
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自:爱可可爱生活
摘要:PDE建模的Clifford神经层、面向机器人操纵的多任务Transformer、面向视频文本检索的端到端多粒度对比学习、软扩散:通用破损的分数匹配、显式可控3D感知肖像生成、自适应隐最大似然估计、模型模排列对称性合并、控制统计学习理论、深度学习的8位浮点(FP8)规格
1、[LG] Clifford Neural Layers for PDE Modeling
J Brandstetter, R v d Berg, M Welling, J K. Gupta
[Microsoft Research Amsterdam]
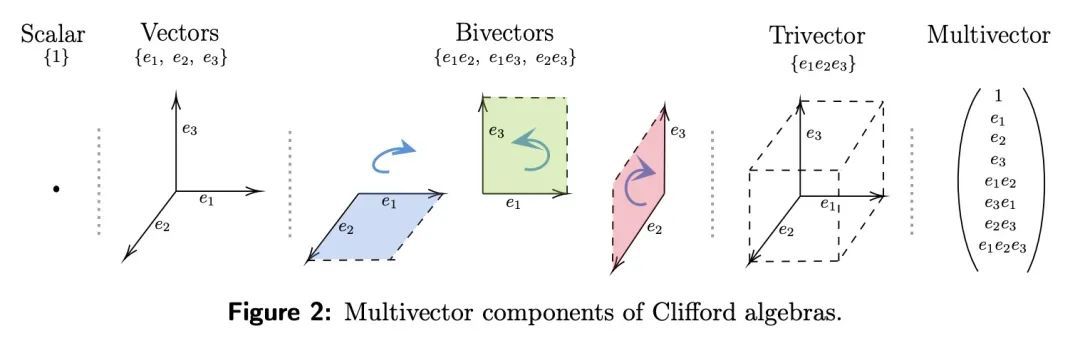
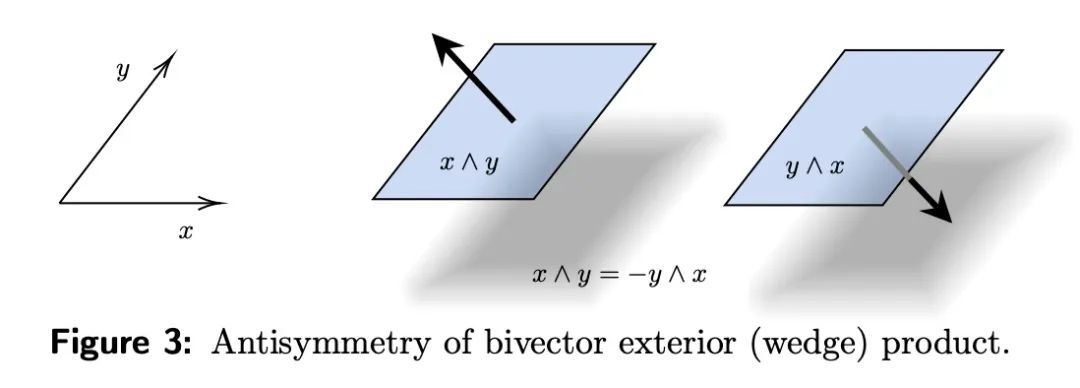
PDE建模的Clifford神经层。偏微分方程(PDE)在科学和工程领域被广泛使用,用来描述物理过程的仿真,如标量和矢量场随着时间的推移而相互作用和共同演化。由于其标准求解方法的计算成本很高,神经PDE替代物已经成为一个活跃的研究课题,以加速这些仿真。然而,目前的方法并没有明确考虑到不同场和其内部成分之间的关系,这些成分往往是相关的。通过多矢量场的视角来看待这种相关场的时间演化,就可以克服这些限制。多向量场由标量、向量以及高阶成分组成,如双向量和三向量。它们的代数特性,如乘法、加法和其他算术运算,可以用Clifford代数来描述。本文首次在深度学习的背景下使用了这种多向量表示以及Clifford卷积和Clifford傅里叶变换。由此产生的Clifford神经层是普遍适用的,并将在流体力学、天气预报和通用物理系统的建模领域找到直接用途。通过在2D纳维-斯托克斯和天气建模任务以及3D麦克斯韦方程中用Clifford对应的神经PDE替代卷积和傅里叶操作来实证评估Clifford神经层的好处。Clifford神经层持续改善了所测试的神经PDE智能体的泛化能力。
Partial differential equations (PDEs) see widespread use in sciences and engineering to describe simulation of physical processes as scalar and vector fields interacting and coevolving over time. Due to the computationally expensive nature of their standard solution methods, neural PDE surrogates have become an active research topic to accelerate these simulations. However, current methods do not explicitly take into account the relationship between different fields and their internal components, which are often correlated. Viewing the time evolution of such correlated fields through the lens of multivector fields allows us to overcome these limitations. Multivector fields consist of scalar, vector, as well as higher-order components, such as bivectors and trivectors. Their algebraic properties, such as multiplication, addition and other arithmetic operations can be described by Clifford algebras. To our knowledge, this paper presents the first usage of such multivector representations together with Clifford convolutions and Clifford Fourier transforms in the context of deep learning. The resulting Clifford neural layers are universally applicable and will find direct use in the areas of fluid dynamics, weather forecasting, and the modeling of physical systems in general. We empirically evaluate the benefit of Clifford neural layers by replacing convolution and Fourier operations in common neural PDE surrogates by their Clifford counterparts on two-dimensional Navier-Stokes and weather modeling tasks, as well as three-dimensional Maxwell equations. Clifford neural layers consistently improve generalization capabilities of the tested neural PDE surrogates.
