
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:3D人体时间动作合成、实际场景中的图像到神经辐射场、基于Token-Critic的改进掩码图像生成、基于神经隐函数从单一图像中获得3D头部肖像、通用激活的快速神经核嵌入、面向开放词表任务的图像-语言Transformer预训练、聚类的贝叶斯模型平均、在线低秩矩阵补全、面向低资源语言语音识别的多语Transformer语言模型
1、[CV] TEACH: Temporal Action Composition for 3D Humans
N Athanasiou, M Petrovich, M J. Black, G Varol
[Univ Gustave Eiffel & Max Planck Institute for Intelligent Systems]
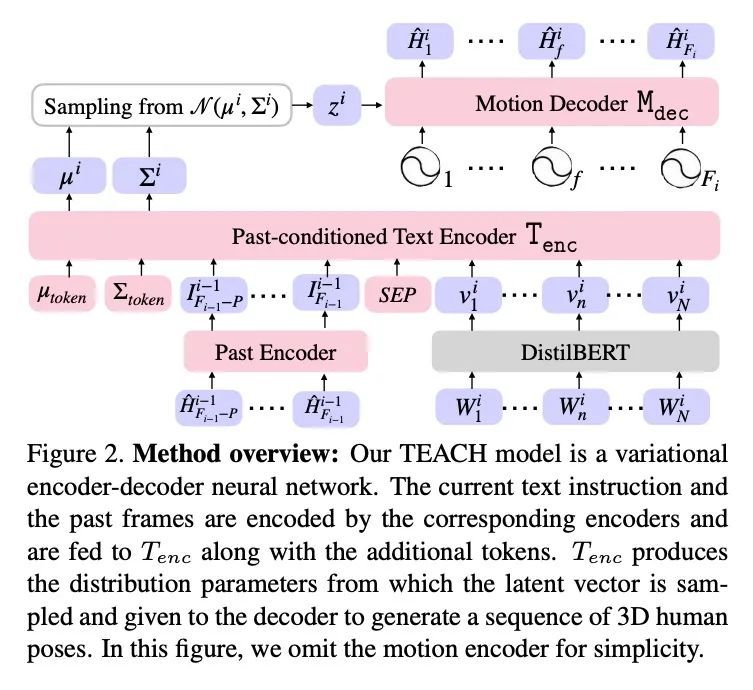
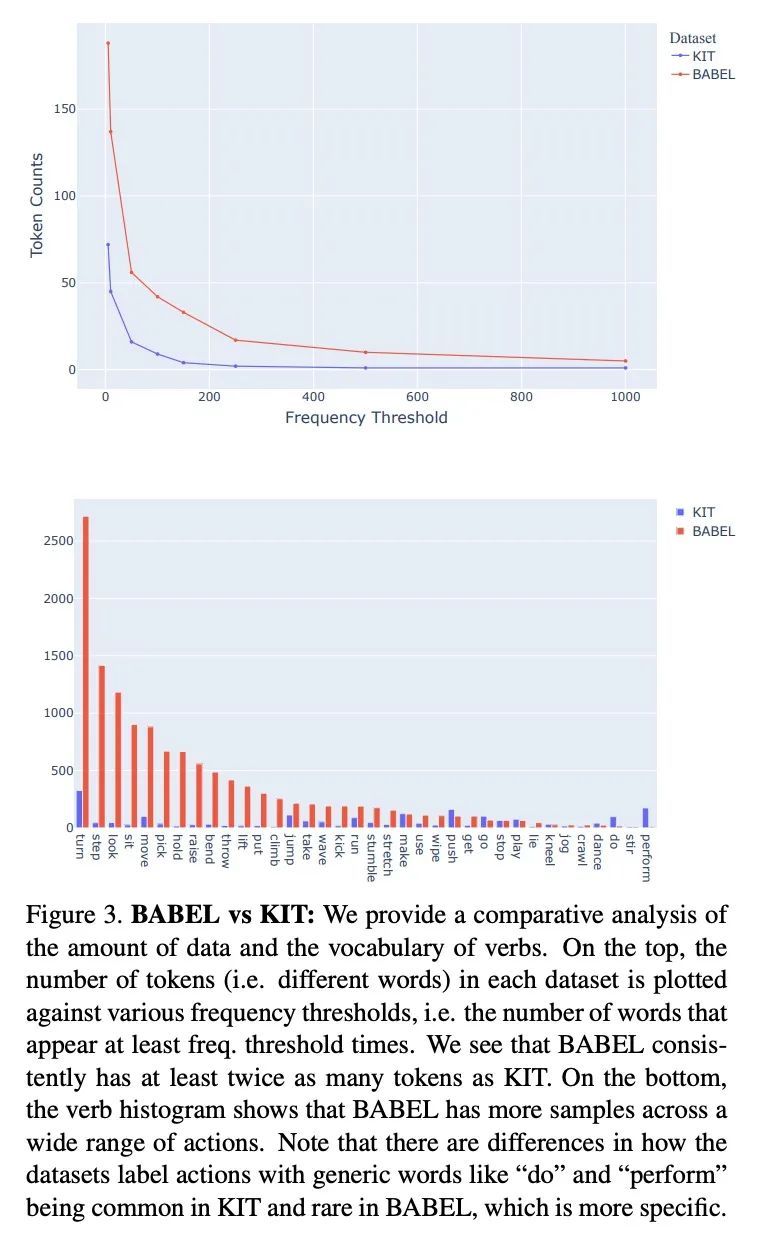
TEACH:3D人体时间动作合成。给定一系列自然语言描述,本文的任务是生成3D人体动作,这些动作在语义上与文本对应,并遵循指令的时间顺序,其目标是实现一系列动作的合成,称为时间动作合成。目前,以文本为条件的动作合成技术只将单个动作或单个句子作为输入。这部分是由于缺乏合适的包含动作序列的训练数据,但也是由于其非自回归模型表述的计算复杂性,不能很好地扩展到长序列。本文解决了这两个问题。首先利用最近的BABEL动作文本集,其有广泛的标记动作,其中许多是在一个序列中出现的,并在它们之间有过渡。本文设计了一种基于Transformer的方法,在一个动作内非自动渐进操作,但在动作序列内是自动渐进的。与多个基线对比的实验表明,这种分层的表述是有效的。
Given a series of natural language descriptions, our task is to generate 3D human motions that correspond semantically to the text, and follow the temporal order of the instructions. In particular, our goal is to enable the synthesis of a series of actions, which we refer to as temporal action composition. The current state of the art in textconditioned motion synthesis only takes a single action or a single sentence as input. This is partially due to lack of suitable training data containing action sequences, but also due to the computational complexity of their non-autoregressive model formulation, which does not scale well to long sequences. In this work, we address both issues. First, we exploit