
论文地址:https://arxiv.org/abs/2203.12515
现实世界中存在着上千种语言。为了方便人们快速理解并掌握不同语言文章的主旨,跨语言摘要(Cross-Lingual Summarization)旨在为一种语言的文档生成另一种语言的摘要。近年来此任务受到了广泛的关注,大量的数据集和模型工作不断涌出。本综述分别从数据层面和模型层面详细总结了跨语言摘要存在的典型挑战以及解决方案,指出了现有问题并对未来进行展望。
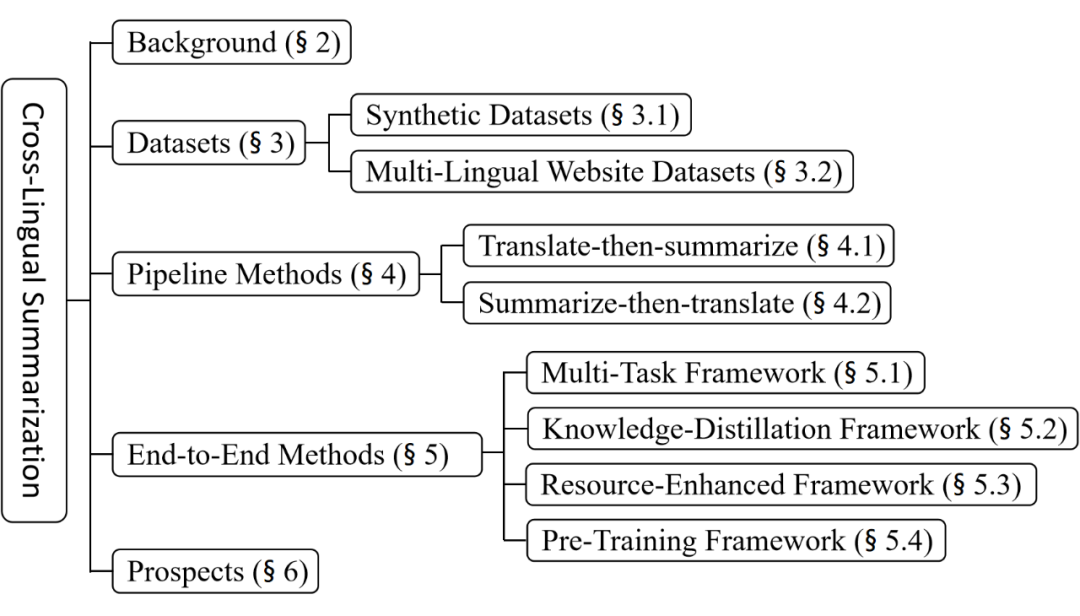
本综述的组织结构如下:
主要挑战
跨语言摘要普遍被认为是文本摘要与机器翻译的复合任务。该任务的挑战从数据和模型层面分别概括如下:
1. 从数据角度出发:不同于单语摘要,一种语言的文档与另一种语言的摘要很少成对出现。在研究初期,研究者们普遍采用人工翻译的方式构建数据集,即将单语摘要数据集中的摘要文本从源语言翻译至目标语言。所应用于早期工作的实验数据往往只有百余条样本 [15-23]。由此可见,收集大规模且高质量的跨语言摘要数据是十分困难的。
2. 从模型角度出发:跨语言摘要需要模型同时掌握摘要与翻译能力,这使得模型直接完成跨语言摘要任务充满挑战 [25]。早期的研究为了规避掉这一挑战点,普遍采用 pipeline 的方式,即先摘要后翻译或先翻译后摘要。然而这种方式误差传播严重、推理速度缓慢且严重依赖于机器翻译的效果,因此并不满足现实需求。近几年的研究也表明了端到端的方式优于 pipeline 方式。尽管如此,端到端的跨语言摘要模型距离落地还有很长的路要走。
数据集分类
为了缓解数据难收集的痛点,研究员们探索出了两种不同的方式来构建跨语言摘要数据集。据此,我们将现有数据集分为合成数据集与多语言网站数据集。
合成数据集
