
推荐系统经常面临长尾问题,例如商品的分布服从幂率分布导致非常多的长尾样本只出现过很少的次数,模型在这部分样本上的效果比较差。对长尾样本增加权重,或者通过采样的方法增加长尾样本,又会影响数据分布,进而造成头部样本效果下降。针对这类问题,谷歌提出了一种可以实现头部样本知识迁移到尾部样本的迁移学习框架,使推荐系统中长尾预测问题效果得到显著提升,并且头部的预测效果也没有受到损失,实现了头部尾部双赢。

文中提出的迁移学习框架主要包括model-level transfer和item-level transfer。其中model-level transfer通过学习一个多样本模型和一个少样本模型,并学习一个二者参数的映射函数,实现模型参数上的迁移;item-level transfer通过对模型训练流程的优化,让映射函数同时能够学到头部item和尾部item之间的特征联系。
1
Model-level Transfer
Model-level Transfer的核心思路是学习many-shot model和few-shot model的参数映射关系,这个思路最早来源于2017年NIPS上的一篇文章Learning to Model the Tail(NIPS 2017)。比如下面的例子中,living room是头部实体,可以利用living room结合不同的样本量,学到模型参数是如何从one-shot(theta1)变换到two-shot(theta2)一直到many-shot(theta*)。那么对于一个tail实体library,模型只能通过few-shot学到一个模型参数,但是可以利用在many-shot上学到的参数变化经验推导出library上的参数变化。通过不断增加数据,模型参数发生变化,模型学习的是数据增强的过程如何影响了模型参数变化。
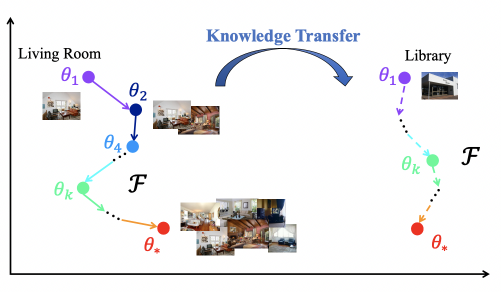
在推荐系统中也是同理,给定一个item和user的反馈信息,模型隐式的学习如何增加更多user的反馈信息帮助这个item的学习,也就是从少数据到多数据的模型参数变化过程。
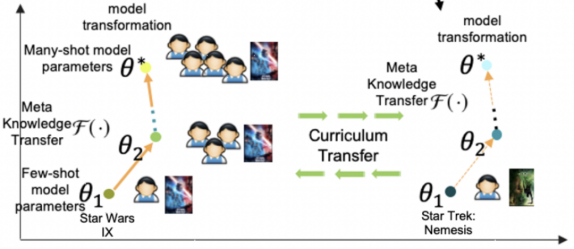
基于上述思路,本文通过一个meta-learner学习这种参数随着shot增加的映射关系。首先构造两种类型的数据集,第一种数据是利用头部商品构造的many-shot训练数据,用来训练一个base-learner;第二种数据是在头部数据中进行下采样,模拟得到的few-shot训练数据。Meta-learner是一个函数,输入few-shot模型的参数,预测出many-shot模型的参数,即学习这个映射关系,损失函数如下,第一项是预测many-shot参数的损失,第二项是在few-shot数据上模型的预测效果:
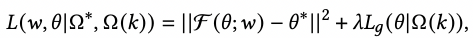
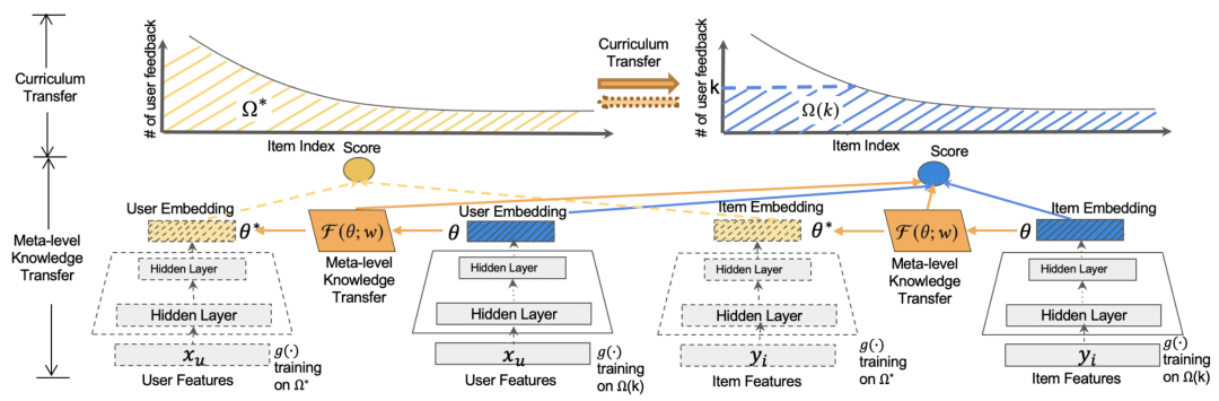
其中,本文主要优化的部分是base-learner在user和item网络中的最后一层参数,因为如果学习全局参数的映射关系,计算复杂度太高。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