

论文地址:https://arxiv.org/pdf/2012.04631.pdf
开源代码:https://github.com/cvlab-columbia/globetrotter
项目地址:https://globetrotter.cs.columbia.edu/
摘要
一次的机器翻译是高度挑战性的,因为对地面真理进行培训需要所有语言对之间的监督,这很难获得。我们的主要见解是,尽管语言可能会发生巨大变化,但世界的基本视觉外观仍然一致。我们介绍了一种使用视觉观察来弥合语言之间的差距,而不是依靠表示表示形式的拓扑特性。我们训练一个模型,该模型将不同语言的文本段对齐时,并且仅当与它们关联的图像相似并且每个图像依次与其文本描述相称。我们从Scratch上训练模型,其中包括五十多种语言的新文本数据集,并带有随附的图像。实验表明,我们的方法在使用检索上胜过无监督的单词和句子翻译的先前工作。

主要贡献
我们的贡献是三倍的。 首先,我们提出了一种利用语言和视觉之间的跨模态对齐来训练多语言翻译系统的方法,而无需任何并行语料库。 其次,我们证明我们的方法在句子和单词翻译方面都大大优于以前的工作,我们使用检索来测试翻译。 最后,为了评估和分析我们的方法,我们发布了一个涵盖 52 种不同语言的联合多模式数据集。 总的来说,我们的工作表明,视觉中的基础语言产生的模型在语言之间显着更加健壮,即使在基础事实平行语料库不可用的情况下也是如此。 代码、数据和预训练模型将被发布。
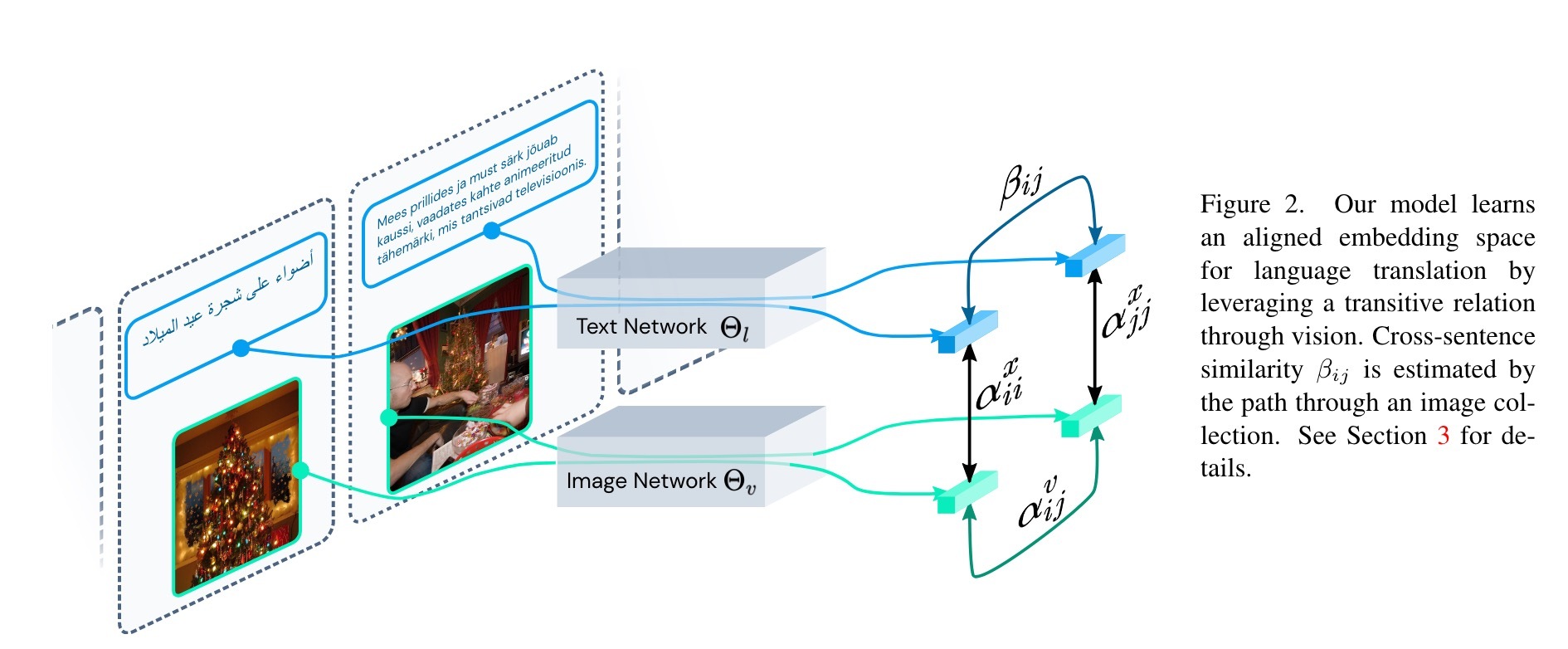
实验
为了训练和评估我们的方法,我们收集了跨越52种不同语言的图像和标题的联合图像和标题。语言的完整列表在附录B.4中。我们将三个字幕数据集组合在一起,并使用来自Amazon Web服务的Amazon Translate翻译它们。我们使用FlickR30K [55],MSCOCO [37]的字幕和图像和概念字幕[47]数据集。联合数据集中的语言是多种多样的,涵盖了人类注释者的标题和网络收获的字幕。我们在图4中显示了一些示例。数据集包含410万个图像映射对,英文句子的平均长度为10.4个单词。我们将公开发布此数据集。
我们将数据集分为火车,验证和测试集。我们进行分区,以确保它们每个都包含一组不相交的图像和句子。我们使用315万个唯一的文本图像对进行培训,验证787K和78.7K进行测试。培训和验证拆分包含与所有语言相对应的样本,每个图像仅具有与之相关的一种语言。测试集被转化为所有语言(相同的样本),以获取地面真相一致以进行评估。我们进一步收集了由Fluent Speaker翻译成11种不同语言的200英文字幕的测试集(请参阅附录B.4),总共有2200种人类生成的翻译。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