https://arxiv.org/abs/2209.04934


2、[RO] Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation
M Shridhar, L Manuelli, D Fox
[University of Washington]
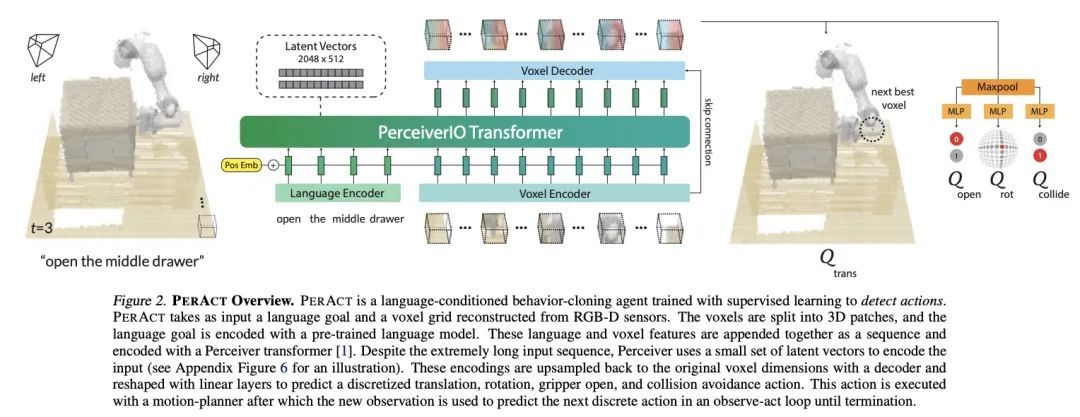
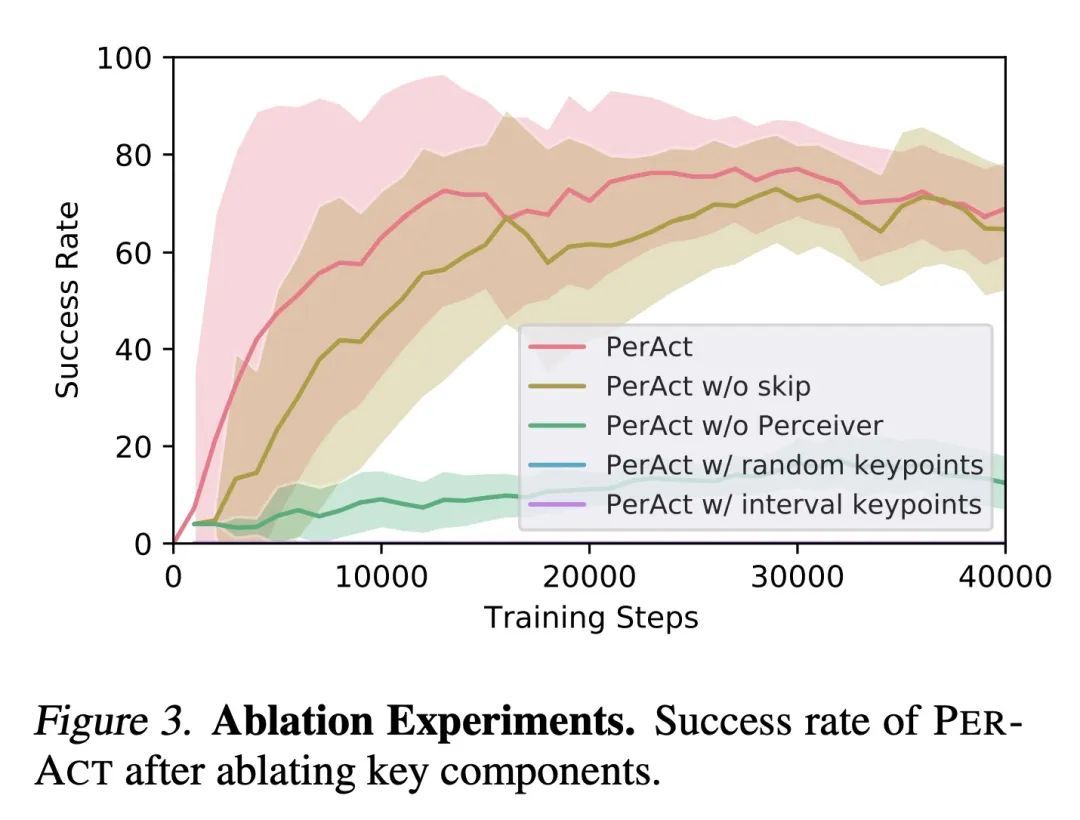
Perceiver-Actor:面向机器人操纵的多任务Transformer。Transformer以其对大型数据集的扩展能力彻底改变了视觉和自然语言处理。但在机器人操纵中,数据既有限又昂贵。通过正确的问题表述,我们还能从Transformer中获益吗?本文用PerAct研究这个问题,PerAct是一个以语言为条件的行为克隆智能体,用于多任务6-DoF操纵。PerAct用Perceiver Transformer对语言目标和RGB-D体素观察进行编码,并通过"检测下一最佳体素行动"输出离散的行动。与在2D图像上操作的框架不同,体素化的观察和行动空间为有效学习6-DoF策略提供了强大的结构性先验。通过这种方法,本文为18个RLBench任务(有249种变化)和7个真实世界的任务(有18种变化)训练了一个单一的多任务Transformer,每个任务只需要几个演示。实验结果表明,PerAct在广泛的桌面任务中明显优于非结构化图像-动作智能体和3D ConvNet基线。
Transformers have revolutionized vision and natural language processing with their ability to scale with large datasets. But in robotic manipulation, data is both limited and expensive. Can we still benefit from Transformers with the right problem formulation? We investigate this question with PerAct, a language-conditioned behavior-cloning agent for multi-task 6-DoF manipulation. PerAct encodes language goals and RGB-D voxel observations with a Perceiver Transformer, and outputs discretized actions by "detecting the next best voxel action". Unlike frameworks that operate on 2D images, the voxelized observation and action space provides a strong structural prior for efficiently learning 6-DoF policies. With this formulation, we train a single multi-task Transformer for 18 RLBench tasks (with 249 variations) and 7 real-world tasks (with 18 variations) from just a few demonstrations per task. Our results show that PerAct significantly outperforms unstructured image-to-action agents and 3D ConvNet baselines for a wide range of tabletop tasks.
