


论文地址:https://arxiv.org/pdf/2203.06967.pdf
开源地址:https://github.com/demonsjin/Blind2Unblind
摘要
大规模清洁的真实清洁对是昂贵且难以获得的。同时,在实践中,接受过合成数据培训的监督Denoiser效果不佳。自我监督的Denoisers仅从单个嘈杂的图像中学习,可以解决数据收集问题。但是,在输入或网络设计期间,自我监管的denoising方法,尤其是盲点驱动的方法,遭受了相当大的信息丢失。缺乏有价值的信息大大降低了降低降低性能的上限。在本文中,我们提出了一种简单而有效的方法,称为Blind2unblind,以克服盲点驱动的denoising方法中的信息丢失。首先,我们介绍了一个全球意识的面具映射者,该映射器能够实现全球感知并加速培训。蒙版映射器样本在盲点上的所有像素上的所有像素都在剥落的体积上并将其映射到同一通道,从而使损耗函数能够一次优化所有盲点。其次,我们提出了可重新可见的损失,以训练Denoising网络并使盲点可见。 DeNoiser可以直接从原始噪声图像中学习,而不会丢失信息或被困在身份映射中。我们还理论上分析了可见损失的收敛性。与以前的工作相比,关于合成和现实世界数据集的广泛实验证明了我们方法的出色表现。
主要贡献
我们工作的贡献如下:
- 我们提出了一个新颖的自我监督的denoising框架,使盲点可见,没有子样本,噪声模型先验和身份映射。
- 我们提供了可重新可见损失的理论分析,并在收敛上呈现其上限和下限。
- 与最先进的方法相比,我们的方法显示出卓越的性能,尤其是在具有复杂噪声模式的现实数据集上。
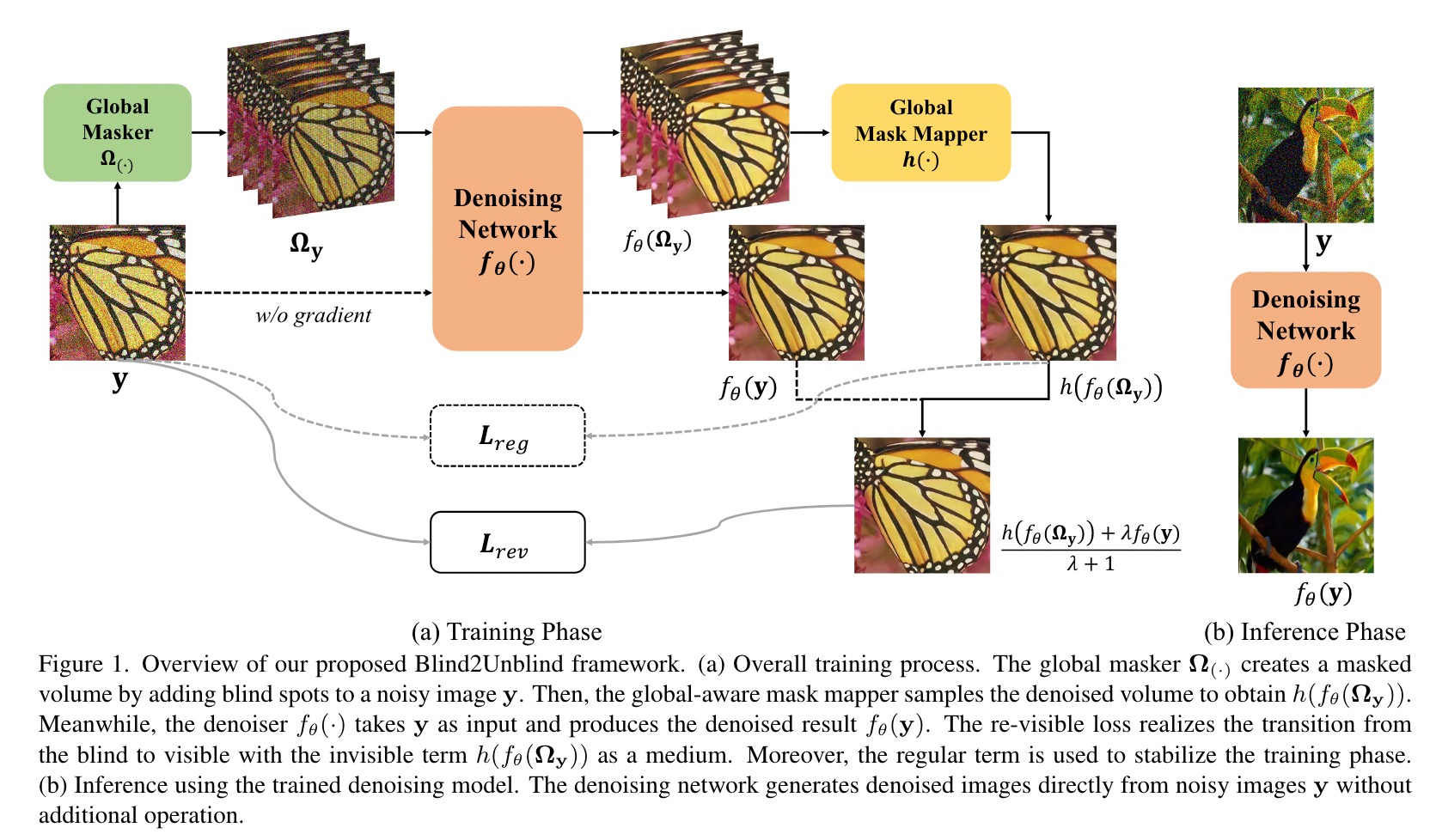
实验
在合成的denoising中,我们使用[20]为N2C,N2N和Laine19提供的预训练模型,保留了与[15,20]相同的网络架构。此外,我们使用BM3D的多通道版本CBM3D [8]来执行高斯denoising与[7]估计的参数σ相结合。对于Poisson噪声,Anscombe [23]首次运行将泊松噪声转换为高斯分布,然后将BM3D用于降级。对于Self2self,N2V,Noisier2Noise,DBSN,R2R和NBR2NBR,我们使用官方配置。
对于在RAW-RGB空间中进行现实世界的DENOSIS,所有方法都使用其官方实现,并已在SIDD Medium数据集中进行了重新培训。请注意,我们根据拜耳模式将单渠道原始图像分为四个子图像。对于BM3D,我们将四个子映射分别降低,然后将Deno的子图像整合到整个图像中。对于深度学习方法,我们堆叠了四个子图像,以形成一个四通道图像,以进行降解,然后将其集成到RAW-RGB空间中。对于在FM上进行现实世界的denoing,我们使用官方实施进行了对所有方法进行比较。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