合成数据集通过将已有单语摘要数据集的摘要文本翻译至目标语言来构建跨语言摘要样本。例如 Zhu 等人 [1] 将 LCSTS 中文摘要数据集 [2] 的摘要部分翻译成英语来构建 Zh2EnSum 跨语言摘要数据集,并将 CNN/DailyMail [3] 的摘要从英文翻译成中文构建了 En2ZhSum 数据集。
Zhu 等人在翻译过程中采用了机器翻译的方式并利用了 round-trip tranlation (RTT)策略过滤掉机器翻译潜在的低质量样本。简单来说,RTT 策略先将一种语言的文本翻译至目标语言,再翻译回源语言。若回翻的源语言文本与初始源语言文本之间的词汇重叠度超过一定阈值,则保留这次翻译所构建的样本。
En2ZhSum 和 Zh2EnSum 是首次出现的两个大规模跨语言摘要数据集,目前在跨语言摘要工作中被广泛采用。为了进一步提高模型评估的可靠性,En2ZhSum 和 Zh2EnSum 还人工校准了测试集中的翻译结果。Bai 等人 [4] 延续了这一思路,通过将 Gigaword 英语摘要数据集翻译成德语构建了 En2DeSum。
以上三个跨语言摘要数据集均面向新闻题材。近几年对话摘要任务席卷了整个文本摘要领域 [5],Wang等人 [6] 将对话摘要与跨语言摘要进行了结合,并构建了首个面向对话文档的大规模跨语言摘要数据集。具体地,Wang 等人雇佣了专业的译员将 SAMSum [7] 和 MediaSum [8] 两个英文对话摘要数据集的摘要部分分别翻译成了汉语和德语(其中 MediaSum 只翻译了一部分样本),以此构建了 XSAMSum 和 XMediaSum 数据集。
下表分别从翻译方式、文档题材、数据规模、源语言以及目标语言方面统计了目前主要的合成数据集:
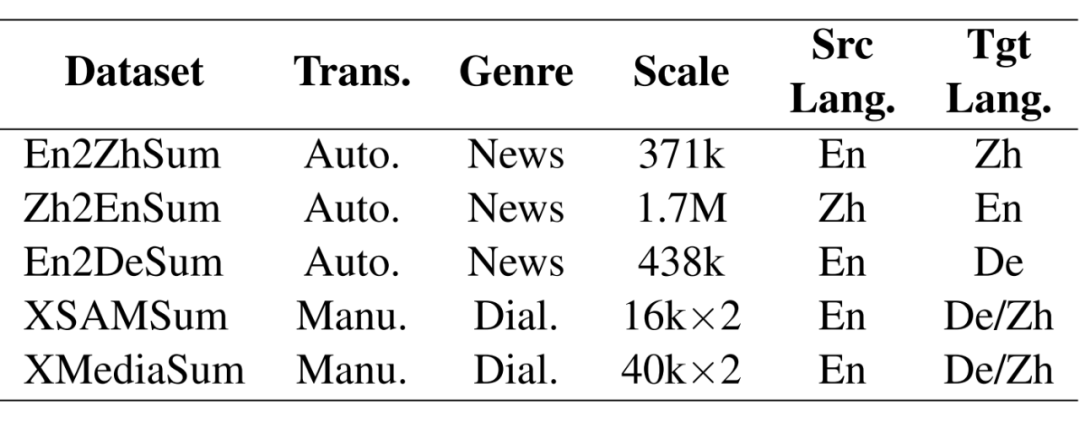
▲ Auto.: 自动翻译; Manu.: 人工翻译; Dial.: 对话文档; En: 英语; Zh: 中文; De: 德语
多语言网站数据集