https://arxiv.org/abs/2209.05451


3、[CV] X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval
Y Ma, G Xu, X Sun, M Yan, J Zhang, R Ji
[Xiamen University & DAMO Academy, Alibaba Group]
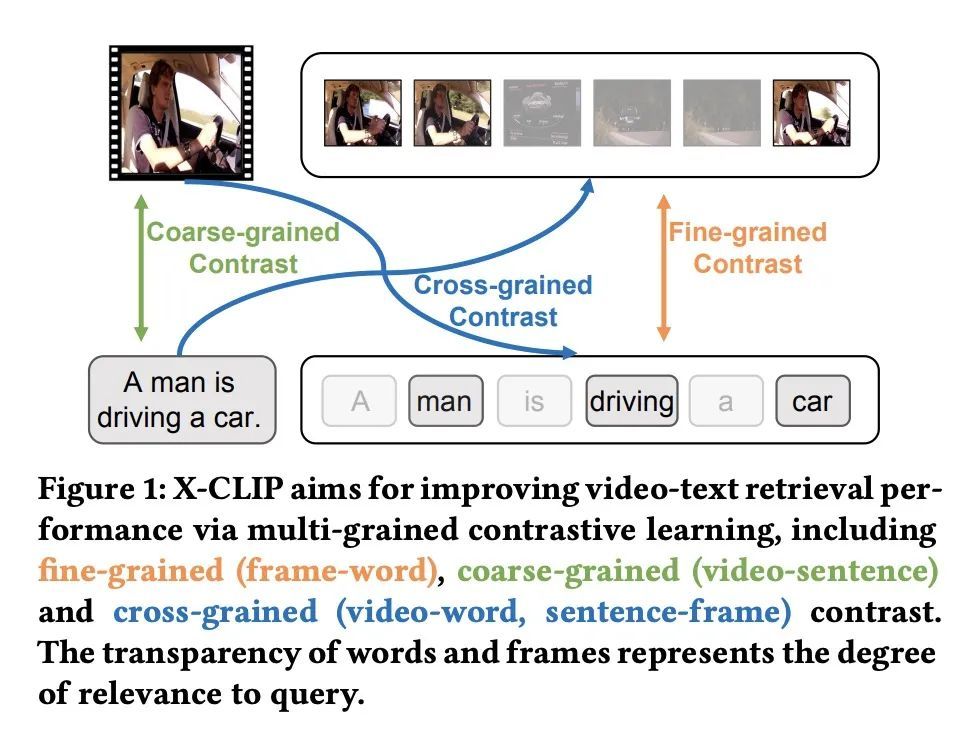
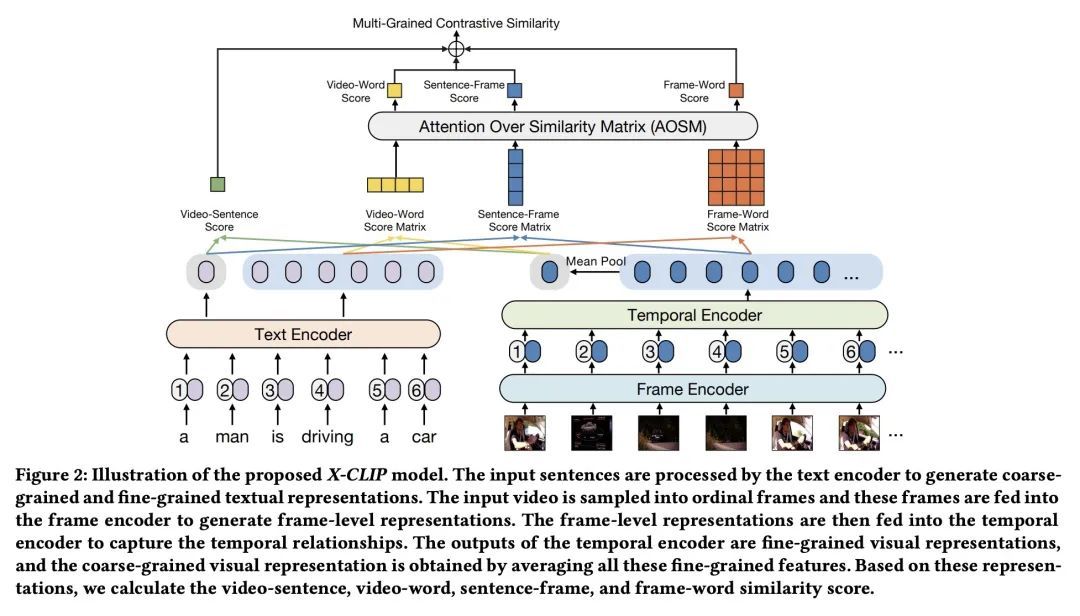
X-CLIP:面向视频文本检索的端到端多粒度对比学习。视频文本检索是多模态研究中一项重要的基本任务。大规模多模态对比预训练极大促进了视频文本检索的发展,这种训练主要集中在粗粒度或细粒度的对比上。然而,跨粒度对比,也就是粗粒度表示和细粒度表示之间的对比,在之前研究中很少被探讨过。与细粒度或粗粒度对比相比,跨粒度对比计算了粗粒度表示与每个细粒度表示之间的相关性,在相似性计算过程中能过滤掉由粗粒度特征引导的不必要的细粒度特征,从而提高检索的准确性。为此,本文提出一种新的多粒度对比模型X-CLIP,用于视频-文本检索。然而,另一个挑战在于相似性聚合问题,其目的是将细粒度和跨粒度的相似性矩阵聚合到实例级相似性。为了解决这一挑战,本文提出"相似度矩阵注意力"(AOSM)模块,使模型专注于必要的帧和词之间的对比,从而降低了不必要的帧和词对检索结果的影响。利用多粒度对比和提出的AOSM模块,X-CLIP在五个广泛使用的视频-文本检索数据集上取得了出色的性能,显示了多粒度对比和AOSM的优越性。
Video-text retrieval has been a crucial and fundamental task in multi-modal research. The development of video-text retrieval has been considerably promoted by large-scale multi-modal contrastive pre-training, which primarily focuses on coarse-grained or fine-grained contrast. However, cross-grained contrast, which is the contrast between coarse-grained representations and fine-grained representations, has rarely been explored in prior research. Compared with fine-grained or coarse-grained contrasts, cross-grained contrast calculate the correlation between coarse-grained features and each fine-grained feature, and is able to filter out the unnecessary fine-grained features guided by the coarse-grained feature during similarity calculation, thus improving the accuracy of retrieval. To this end, this paper presents a novel multi-grained contrastive model, namely X-CLIP, for video-text retrieval. However, another challenge lies in the similarity aggregation problem, which aims to aggregate fine-grained and cross-grained similarity matrices to instance-level similarity. To address this challenge, we propose the Attention Over Similarity Matrix (AOSM) module to make the model focus on the contrast between essential frames and words, thus lowering the impact of unnecessary frames and words on retrieval results. With multi-grained contrast and the proposed AOSM module, X-CLIP achieves outstanding performance on five widely-used video-text retrieval datasets, including MSR-VTT (49.3 R@1), MSVD (50.4 R@1), LSMDC (26.1 R@1), DiDeMo (47.8 R@1) and ActivityNet (46.2 R@1). It outperforms the previous state-of-theart by +6.3%, +6.6%, +11.1%, +6.7%, +3.8% relative improvements on these benchmarks, demonstrating the superiority of multi-grained contrast and AOSM.