the recent BABEL motion-text collection, which has a wide range of labeled actions, many of which occur in a sequence with transitions between them. Next, we design a Transformer-based approach that operates non-autoregressively within an action, but autoregressively within the sequence of actions. This hierarchical formulation proves effective in our experiments when compared with multiple baselines. Our approach, called TEACH for “TEmporal Action Compositions for Human motions”, produces realistic human motions for a wide variety of actions and temporal compositions from language descriptions. To encourage work on this new task, we make our code available for research purposes at teach.is.tue.mpg.de.
https://arxiv.org/abs/2209.04066


2、[CV] im2nerf: Image to Neural Radiance Field in the Wild
L Mi, A Kundu, D Ross, F Dellaert, N Snavely, A Fathi
[Google Research]
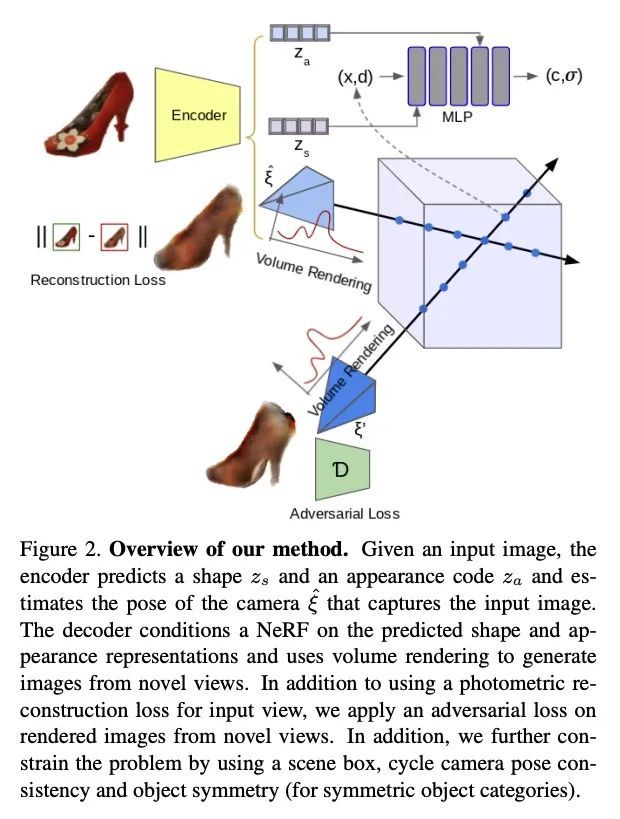
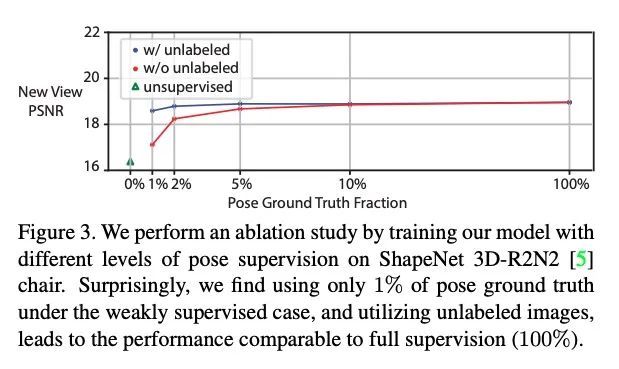
im2nerf:实际场景中的图像到神经辐射场。本文提出im2nerf,一个学习框架,可以在实际场景中给定一个单幅的输入图像,只在现成识别方法分割输出的监督下预测一个连续的神经目标表示。构建神经辐射场的标准方法利用多视图的一致性,需要许多经过校准的场景视图,在实际场景的大规模图像数据上学习时,这一要求无法满足。本文在解决这一缺陷方面迈出了一步,引入了一种模型,该模型将输入图像编码为一个解缠的物体表示,其中包含目标形状的代码、目标外观的代码和估计的相机姿态,目标图像就是由该相机捕捉的。所提模型在预测的目标表示上设置了一个新的RF,用体渲染来生成新视图图像。在大量输入图像上对模型进行端到端训练。由于该模型只提供了单视图图像,该问题的约束性很低。因此,除了在合成输入视图上使用重建损失外,还在新渲染的视图上采用辅助的对抗损失,并且利用目标的对称性和循环摄像机的姿态一致性。在ShapeNet数据集上进行了广泛的定量和定性实验,并在Open Images数据集上进行了定性实验。在所有情况下,im2nerf都能从实际场景的单视角无姿态图像中实现最先进的新视角合成性能。
We propose im2nerf, a learning framework that predicts a continuous neural object representation given a single input image in the wild, supervised by only segmentation output from off-the-shelf recognition methods. The standard approach to constructing neural radiance fields takes advantage of multi-view consistency and requires many calibrated views of a scene, a requirement that cannot be satisfied when learning on large-scale image data in the wild. We take a step towards addressing this shortcoming by introducing a model that encodes the input image into a disentangled object representation that contains a code for object shape, a code for object appearance, and an estimated camera pose from which the object image is captured. Our model conditions a NeRF on the predicted object representation and uses volume rendering to generate images from novel views. We train the model end-to-end on a large collection of input images. As the model is only provided with single-view images, the problem is highly underconstrained. Therefore, in addition to using a reconstruction loss on the synthesized input view, we use an auxiliary adversarial loss on the novel rendered views. Furthermore, we leverage object symmetry and cycle camera pose consistency. We conduct extensive quantitative and qualitative experiments on the ShapeNet dataset [5] as well as qualitative experiments on Open Images dataset. We show that in all cases, im2nerf achieves the state-of-the-art performance for novel view synthesis from a single-view unposed image in the wild.
