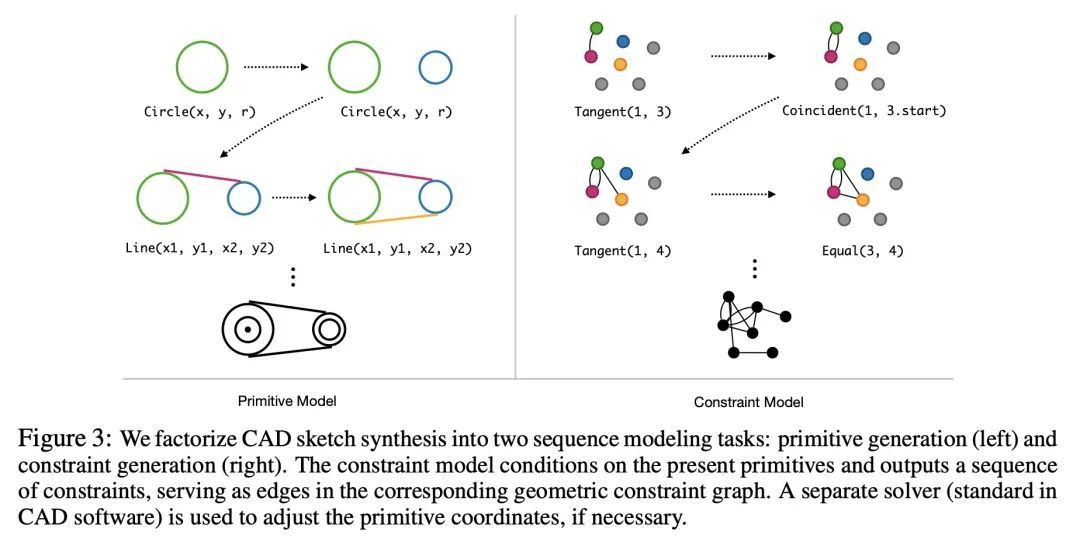
3、[LG] Vitruvion: A Generative Model of Parametric CAD Sketches
A Seff, W Zhou, N Richardson, R P. Adams
[Princeton University & New York University]
Vitruvion:参数化CAD草图生成式模型。参数化计算机辅助设计(CAD)工具是工程师指定物理结构的主要方式,从自行车踏板到飞机到印刷电路板。参数化CAD的关键特征是,设计意图不仅通过几何基元进行编码,而且还通过元素之间的参数化约束进行编码。这种关系规范可以看作是一个约束程序的构建,允许编辑连贯地传播到设计的其他部分。机器学习提供了一种令人感兴趣的可能性,即通过对这些结构进行生成式建模来加速设计过程,从而实现新的工具,如自动补全、约束推理和条件合成。本文提出一种对参数化CAD草图进行生成式建模的方法,这些草图构成了现代机械设计的基本计算构件。所提出模型在来自SketchGraphs数据集的真实世界设计上进行了训练,自动递归地将草图合成为具有初始坐标的基元序列,并参考了采样基元的约束。由于模型中的样本与标准CAD软件中使用的约束图表示相匹配,可以被直接导入、解决,并根据下游设计任务进行编辑。将模型置于各种环境中,包括部分草图(底图)和手绘草图的图像。对所提出的方法的评估表明,它有能力合成真实的CAD草图,并有助于机械设计工作流程。
Parametric computer-aided design (CAD) tools are the predominant way that engineers specify physical structures, from bicycle pedals to airplanes to printed circuit boards. The key characteristic of parametric CAD is that design intent is encoded not only via geometric primitives, but also by parameterized constraints between the elements. This relational specification can be viewed as the construction of a constraint program, allowing edits to coherently propagate to other parts of the design. Machine learning offers the intriguing possibility of accelerating the design process via generative modeling of these structures, enabling new tools such as autocompletion, constraint inference, and conditional synthesis. In this work, we present such an approach to generative modeling of parametric CAD sketches, which constitute the basic computational building blocks of modern mechanical design. Our model, trained on real-world designs from the SketchGraphs dataset, autoregressively synthesizes sketches as sequences of primitives, with initial coordinates, and constraints that reference back to the sampled primitives. As samples from the model match the constraint graph representation used in standard CAD software, they may be directly imported, solved, and edited according to downstream design tasks. In addition, we condition the model on various contexts, including partial sketches (primers) and images of hand-drawn sketches. Evaluation of the proposed approach demonstrates its ability to synthesize realistic CAD sketches and its potential to aid the mechanical design workflow.
