

论文地址:https://arxiv.org/pdf/2203.10821.pdf
开源地址:https://github.com/donydchen/sem2nerf
摘要
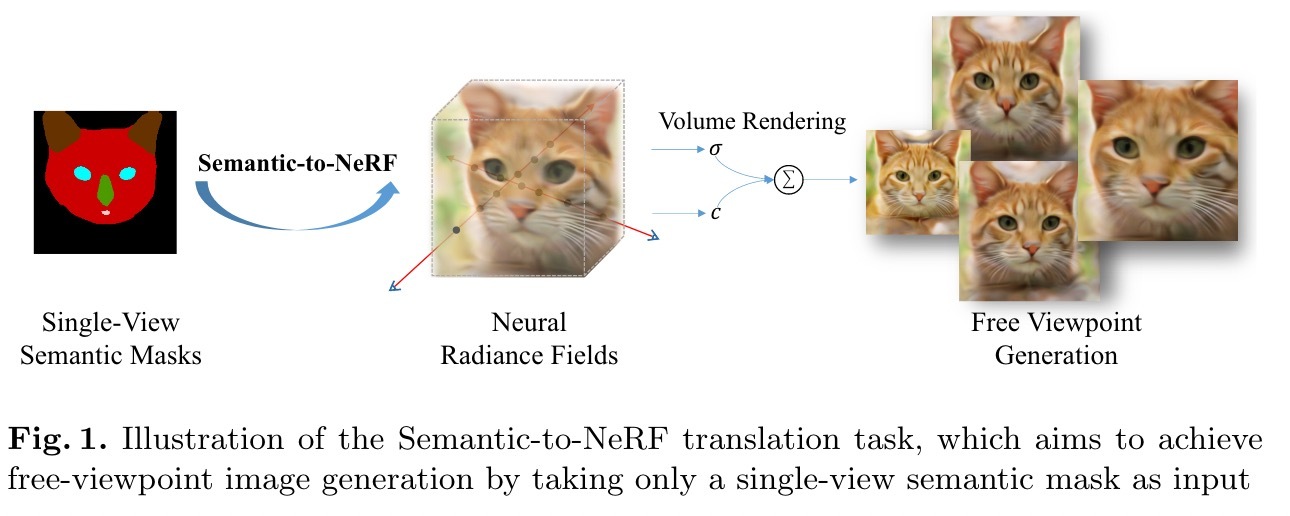
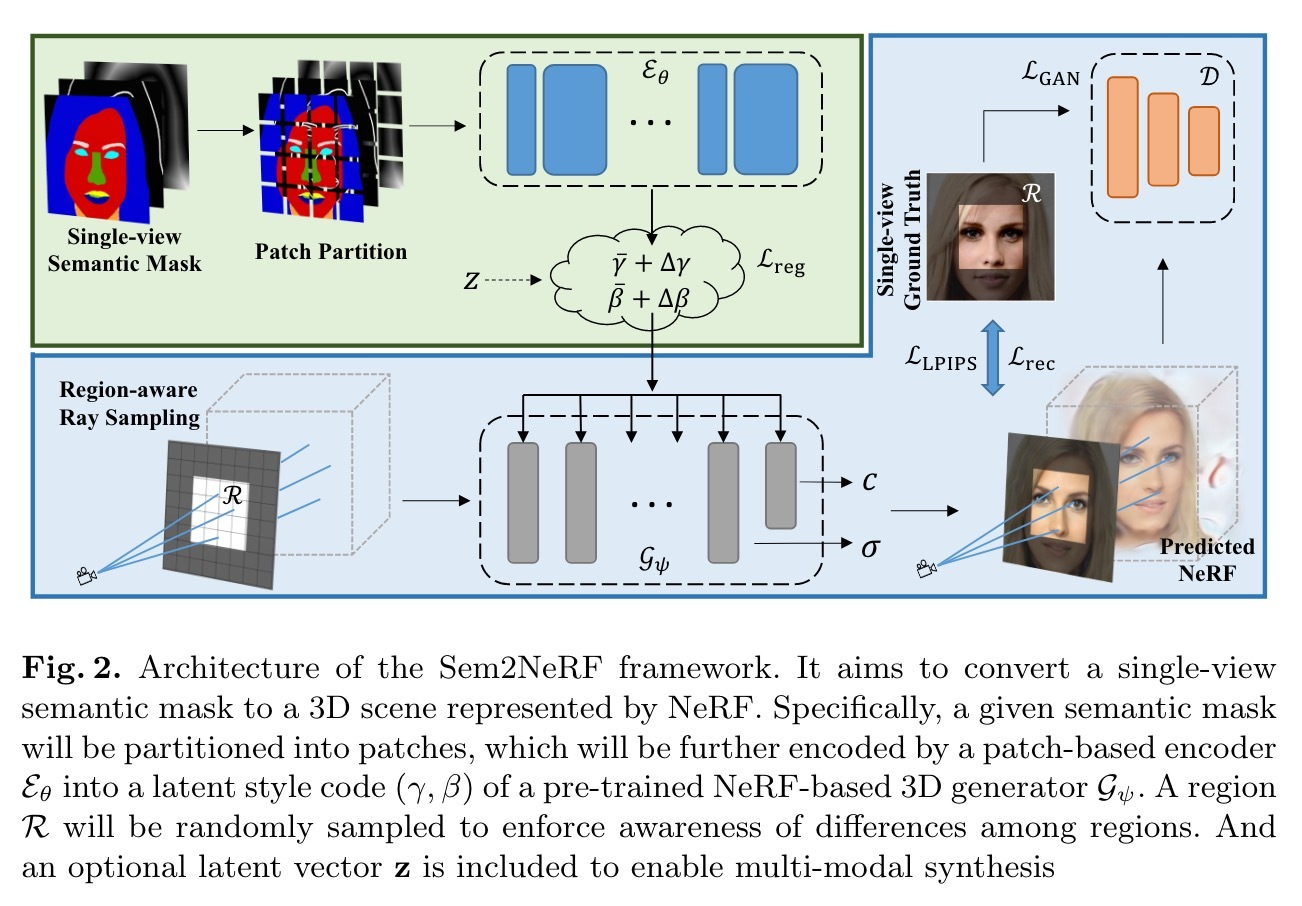
图像翻译和操纵随着深层生成模型的快速发展而引起了越来越多的关注。尽管现有的方法带来了令人印象深刻的结果,但它们主要在2D空间中运行。鉴于基于Nerfbb的3D感知生成模型的最新进展,我们介绍了一项新任务,Smanticto-nerf翻译,旨在重建由NERF模型的3D场景,以一个单视语义掩码作为输入为条件。为了启动这项新颖的任务,我们提出了SEM2NERF框架。