https://arxiv.org/abs/2209.04061


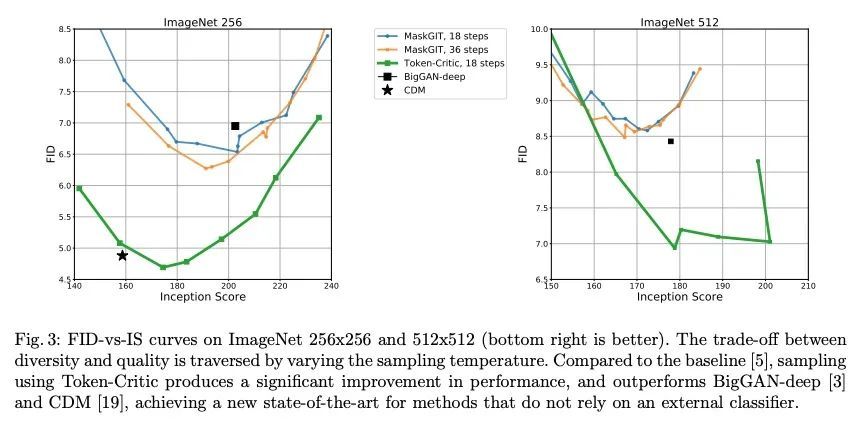
3、[CV] Improved Masked Image Generation with Token-Critic
J Lezama, H Chang, L Jiang, I Essa
[Google Research]
基于Token-Critic的改进掩码图像生成。非自回归生成Transformer最近展示了令人印象深刻的图像生成性能,并且比其自回归对应的采样速度快几个数量级。然而,从视觉标记的真实联合分布中进行最佳的平行采样仍然是一个公开的挑战。本文提出Token-Critic,一种指导非自回归生成式Transformer采样的辅助模型。给定一个经过掩码和重构的真实图像,TokenCritic模型被训练来区分哪些视觉Token属于原始图像,哪些是由生成Transformer采样得来的。在非自回归迭代采样过程中,Token-Critic被用来选择哪些Token要接受,哪些Token要拒绝并重新采样。与Token-Critic相结合,最先进的生成Transformer可大大改善其性能,在生成图像质量和多样性之间的权衡方面,在具有挑战性的类条件ImageNet生成方面优于最近的扩散模型和GAN。
Non-autoregressive generative transformers recently demonstrated impressive image generation performance, and orders of magnitude faster sampling than their autoregressive counterparts. However, optimal parallel sampling from the true joint distribution of visual tokens remains an open challenge. In this paper we introduce Token-Critic, an auxiliary model to guide the sampling of a non-autoregressive generative transformer. Given a masked-and-reconstructed real image, the TokenCritic model is trained to distinguish which visual tokens belong to the original image and which were sampled by the generative transformer. During non-autoregressive iterative sampling, Token-Critic is used to select which tokens to accept and which to reject and resample. Coupled with Token-Critic, a state-of-the-art generative transformer significantly improves its performance, and outperforms recent diffusion models and GANs in terms of the trade-off between generated image quality and diversity, in the challenging class-conditional ImageNet generation.
https://arxiv.org/abs/2209.04439



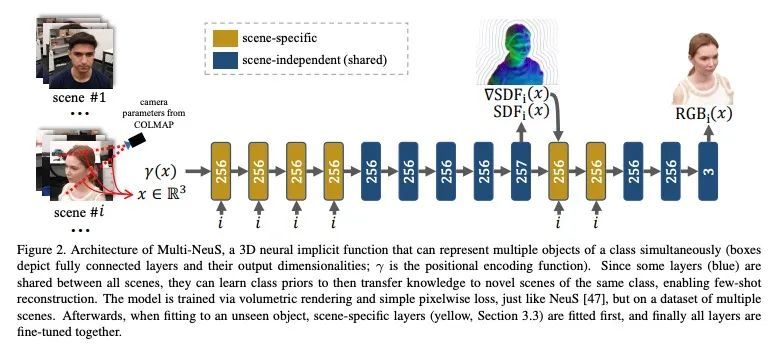
4、[CV] Multi-NeuS: 3D Head Portraits from Single Image with Neural Implicit Functions
E Burkov, R Rakhimov, A Safin, E Burnaev, V Lempitsky
[Skoltech & Cinemersive Labs]
Multi-NeuS:基于神经隐函数从单一图像中获得3D头部肖像。本文提出一种从一个或几个视图中重建具有纹理的人体头部3D网格的方法。由于这种少样本照片重建是受限的,需要先验知识,而这是很难强加给传统的3D重建算法的。本文依靠最近提出的3D表示法——神经隐函数,基于神经网络,可以自然地从数据中学习关于人体头部的先验知识,并可直接转换为纹理网格。本文扩展了NeuS,一个最先进的神经隐含函数表述,以同时表示一个类别的多个目标(在本文中是人体头部)。底层的神经网结构被设计为学习这些目标之间的共性,并对未见过的目标进行泛化。所提出模型只需在100个智能手机视频上进行训练,不需要任何扫描的3D数据,可以在少样本或单样本模式下自适应新的头部,并取得良好的效果。
We present an approach for the reconstruction of textured 3D meshes of human heads from one or few views. Since such few-shot reconstruction is underconstrained, it requires prior knowledge which is hard to impose on traditional 3D reconstruction algorithms. In this work, we rely on the recently introduced 3D representation — neural implicit functions — which, being based on neural networks, allows to naturally learn priors about human heads from data, and is directly convertible to textured mesh. Namely, we extend NeuS, a state-of-the-art neural implicit function formulation, to represent multiple objects of a class (human heads in our case) simultaneously. The underlying neural net architecture is designed to learn the commonalities among these objects and to generalize to unseen ones. Our model is trained on just a hundred smartphone videos and does not require any scanned 3D data. Afterwards, the model can fit novel heads in the few-shot or one-shot modes with good results.