随着全球化的发展,一些网站门户开始为他们的内容提供多语言版本,以此来服务全球用户。以此为背景,一些研究者选择利用这些网站上存在的平行文档(即相同的文章内容存在的不同语言版本)来构建跨语言摘要数据集。
其中最著名的工作之一是 WikiLingua 数据集 [9],该数据集通过收集 WikiHow 网站 [10] 的数据得到。WikiHow 提供了全面的操作指南文章,例如“如何培育兰花”、“如何制作玫瑰油”。该网站还征集了众多双语/多语志愿者对其文章进行翻译。翻译后的文章与原文章之间存在超链接,所以可以十分方便地从该网站上收集大量平行文档。除此之外,WikiHow 对每个文章提供了简短的摘要。据此,WikiLingua 收集了来自 18 种语言的文章与摘要,理论上可以支持 306(18*17)种不同的跨语言方向(例如中文->英文,中文->德语)。
与 WikiLingua 类似,XWikis [11] 从维基百科网站 [12] 收集了四种语言(英语、德语、法语和捷克语)的百科文本,不同语言百科词条之间也存在对应关系。对于某一个百科词条,XWikis 假设其中一个语言版本的引导段为目标摘要,而另一个语言的正文段为输入文档,这样便可收集跨语言摘要样本。除上述工作之外,CrossSum 数据集 [13] 从BBC新闻网站 [14] 收集了大量的跨语言摘要对,这得益于 BBC 所提供的全球化新闻服务。
Pipeline方法
早期对跨语言摘要的研究主要集中在 pipeline 方法,即让模型分步完成单语摘要和机器翻译。根据完成先后顺序的不同又可分为先摘要后翻译方法和先翻译后摘要方法。
先摘要后翻译方法
先摘要后翻译方法首先为源语言文档生成源语言摘要,再将摘要翻译至目标语言。Orasan 等人 [15] 先使用 MMR 算法得到源语言新闻的摘要,再通过 eTranslator 翻译服务 [16] 将摘要翻译到目标语言。Wan 等人 [17] 发现在此类方法中可能会因为翻译模型的缺陷导致最终的跨语言摘要效果欠佳,于是他们首先利用 SVM 算法预测源语言文章中每个句子的翻译质量,并将翻译质量和信息量都高的句子组成摘要,之后使用谷歌翻译将摘要翻译至目标语言。