https://arxiv.org/abs/2109.14124


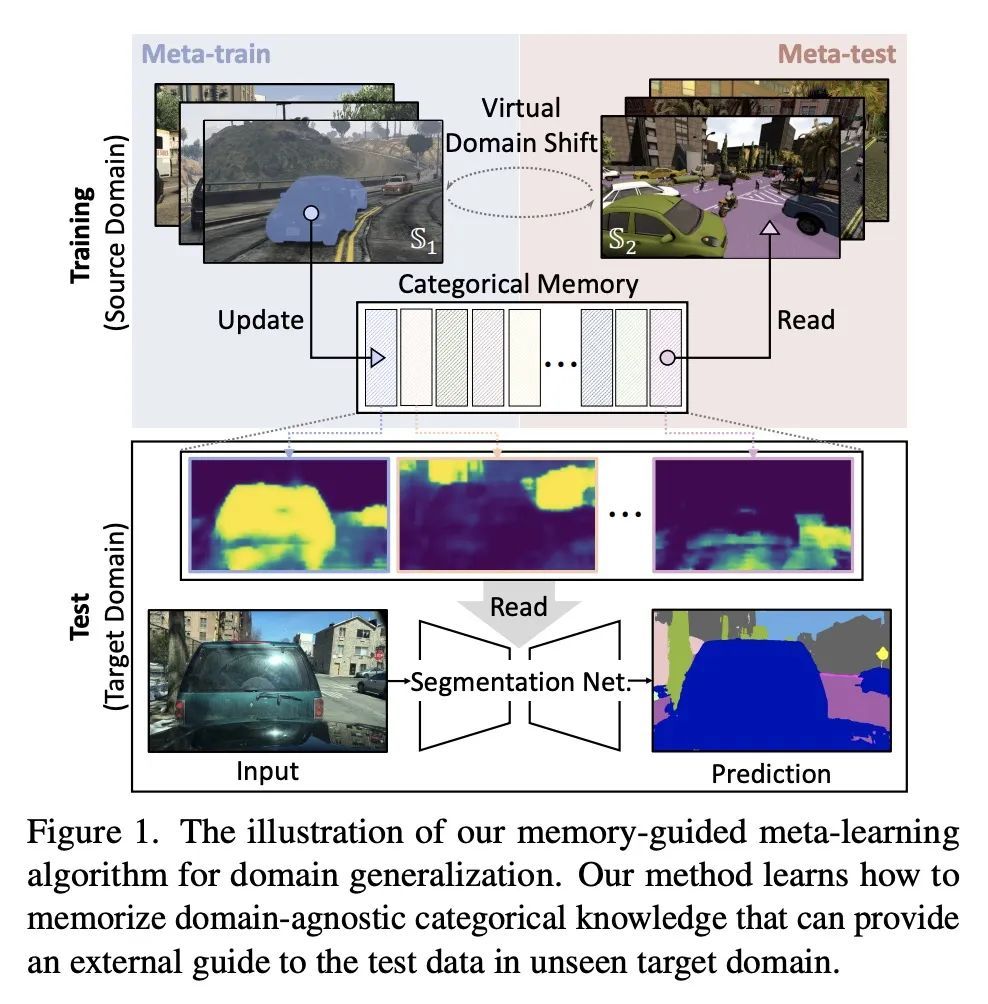
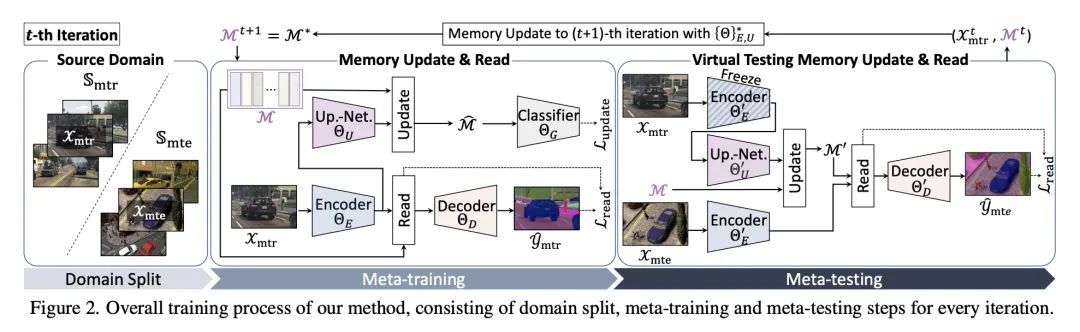
4、[CV] Pin the Memory: Learning to Generalize Semantic Segmentation
J Kim, J Lee, J Park, D Min, K Sohn
[Yonsei University & NAVER AI Lab & Ewha Womans University]
钉住记忆:语义分割泛化学习。深度神经网络的兴起为语义分割带来了一些突破性进展。尽管如此,在源域上训练的模型往往不能在新的挑战域中正常工作,这直接关系到模型的泛化能力。本文提出一种基于元学习框架的语义分割的新的记忆引导域泛化方法,将语义类的概念性知识抽象为分类记忆,而分类记忆是超越域的常量。根据元学习的概念,反复训练记忆引导的网络并模拟虚拟测试,以 1)学习如何记忆与域无关的独特的类信息;2)提供一个外部解决的记忆作为类指导,以减少任意未见域的测试数据中的模糊表示。为此,本文还提出了记忆发散和特征内聚损失,鼓励学习记忆阅读和更新过程,以实现类别感知的域泛化。广泛的语义分割实验证明了所提出方法在各种基准上比最先进的方法具有更强的泛化能力。
The rise of deep neural networks has led to several breakthroughs for semantic segmentation. In spite of this, a model trained on source domain often fails to work properly in new challenging domains, that is directly concerned with the generalization capability of the model. In this paper, we present a novel memory-guided domain generalization method for semantic segmentation based on meta-learning framework. Especially, our method abstracts the conceptual knowledge of semantic classes into categorical memory which is constant beyond the domains. Upon the meta-learning concept, we repeatedly train memory-guided networks and simulate virtual test to 1) learn how to memorize a domain-agnostic and distinct information of classes and 2) offer an externally settled memory as a class-guidance to reduce the ambiguity of representation in the test data of arbitrary unseen domain. To this end, we also propose memory divergence and feature cohesion losses, which encourage to learn memory reading and update processes for category-aware domain generalization. Extensive experiments for semantic segmentation demonstrate the superior generalization capability of our method over state-of-the-art works on various benchmarks.