https://arxiv.org/abs/2207.07285


4、[CV] Soft Diffusion: Score Matching for General Corruptions
G Daras, M Delbracio, H Talebi, A G. Dimakis, P Milanfar
[Google Research & UT Austin]
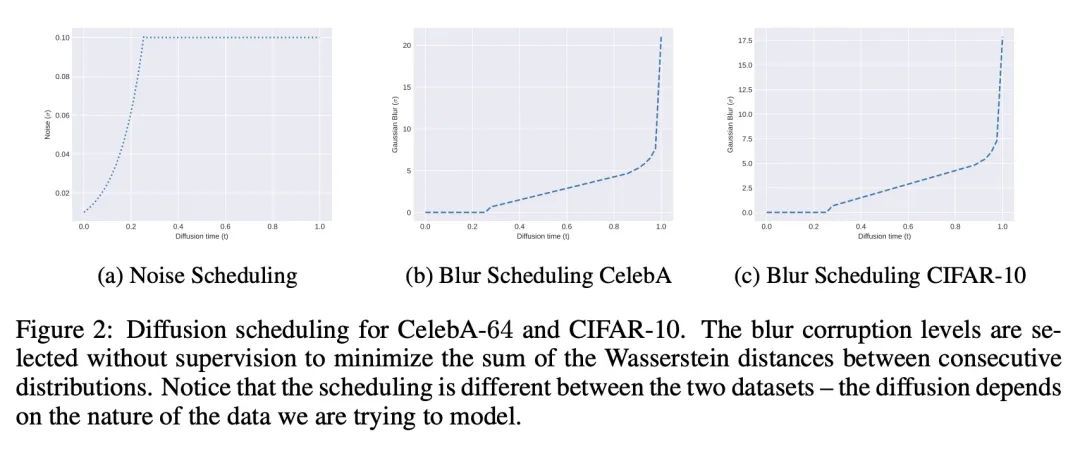
软扩散:通用破损的分数匹配。本文定义了一个更广泛的破损过程系列,推广了之前已知的扩散模型。为扭转这些一般的扩散,提出了一种新的目标,称为软分数匹配,可以证明学习任意线性破损过程的分数函数,并产生CelebA的最先进的结果。软分数匹配将退化过程纳入网络,并训练模型预测一个干净的图像,该图像在破损后与扩散的观察结果相匹配。所提目标是在适当的规则性条件下学习破损过程系列的似然梯度。进一步开发了一种原则性的方法来选择一般扩散过程的破损水平,以及一种称为动量采样器的新采样方法。对所提框架进行了评估,破损是高斯模糊和低量级加性噪声。所提方法在CelebA64上实现了最先进的FID得分1.85,超过了之前所有的线性扩散模型。我们还显示了与vanilla去噪扩散相比的重大计算优势。
We define a broader family of corruption processes that generalizes previously known diffusion models. To reverse these general diffusions, we propose a new objective called Soft Score Matching that provably learns the score function for any linear corruption process and yields state of the art results for CelebA. Soft Score Matching incorporates the degradation process in the network and trains the model to predict a clean image that after corruption matches the diffused observation. We show that our objective learns the gradient of the likelihood under suitable regularity conditions for the family of corruption processes. We further develop a principled way to select the corruption levels for general diffusion processes and a novel sampling method that we call Momentum Sampler. We evaluate our framework with the corruption being Gaussian Blur and low magnitude additive noise. Our method achieves state-of-the-art FID score 1.85 on CelebA64, outperforming all previous linear diffusion models. We also show significant computational benefits compared to vanilla denoising diffusion.
https://arxiv.org/abs/2209.05442



5、[CV] Explicitly Controllable 3D-Aware Portrait Generation
J Tang, B Zhang, B Yang, T Zhang, D Chen, L Ma, F Wen
[Shanghai Jiao Tong University & University of Science and Technology of China & Microsoft Research Asia]
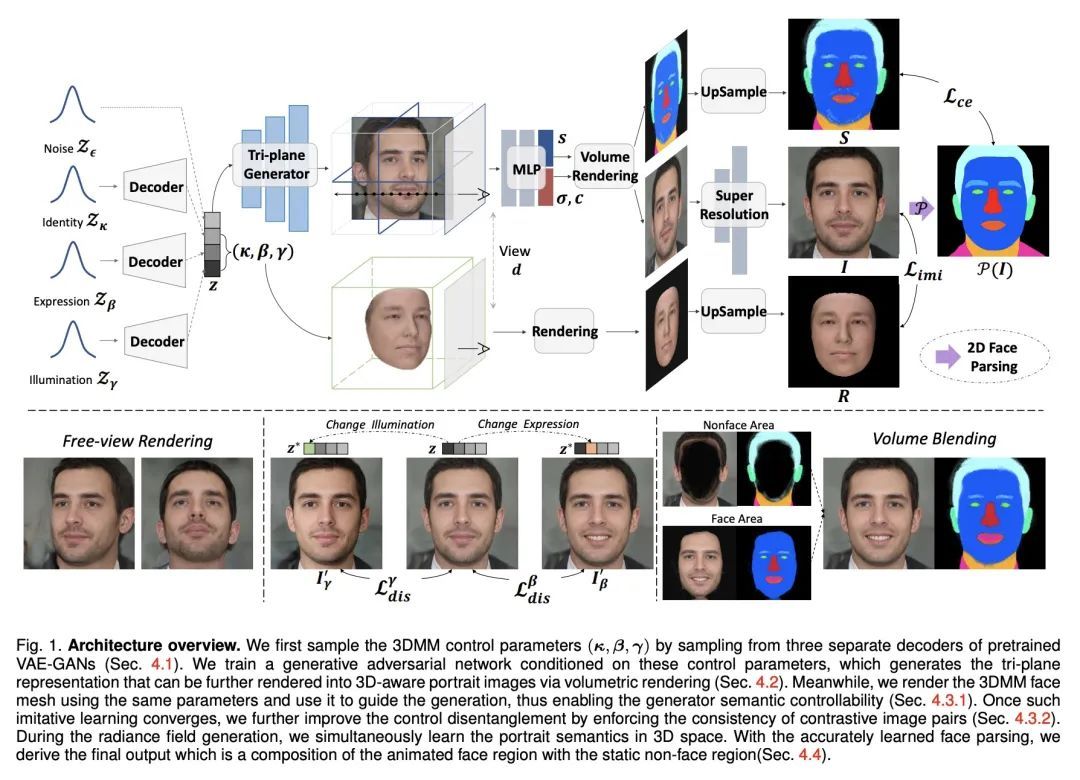
显式可控3D感知肖像生成。与传统昂贵的化身创建管线相比,当代的生成方法直接从照片中学习数据分布,现在的技术水平可产生高度逼真的图像。虽然大量工作试图扩展无条件生成模型,并实现某种程度的可控性,但要确保多视图的一致性仍然具有挑战性,特别是在大的姿态中。本文提出一种3D人像生成网络,能产生3D一致的人像,同时可根据关于姿态、身份、表情和照明的语义参数进行控制。生成网络使用神经场景表示来建立3D肖像模型,其生成由支持显式控制的参数化脸部模型引导。虽然可以通过对比具有部分不同属性的图像来进一步增强潜在的离散性,但在表情动画化时,在非面部区域,例如头发和背景,仍然存在明显的不一致。本文通过提出一个体混合策略来解决该问题,在该策略中,通过混合动态和静态辐射场形成一个复合输出,其中两部分是从联合学习的语义场中分割出来的。在大量的实验中,所提出方法优于之前的技术水平,当以自由视角观看时,在自然光下产生具有生动表情的逼真肖像。所提出方法还展示了对真实图像以及域外卡通脸的泛化能力,显示了在实际应用中的巨大前景。
In contrast to the traditional avatar creation pipeline which is a costly process, contemporary generative approaches directly learn the data distribution from photographs and the state of the arts can now yield highly photo-realistic images. While plenty of works attempt to extend the unconditional generative models and achieve some level of controllability, it is still challenging to ensure multi-view consistency, especially in large poses. In this work, we propose a 3D portrait generation network that produces 3D consistent portraits while being controllable according to semantic parameters regarding pose, identity, expression and lighting. The generative network uses neural scene representation to model portraits in 3D, whose generation is guided by a parametric face model that supports explicit control. While the latent disentanglement can be further enhanced by contrasting images with partially different attributes, there still exists noticeable inconsistency in non-face areas, e.g., hair and background, when animating expressions. We solve this by proposing a volume blending strategy in which we form a composite output by blending the dynamic and static radiance fields, with two parts segmented from the jointly learned semantic field. Our method outperforms prior arts in extensive experiments, producing realistic portraits with vivid expression in natural lighting when viewed in free viewpoint. The proposed method also demonstrates generalization ability to real images as well as out-of-domain cartoon faces, showing great promise in real applications. Additional video results and code will be available on the project webpage.