先翻译后摘要方法
先翻译后摘要方法先将源语言文档翻译成目标语言,再通过单语摘要模型生成最终结果。Leuski 等人 [18] 首先使用了一个统计翻译模型将源语言文档翻译至目标语言,再挑选重要的句子以组成最终摘要。Wan 等人 [19] 在翻译前后的文档上分别构建图结构,并同时考虑两种图中的信息从翻译后的文档中抽取重要句子以组成摘要。Boudin 等人 [20] 也采用了类似的方法完成跨语言摘要。
Yao 等人 [21] 首先将源语言文档翻译成目标语言,接着基于翻译前后的双语特征筛选出重要的句子得到候选目标语言摘要,最后通过删除冗余或翻译质量差的短语以构建最终摘要。Zhang 等人 [22] 首先将翻译前后的文档解析成 PAS (Predicate-Argument Structures)结构,再根据双语特征将 PAS 元素融合成最终摘要。Linhares Pontes等人 [23] 利用翻译前后文档的双语特征将重要句子压缩成最终摘要。除此之外,随着 En2ZhSum 和 Zh2EnSum 大规模数据集的发布,Ouyang 等人 [24] 随后首次在 pipeline 中使用了基于 seq2seq 框架的单语摘要生成模型。
端到端方法
尽管 pipeline 方法更加直观,它仍存在着许多弊端,例如误差传播严重、依赖于外部的翻译系统、具有额外开销并且推理速度慢。为了缓解上述问题并满足现实需求,近年来的跨语言摘要研究大多集中在端到端方法,即让模型直接完成跨语言摘要任务。这也意味着模型需要同时学习摘要和翻译两种能力。为了让模型更好地完成这一任务,研究者们普遍利用相关任务(例如单语摘要或机器翻译)或额外资源(例如双语字典)辅助模型的学习。我们将现有的端到端方法分为四种不同框架:(1)多任务学习框架、(2)知识蒸馏框架、(3)资源增强框架以及(4)预训练框架。
多任务学习框架