https://arxiv.org/abs/2204.03609


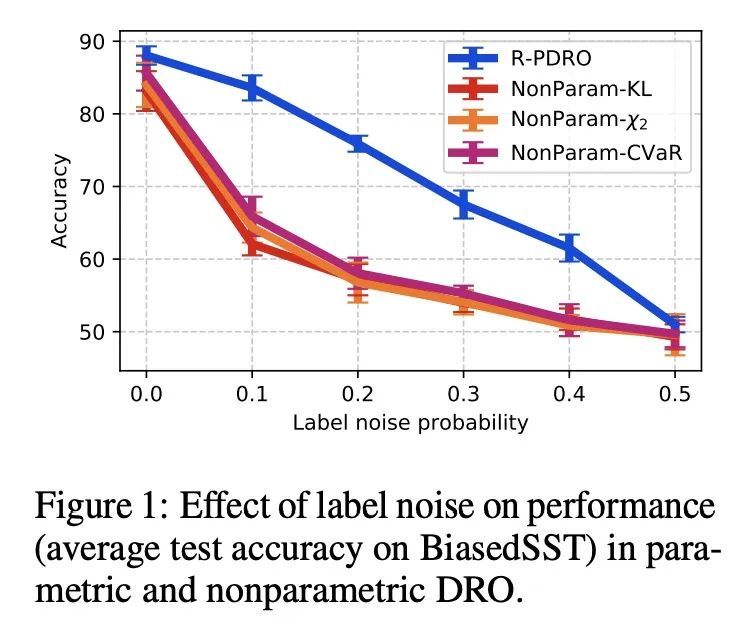
5、[LG] Distributionally Robust Models with Parametric Likelihood Ratios
P Michel, T Hashimoto, G Neubig
[École normale supérieure PSL & Stanford University & CMU]
基于参数化似然比的分布鲁棒模型。随着机器学习模型的部署越来越广泛,它们不仅能够在其训练分布上表现良好,而且在面对分布变化时也能产生准确的预测,这一点变得越来越重要。分布鲁棒优化(DRO)框架建议通过训练模型来解决该问题,使其在一系列分布下的预期风险最小化,以模仿测试时的漂移。这通常是通过对训练目标的实例级重加权来实现的,以模仿可能的测试分布的似然比,这允许通过重要性抽样来估计它们的经验风险(假设它们是训练分布的子群)。然而,由于难以保持优化问题的可操作性和执行归一化约束的复杂性,文献中的重加权方案通常是有限的。本文展示了三个简单的想法——迷你批次级归一化、KL惩罚和同步梯度更新——使得能够使用更广泛的参数似然比用DRO训练模型。通过一系列关于图像和文本分类基准的实验发现,与其他DRO方法相比,用所得到的参数化方法训练的模型对子群的漂移始终更加鲁棒,而且该方法在几乎没有超参数调整的情况下表现得很可靠。
As machine learning models are deployed ever more broadly, it becomes increasingly important that they are not only able to perform well on their training distribution, but also yield accurate predictions when confronted with distribution shift. The Distributionally Robust Optimization (DRO) framework proposes to address this issue by training models to minimize their expected risk under a collection of distributions, to imitate test-time shifts. This is most commonly achieved by instance-level re-weighting of the training objective to emulate the likelihood ratio with possible test distributions, which allows for estimating their empirical risk via importance sampling (assuming that they are subpopulations of the training distribution). However, re-weighting schemes in the literature are usually limited due to the difficulty of keeping the optimization problem tractable and the complexity of enforcing normalization constraints. In this paper, we show that three simple ideas – mini-batch level normalization, a KL penalty and simultaneous gradient updates – allow us to train models with DRO using a broader class of parametric likelihood ratios. In a series of experiments on both image and text classification benchmarks, we find that models trained with the resulting parametric adversaries are consistently more robust to subpopulation shifts when compared to other DRO approaches, and that the method performs reliably well with little hyper-parameter tuning.
https://arxiv.org/abs/2204.06340


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