https://arxiv.org/abs/2209.04436


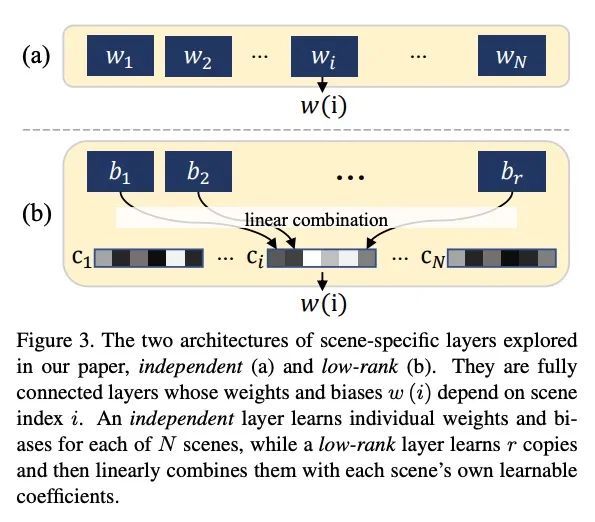
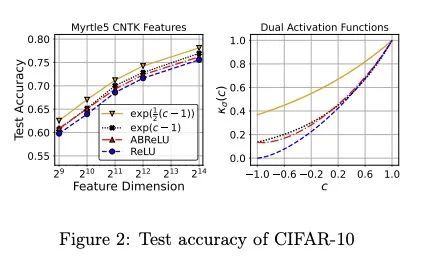
5、[CV] Fast Neural Kernel Embeddings for General Activations
I Han, A Zandieh, J Lee, R Novak, L Xiao, A Karbasi
[Yale University & Max-Planck-Institut für Informatik & Google Research]
通用激活的快速神经核嵌入。无限宽度限制通过建立神经网络和核方法之间的联系,阐明了深度学习的泛化和优化方面。尽管它们很重要,但由于其(超)二次方的运行时间和内存复杂性,这些核方法在大规模学习环境中的效用有限。此外,大多数先前关于神经核的工作都集中在ReLU激活上,这主要是由于它的流行,但也是由于为一般激活计算这种核的困难。本文通过提供处理一般激活的方法来克服这些困难。首先,本文汇编并扩展了允许精确双激活表达的激活函数列表,以计算神经核。当确切的计算结果未知时,本文提出了有效地近似它们的方法。提出了一种快速勾画的方法,可以近似任意多层神经网络高斯过程(NNGP)核和神经切线核(NT)矩阵,用于广泛的激活函数,超越了通常分析的ReLU激活。这是通过展示如何使用任何所需激活函数的截断的Hermite扩展来近似神经核来实现的。本文为NNGP和NTK矩阵提供了一个子空间嵌入,其运行时间接近输入稀疏度,目标维度接近最优,适用于任意具有快速收敛泰勒扩展的同质双激活函数。根据经验,与精确的卷积NTK(CNTK)计算相比,所提出方法在CIFAR-10数据集上对5层Myrtle网络的近似CNTK实现了106倍的加速。
Infinite width limit has shed light on generalization and optimization aspects of deep learning by establishing connections between neural networks and kernel methods. Despite their importance, the utility of these kernel methods was limited in large-scale learning settings due to their (super-)quadratic runtime and memory complexities. Moreover, most prior works on neural kernels have focused on the ReLU activation , mainly due to its popularity but also due to the difficulty of computing such kernels for general activations. In this work, we overcome such difficulties by providing methods to work with general activations. First, we compile and expand the list of activation functions admitting exact dual activation expressions to compute neural kernels. When the exact computation is unknown, we present methods to effectively approximate them. We propose a fast sketching method that approximates any multi-layered Neural Network Gaussian Process (NNGP) kernel and Neural Tangent Kernel (NTK) matrices for a wide range of activation functions, going beyond the commonly analyzed ReLU activation. This is done by showing how to approximate the neural kernels using the truncated Hermite expansion of any desired activation functions. While most prior works require data points on the unit sphere, our methods do not suffer from such limitations and are applicable to any dataset of points in R. Furthermore, we provide a subspace embedding for NNGP and NTK matrices with near input-sparsity runtime and near-optimal target dimension which applies to any homogeneous dual activation functions with rapidly convergent Taylor expansion. Empirically, with respect to exact convolutional NTK (CNTK) computation, our method achieves 106× speedup for approximate CNTK of a 5-layer Myrtle network on CIFAR-10 dataset.