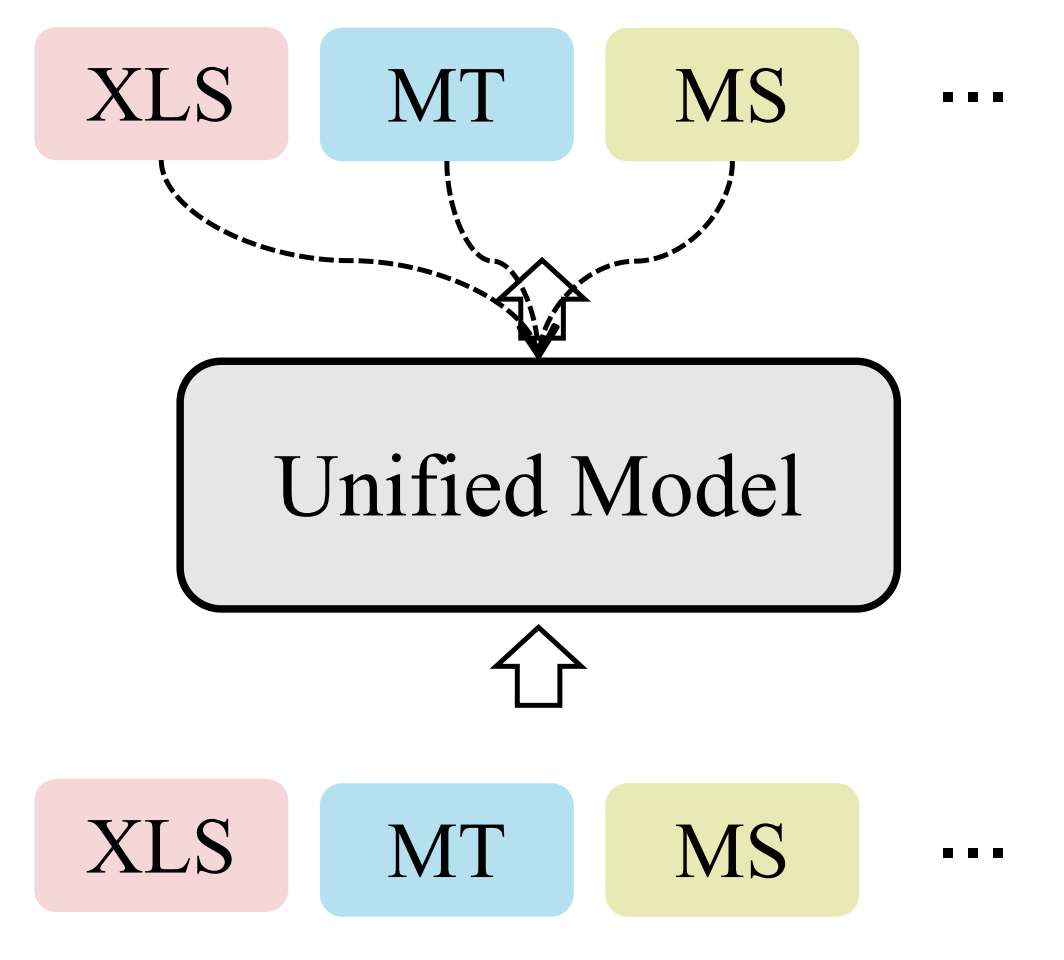
▲ XLS: 跨语言摘要; MT: 机器翻译; MS: 单语摘要。虚线代表监督信号
多任务学习框架使用相关任务来辅助跨语言摘要的训练。Zhu 等人 [1] 使用了一个共享的 transformer encoder 来编码输入文本,并使用两个独立的 transformer decoder 分别完成跨语言摘要任务和另一个相关任务(分别尝试了单语摘要和机器翻译)。Zhu 等人首次表明端到端方式的效果优于 pipeline 方式。
Cao 等人 [25] 构建了包含两个 transformer encoder 和两个 transformer decoder 的模型,其中一个 encoder 和一个 decoder 负责编码和解码源语言文本,另一个 encoder 和 decoder 负责编码和解码目标语言文本。这样,源语言的 encoder 和 decoder 可以通过源语言的单语摘要学习,目标语言 encoder 和 decoder 可以通过目标语言的单语摘要学习。此外,源语言 encoder 和目标语言 decoder 可以用于执行跨语言摘要任务。
上述两种方法在多任务之间一定程度上共享了参数,但均采用了独立的 decoder 来完成不同的任务。为了进一步提升多任务之间的共享性,Takase 等人 [26] 在一套 encoder-decoder 框架中同时训练模型完成单语摘要、机器翻译和跨语言摘要任务。
为了让模型可以区分所要执行的任务,Takase 等人在输入端加入了一个暗示任务的特殊标记。Bai 等人 [4] 认为生成跨语言摘要的先决条件是生成源语言摘要。于是他们提出让解码器先生成源语言摘要之后再紧接着生成跨语言摘要。这样,模型在生成过程中也可以隐式地学习翻译对齐能力。
Liang 等人 [27] 则选择利用变分自编码器完成跨语言摘要。具体地,他们使用三种变量来重建机器翻译、单语摘要和跨语言摘要结果。所使用的编码器和解码器在三个任务之间共享且每个任务有不同的先验网络。