https://arxiv.org/abs/2209.05434



另外几篇值得关注的论文:
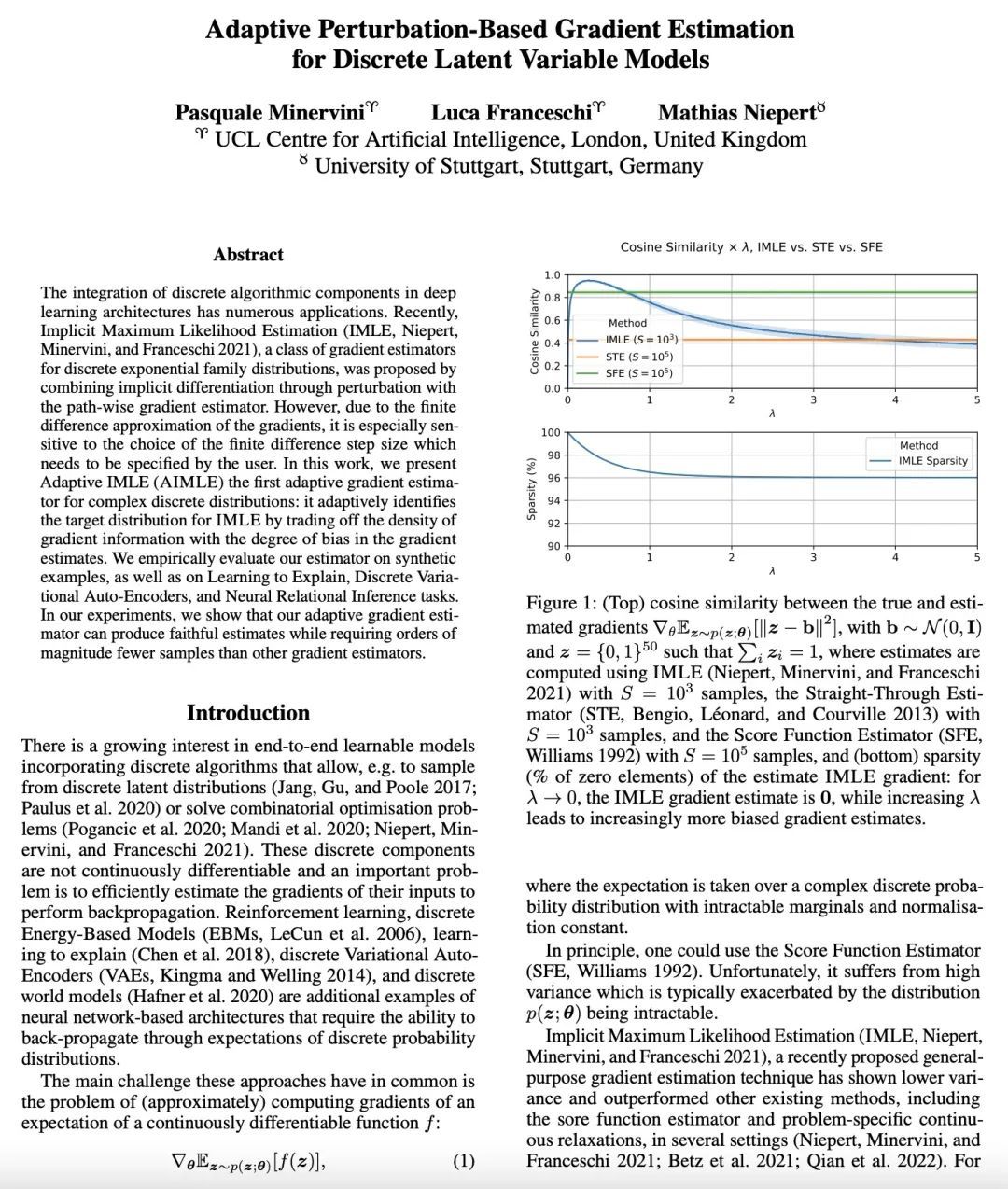
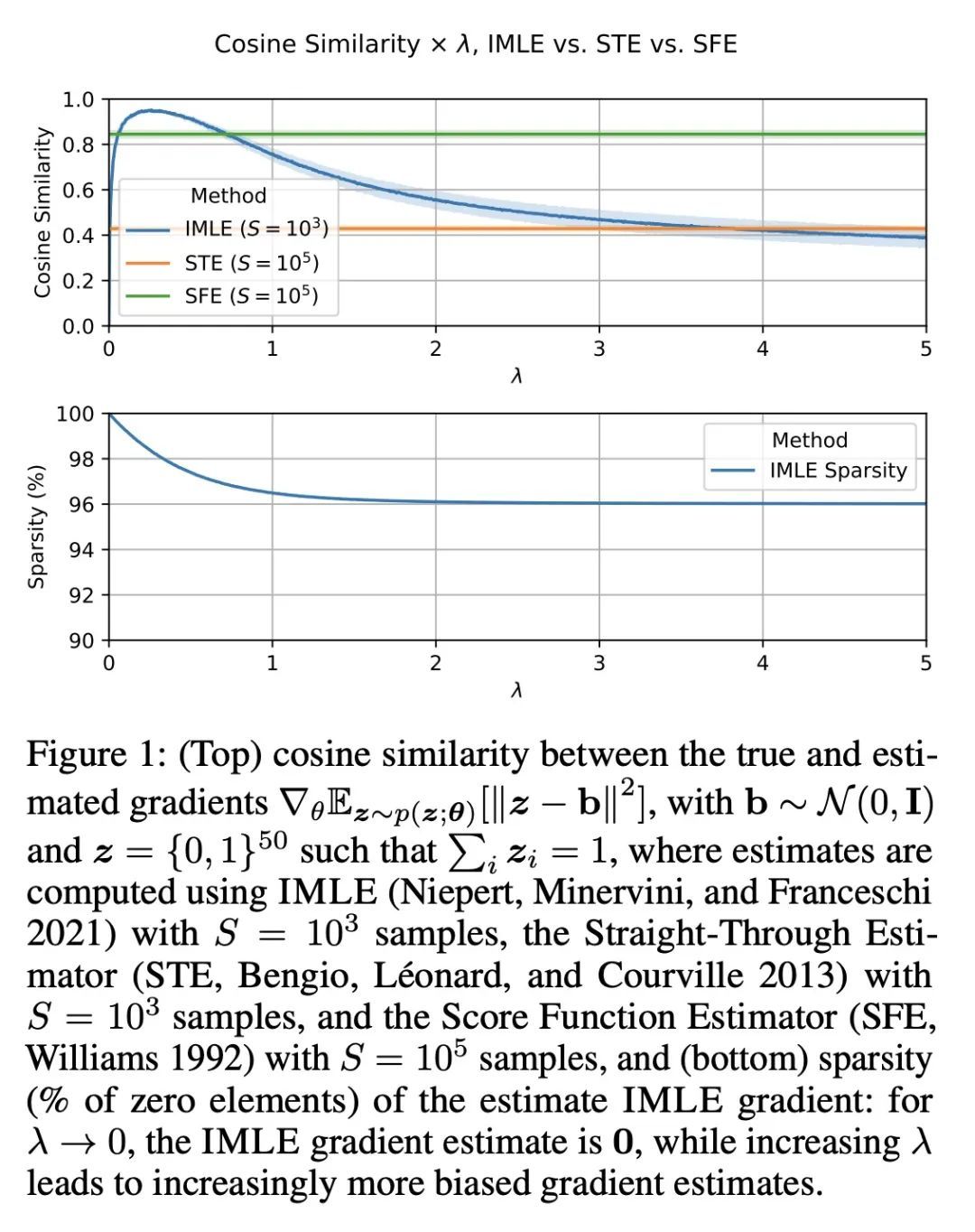
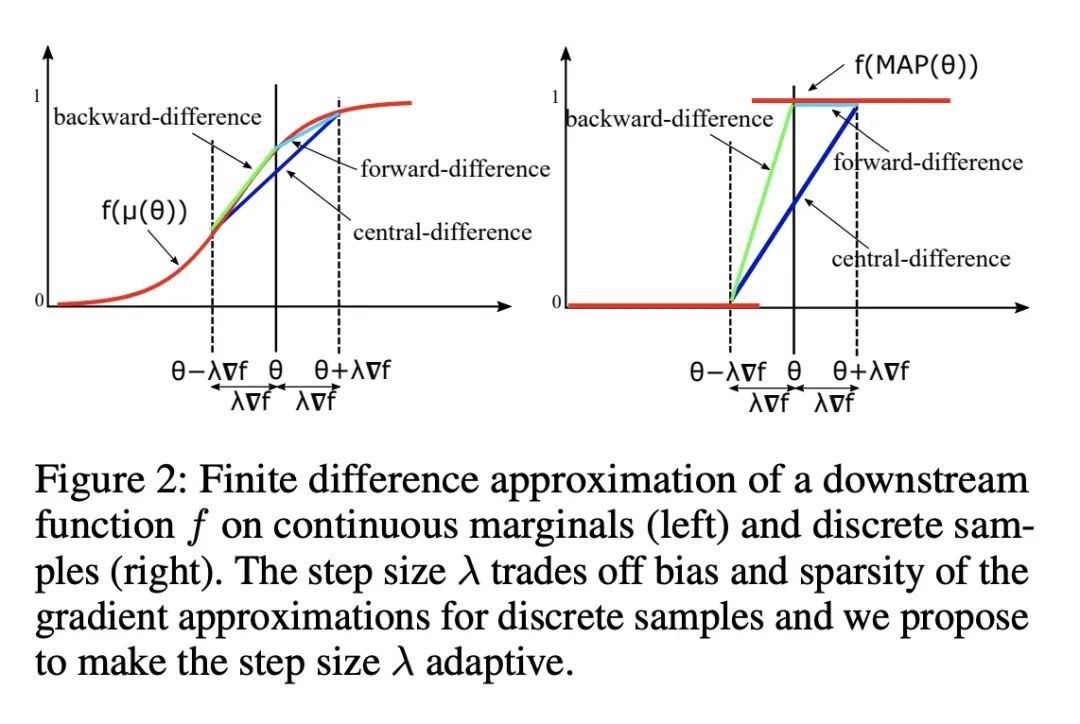
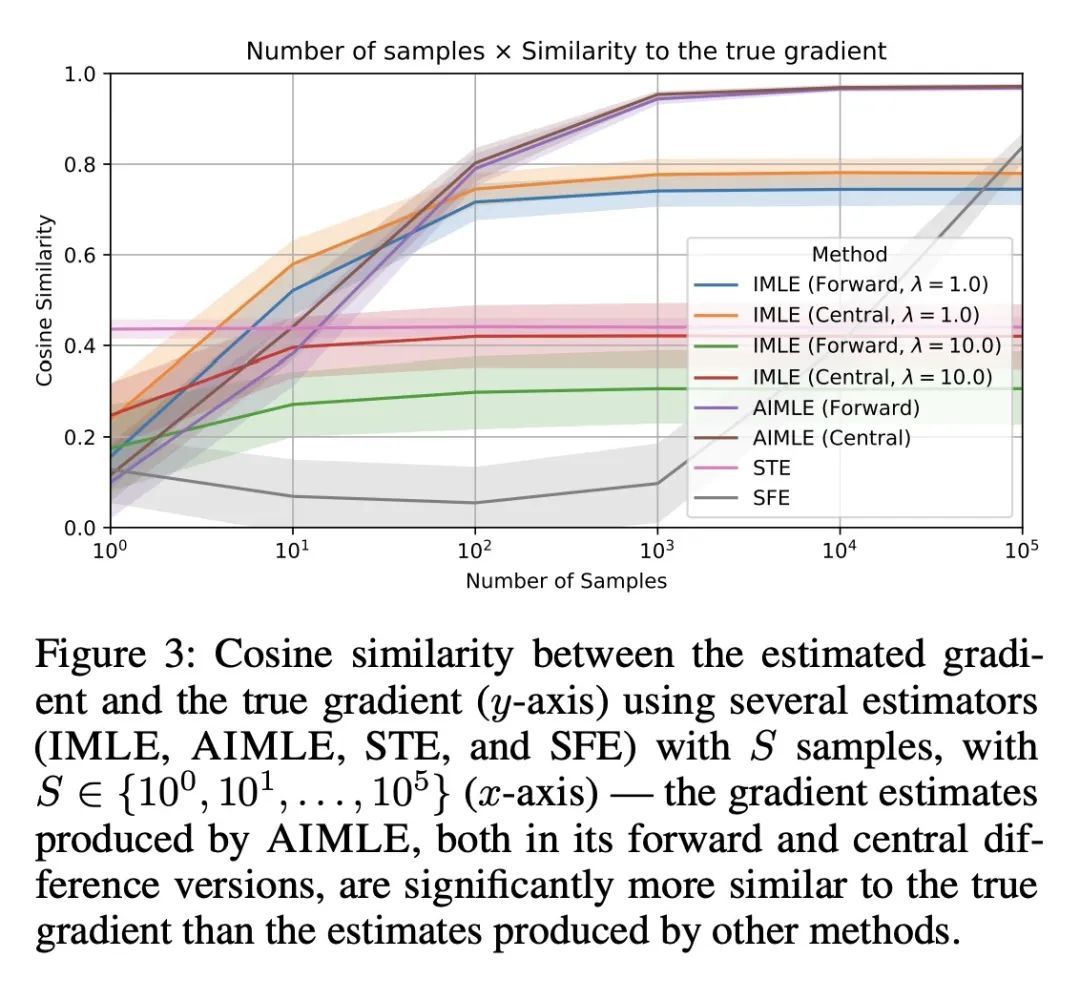
[LG] Adaptive Perturbation-Based Gradient Estimation for Discrete Latent Variable Models
自适应隐最大似然估计
P Minervini, L Franceschi, M Niepert
