
论文标题:Lightweight Attentional Feature Fusion: A New Baseline for Text-to-Video Retrieval
论文地址:https://arxiv.org/abs/2112.01832
代码地址:https://github.com/ruc-aimc-lab/laff
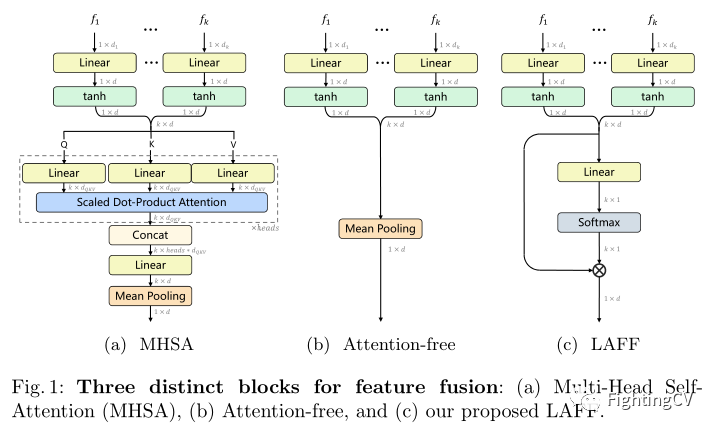
作者在本文中提出了一个非常简化的特征融合块,称为轻量级注意力特征融合(LAFF),见图(c)。LAFF 是通用的,适用于视频和文本端。视频/文本特征用凸方式组合在一个特定的 LAFF 块中,学习组合权重以优化跨模态文本到视频的匹配。在特征层面进行融合,LAFF因此可以被视为一种早期的融合方法。同时,通过 MHSA 中使用的多头技巧,可以在单个网络中部署多个 LAFF,并以后期融合的方式组合它们的相似性。在早期和后期以及视频和文本结束时执行特征融合的能力使 LAFF 成为利用文本到视频检索的多样化、多层次(现成的)特征的强大方法。总之,本文的主要贡献如下:
-
本文是第一个研究用于文本到视频检索的视频端和文本端特征融合的工作。鉴于用于特征提取的深度视觉/语言模型的可用性越来越高,本文提出了一种有效的方法来利用这些黑暗知识来解决任务。
-
作者提出了 LAFF,一种轻量级的特征融合块,能够在早期和晚期进行融合。与 MHSA 相比,LAFF 更紧凑但更有效。它的注意力权重也可用于选择较少的特征,而检索性能大部分保持不变。
-
在 MSR-VTT、MSVD、TGIF、V ATEX 和 TRECVID A VS 2016-2020 五个基准上的实验表明,基于 LAFF 的视频检索模型(上图 )与最先进的模型相比具有优势,为文本到视频的检索提供了强大的基线。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