知识蒸馏框架
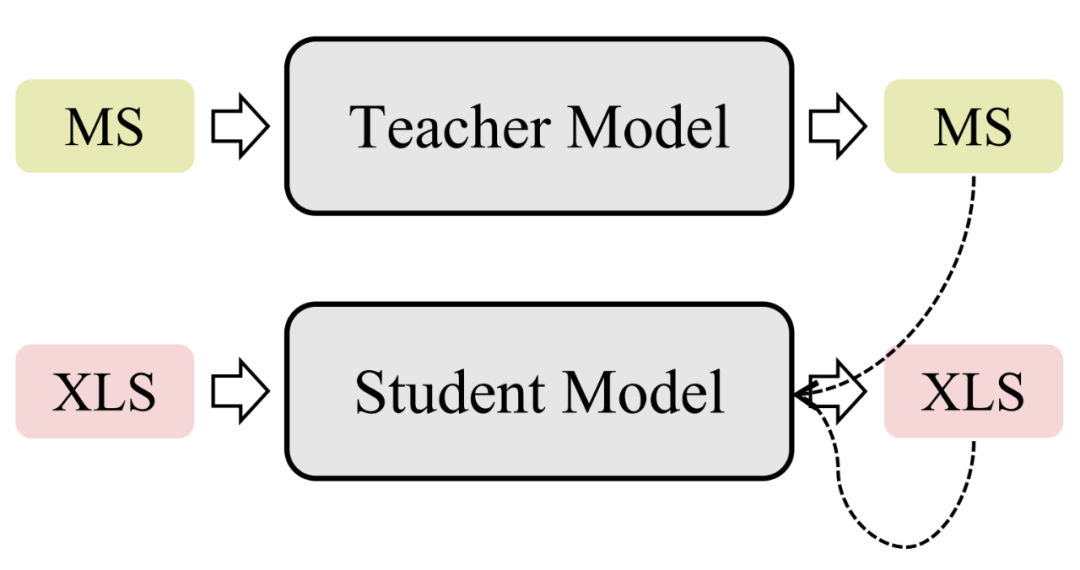
由于单语摘要/机器翻译任务和跨语言摘要任务之间密切的关系,一些研究者们尝试将单语摘要/机器翻译模型作为教师模型,并在跨语言摘要模型的训练过程中对其进行监督。Ayana 等人 [28] 使用大规模单语摘要数据集和机器翻译数据集分别训练了两个教师模型,再分别用教师模型的输出分布作为软标签监督跨语言摘要模型。Duan 等人 [29] 延续了这一思想并额外利用了教师模型和学生模型注意力权重的欧式距离来监督学生模型(即跨语言摘要模型)。类似地,Nguyen 等人 [30] 也尝试了此类方法,并基于 Sinkhorn 散度设计了一个新的变体,更好地让教师模型指导跨语言摘要模型。
资源增强框架
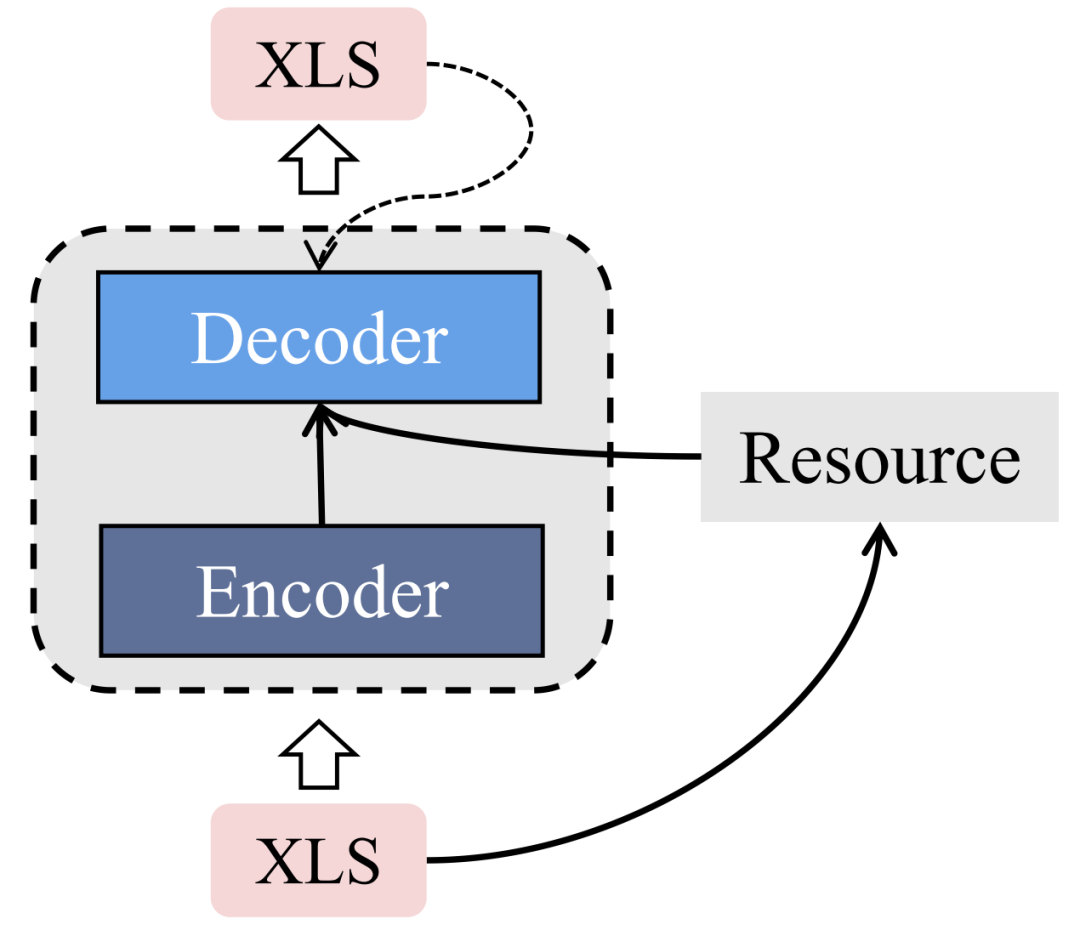
研究者们还尝试使用外部资源扩充输入文档的信息,并在生成跨语言摘要过程中同时考虑所引入的信息和源语言文档。Zhu 等人 [31] 探索了跨语言摘要中的翻译模式,他们发现目标语言摘要中相当多的一部分词汇来自源文档中词汇的翻译。于是他们使用 fast-align 工具 [32] 为源语言文档中的词汇提取翻译分布(一个源语言单词可以有多个目标语言单词对应),接着在解码摘要过程中不仅基于编码后的向量表示,还基于翻译分布。
Jiang 等人 [33] 使用 TextRank 算法从输入文档中提取关键词,并以此建立图结构。接着他们分别使用 transformer encoder 和 graph encoder 编码输入文档和所引入的图结构,最后使用改进 cross-attention 后的 transformer decoder 基于两个 encoder 的结果生成最终的跨语言摘要。
预训练框架