[UCL Centre for Artificial Intelligence & University of Stuttgart]
https://arxiv.org/abs/2209.04862
[LG] Git Re-Basin: Merging Models modulo Permutation Symmetries
Git Re-Basin:模型模排列对称性合并
S K. Ainsworth, J Hayase, S Srinivasa
[University of Washington]
https://arxiv.org/abs/2209.04836

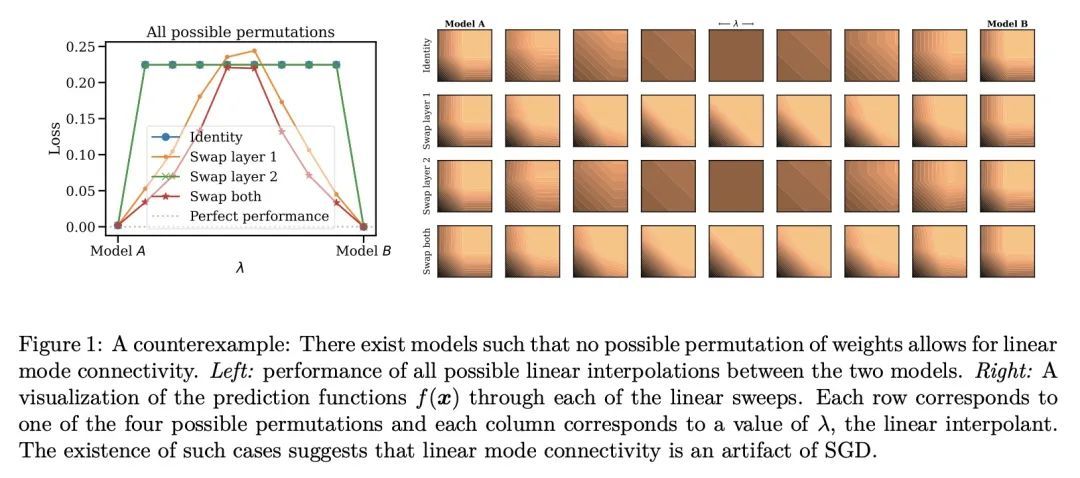
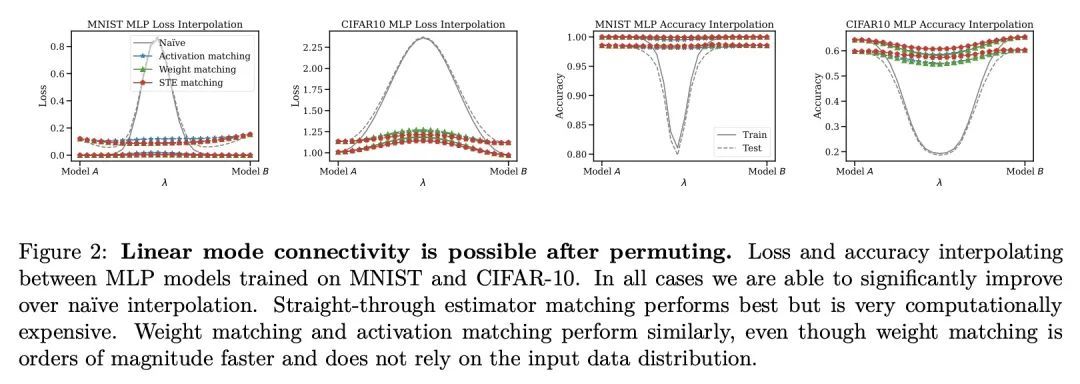