https://arxiv.org/abs/2209.04121


另外几篇值得关注的论文:
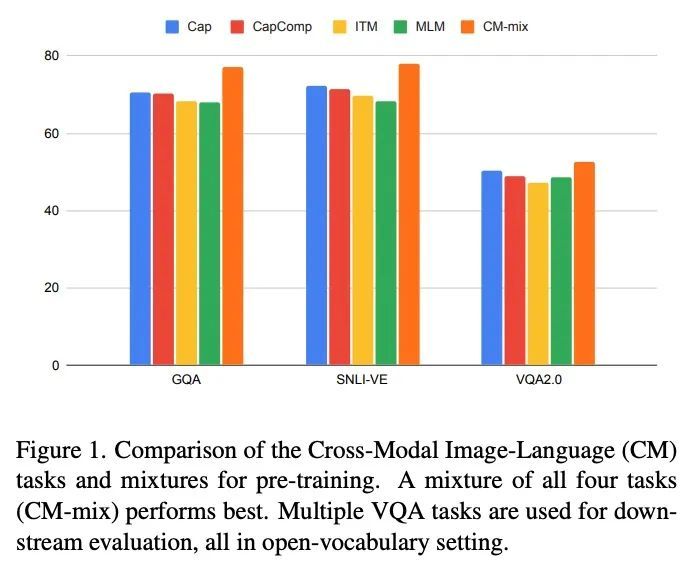
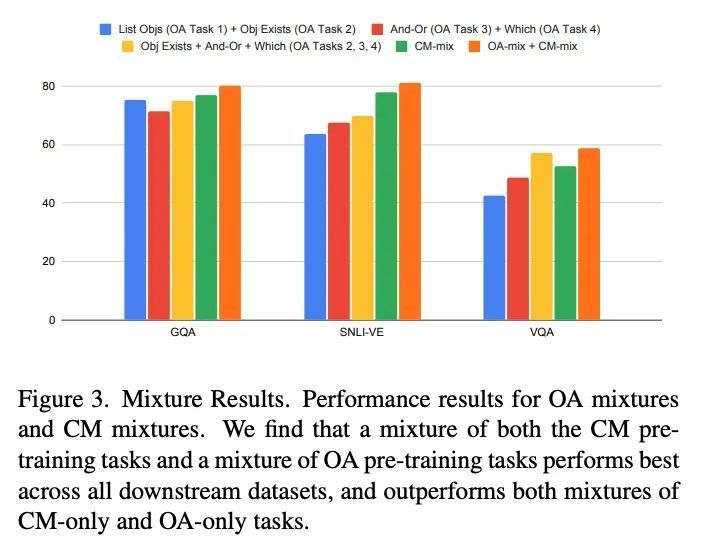
[CV] Pre-training image-language transformers for open-vocabulary tasks
面向开放词表任务的图像-语言Transformer预训练
A Piergiovanni, W Kuo, A Angelova