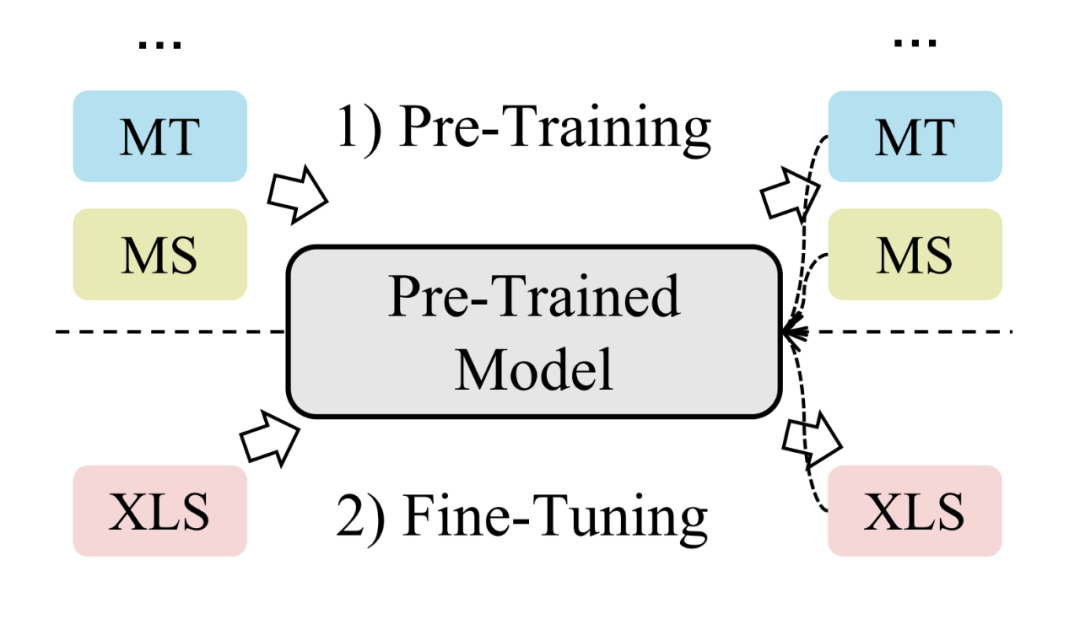
自从 BERT 出世以来,预训练的思想早已深入人心。近年来也涌现出了人们所熟知的多语言预训练模型,例如 mBART [34] 与 mT5 [35]。Liang 等人 [27] 发现简单地微调 mBART 模型就可以超越许多跨语言摘要模型的效果,这也表明了预训练语言模型的强大。然而 mBART 和 mT5 在预训练过程中仅使用了来自多种语言的单语数据进行训练(即输入输出始终为同一种语言,没有任何跨语言监督信号)。这也导致了 mBART 和 mT5 的跨语言生成能力并没有被完全探索。

▲ 常见的跨语言预训练任务
为了在预训练过程中提升模型的跨语言能力,Xu 等人 [36] 使用 MLM(掩码语言建模),DAE(降噪自编码), MS(单语摘要)以及 TSC(Translation Span Corruption)任务共同预训练模型。Dou 等人 [37] 采用 MS, MT(机器翻译)以及 XLS(跨语言摘要)三个任务来预训练模型。为了使生成出的目标语言摘要与源语言文档之间的语义更加匹配,Dou 等人还利用了强化学习的思想,将语义相似度作为奖励来指导模型。Wang 等人 [6] 在面向对话文档的跨语言摘要中提出用 MS, MT 以及 DAE 任务进一步预训练 mBART-50 模型。上述三种方法均为面向跨语言摘要任务的预训练方法。
除此之外,还有一些面向通用场景的跨语言文本生成预训练模型。Chi 等人 [38] 提出了 mT6,该模型使用 SC(Span Corruption)和 TSC 作为预训练任务,并在预训练过程中设计了 PNAT 解码策略(一种非自回归的解码方式)。类似地,Ma 等人提出了 DeltaLM 模型 [39],该模型也采用了 SC 和 TSC 预训练任务。
未来展望