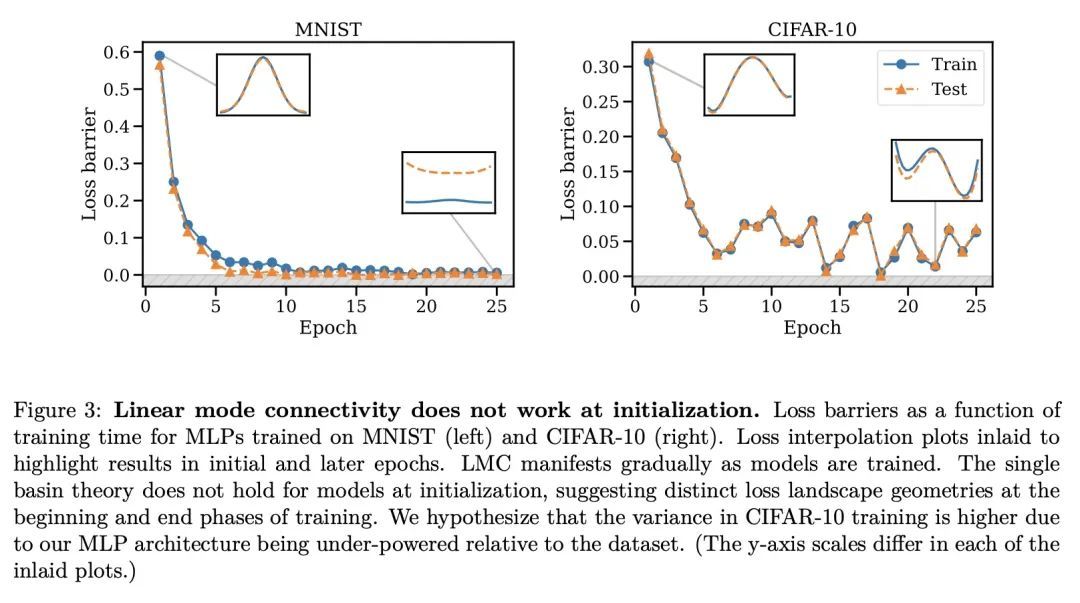
[LG] Statistical Learning Theory for Control: A Finite Sample Perspective
控制统计学习理论:有限样本视角
A Tsiamis, I Ziemann, N Matni, G J. Pappas
[ETH Zürich & KTH Royal Institute of Technology & University of Pennsylvania]
https://arxiv.org/abs/2209.05423

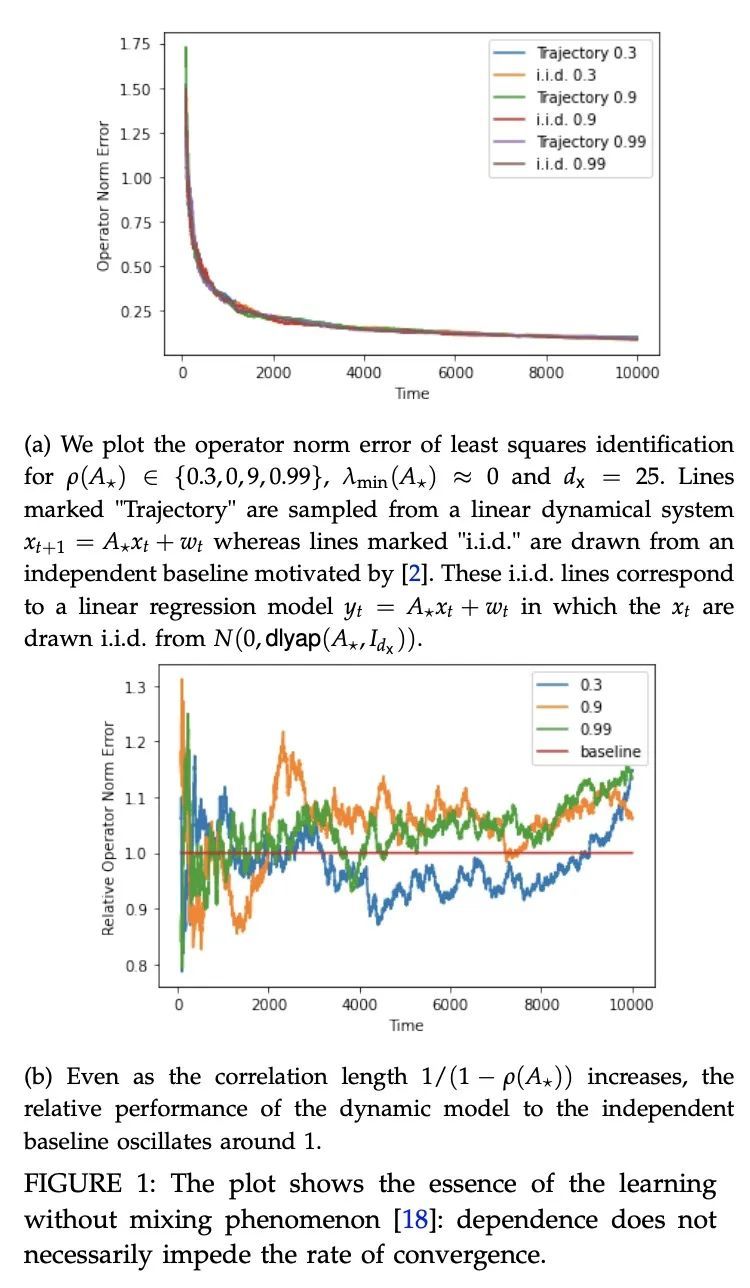
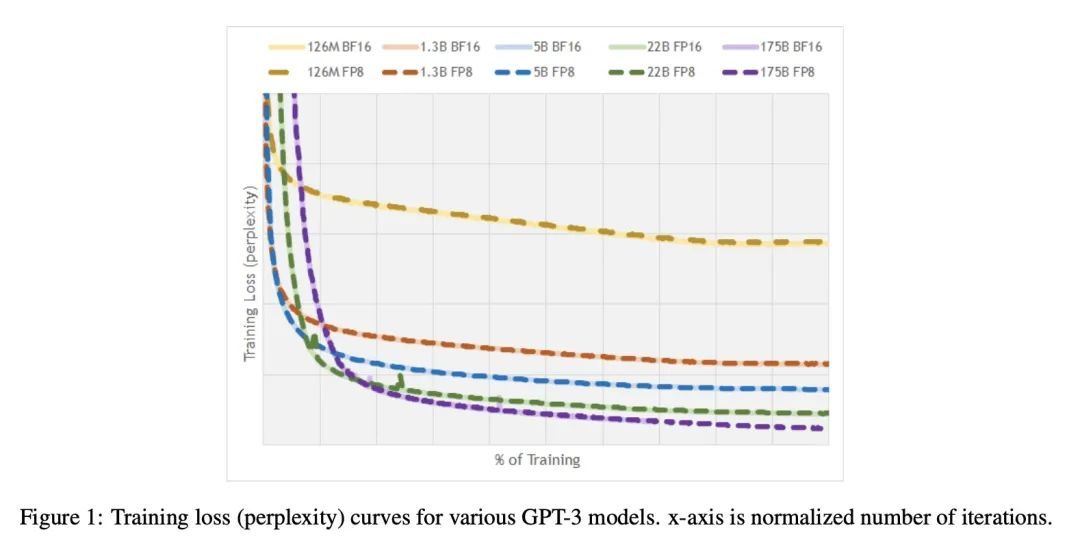