[Google Research]
https://arxiv.org/abs/2209.04372


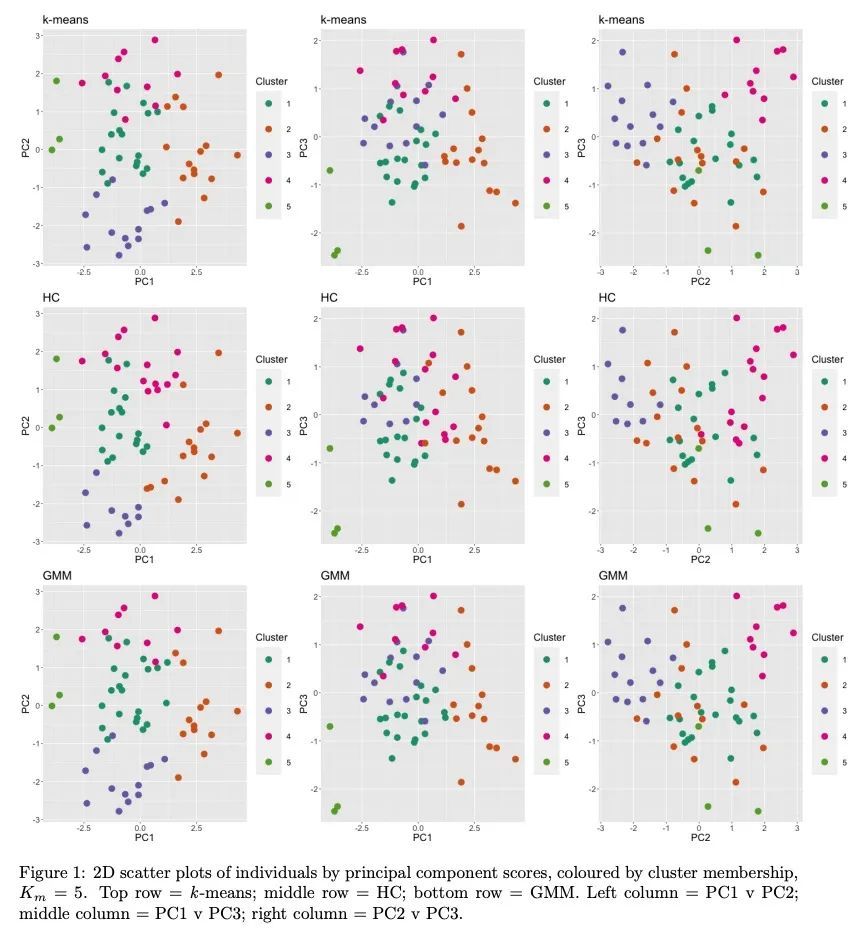
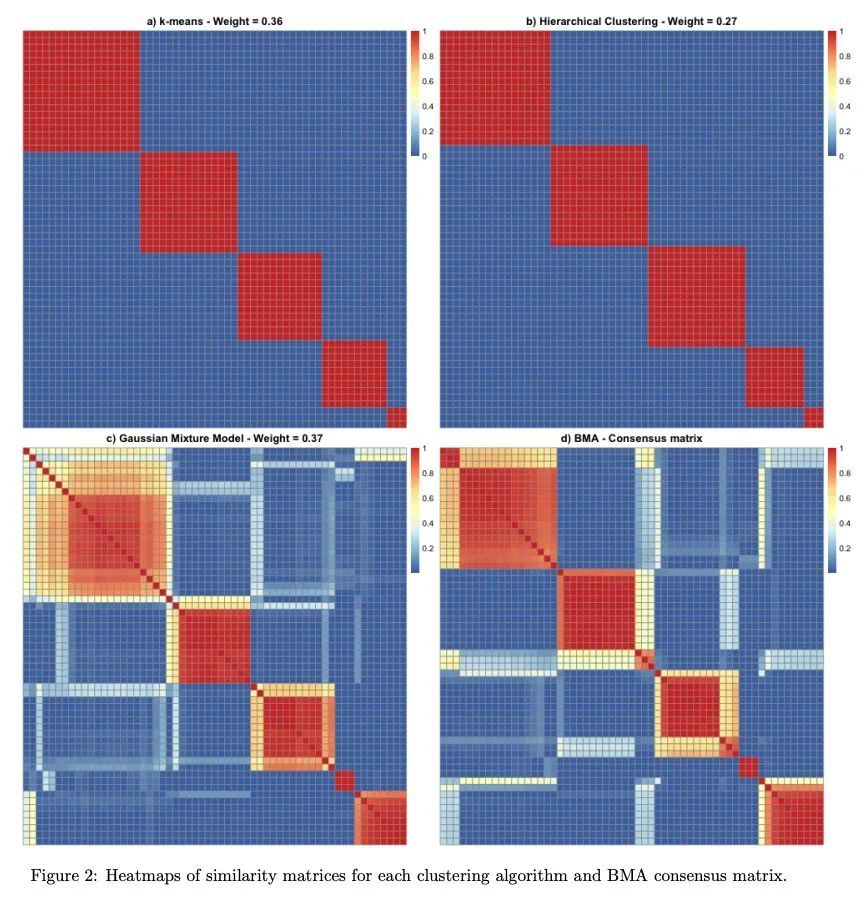
[LG] clusterBMA: Bayesian model averaging for clustering
clusterBMA:聚类的贝叶斯模型平均
O Forbes, E Santos-Fernandez, P P Wu, H Xie...