特别是,SEM2NERF通过将语义面膜编码到控制预训练的解码器的3D场景表示形式中来解决高度挑战的任务。为了进一步提高映射的准确性,我们将新的区域感知学习策略集成到编码器和解码器的设计中。我们验证了提出的SEM2NERF的功效,并证明它在两个基准数据集上的表现优于几个强基础。
主要贡献
我们的贡献是三个方面:
- 我们介绍了一项新颖而富有挑战性的任务,语义到网络翻译,该翻译将单视2D语义掩码转换为由神经辐射场模仿的3D场景。
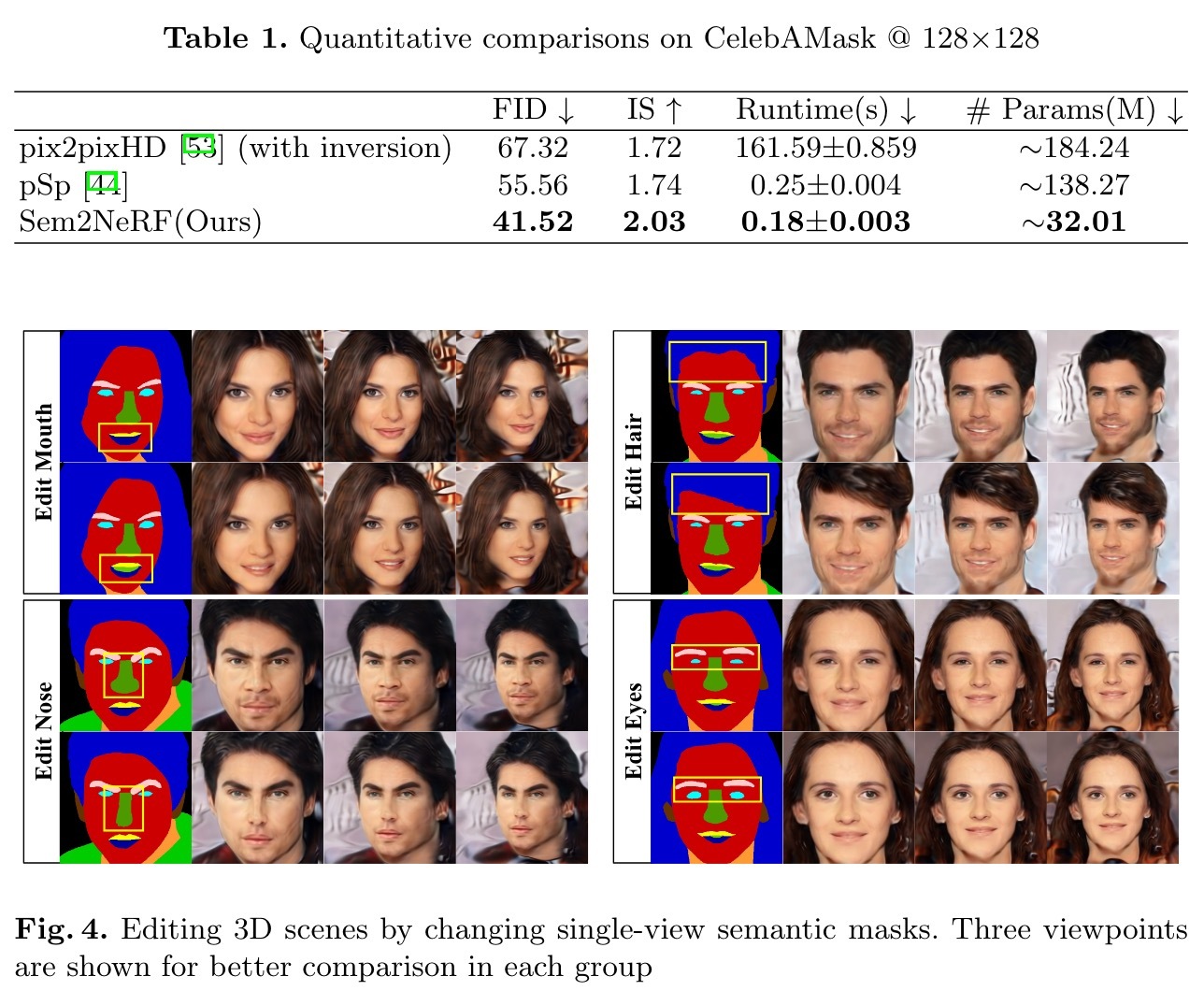
- 借助需要区域感知的学习策略的见解,我们提出了一个新颖的框架SEM2NERF,该框架能够实现3D一致的自由观点图像产生,语义编辑和多模型综合,仅作为输入来实现一个单一观看特定类别的语义面具,例如人脸,猫的脸。
- 我们通过广泛的消融研究来验证我们对我们的地区感知学习策略和SEM2NERF功效的见解,并证明SEM2NERF在两个具有挑战性的数据集上表现优于强大的基线。
实验
为了实现语义到网络翻译,我们假设训练数据具有单视图注册的语义掩码和图像,并带有相应的查看说明。在我们的实验中,使用了两个数据集进行评估。 Celebamask-HQ [27]包含Celeba-HQ [34,23]的图像,手动标记的19级语义面具和头姿势。我们将对称零件(即眼睛,眉毛和耳朵)的左旋标签合并为每个部分的标签。该数据集被随机分配为带有28,000个样品的培训集,并带有2,000个样本的测试集。使用π-gan和datasetgan [65]构建CATMASK,以进一步证明语义到-NERF任务和SEM2NERF的潜力。技术细节在A.2节中详细阐述。

内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