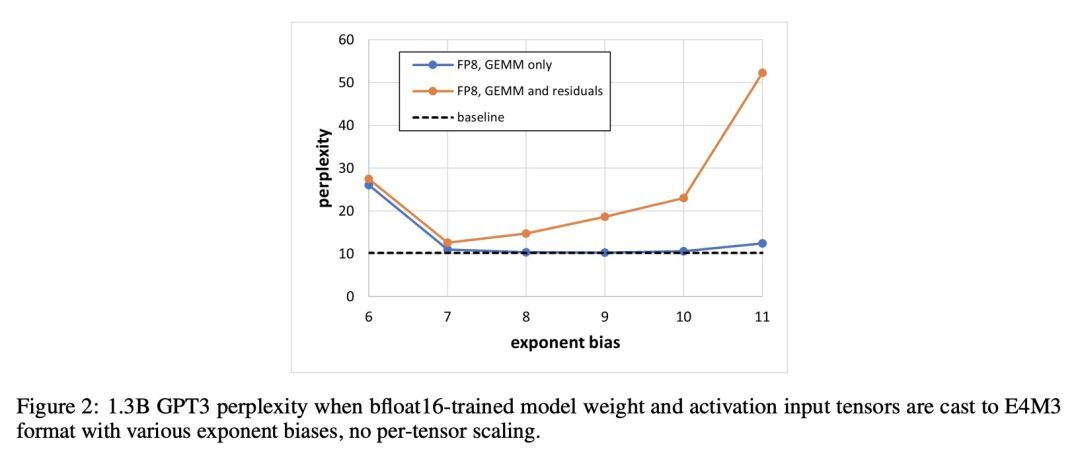
[LG] FP8 Formats for Deep Learning
深度学习的8位浮点(FP8)规格
P Micikevicius, D Stosic, N Burgess, M Cornea, P Dubey, R Grisenthwaite, S Ha, A Heinecke, P Judd, J Kamalu, N Mellempudi, S Oberman, M Shoeybi, M Siu, H Wu
[NVIDIA & Arm & Intel]
https://arxiv.org/abs/2209.05433

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