[Queensland University of Technology & University of the Sunshine Coast]
https://arxiv.org/abs/2209.04117

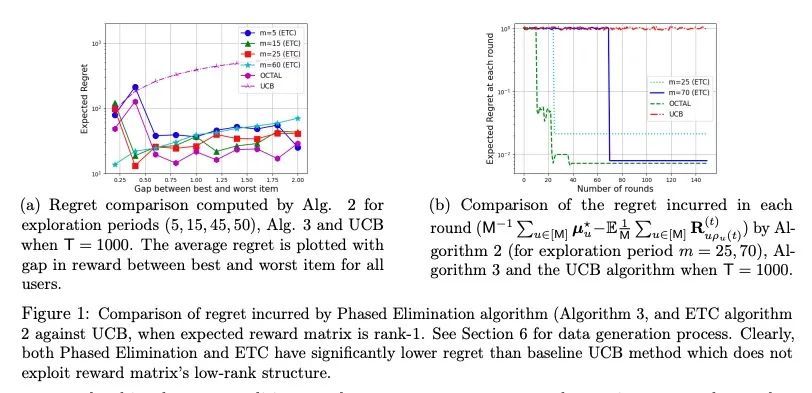
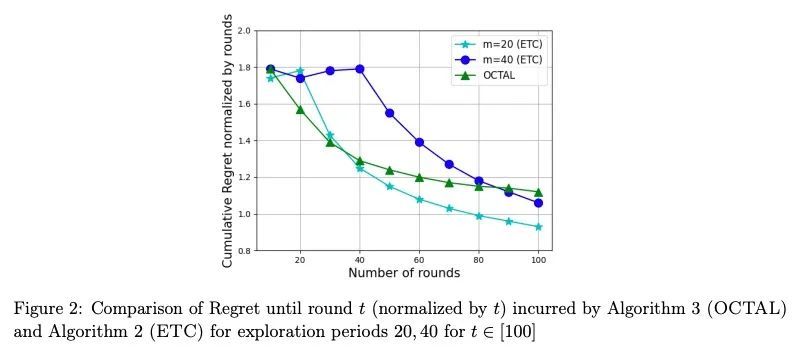
[LG] Online Low Rank Matrix Completion
在线低秩矩阵补全
P Jain, S Pal
[Google Research at Bangalore]
https://arxiv.org/abs/2209.03997

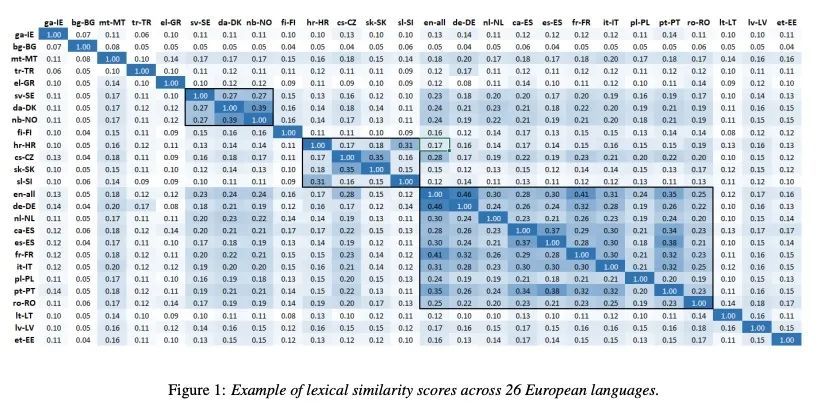
[CL] Multilingual Transformer Language Model for Speech Recognition in Low-resource Languages
面向低资源语言语音识别的多语Transformer语言模型
L Miao, J Wu, P Behre, S Chang, S Parthasarathy
[Microsoft]
https://arxiv.org/abs/2209.04041

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