为低资源语言构建数据集:目前的大规模跨语言摘要数据集仍集中在高资源语言上,虽然一些数据集包含低资源语言,但关于低资源语言的样本仍然非常稀缺。例如在 CrossSum 数据集中,一些跨语言方向上甚至只有一个样本。如何为低资源语言构建高质量且大规模的数据集,并将跨语言摘要应用于低资源语言是未来值得探索的方向之一。
可控跨语言摘要:Bai 等人 [40] 在跨语言摘要的输入中引入了信息控制率,即目标语言摘要中应包含多少源文档信息。若信息控制率达到 100%,跨语言摘要将会退化成机器翻译任务。信息控制率作为一个连续的变量将跨语言摘要和机器翻译统一了起来。除此之外,现实应用有时也会需要控制目标语言摘要中的某些属性,例如以某个实体为核心的摘要。
联合不同方向的跨语言摘要:目前绝大部分跨语言摘要工作训练出的模型仅针对单一跨语言方向,因此与该任务相关的能力无法在不同方向之间进行迁移。如何让一个模型同时处理多种语言的文本并生成多种语言的摘要仍未被充分探索。
长文档跨语言摘要:目前已有跨语言摘要工作均面向于较短文本,然而现实中存在大量的长文本,例如科技论文、商业报告、会议记录等。这些文本通常可以达到上千字,更加需要跨语言摘要的帮助来提炼核心信息。目前单语言的长文档摘要已受到了广泛的探索 [41],但在跨语言摘要中仍处于空白。
评估指标:当前跨语言摘要的自动评估指标直接借鉴于单语言摘要,然而不同于单语摘要,跨语言摘要包含了<源语言文档, 源语言摘要, 目标语言摘要>,除了 ground truth 目标语言摘要之外,如何利用其余的信息评估模型的生成结果,甚至如何设计 reference-free 的评估指标将是一个有趣的探索点。
总结
在这篇综述中,我们首次对跨语言摘要任务进行了全面的回顾。我们系统性地总结了已有的数据集工作与模型工作,并分别将模型和数据集进行分类,强调每种类别的特点以及优缺点。此外,我们还讨论了跨语言摘要未来值得研究的方向。我们希望这篇综述能够加深研究者对跨语言摘要的理解,并指导跨语言摘要未来的发展。
内容中包含的图片若涉及版权问题,请及时与我们联系删除


评论
沙发等你来抢