

论文地址:https://arxiv.org/pdf/2207.12978.pdf
摘要
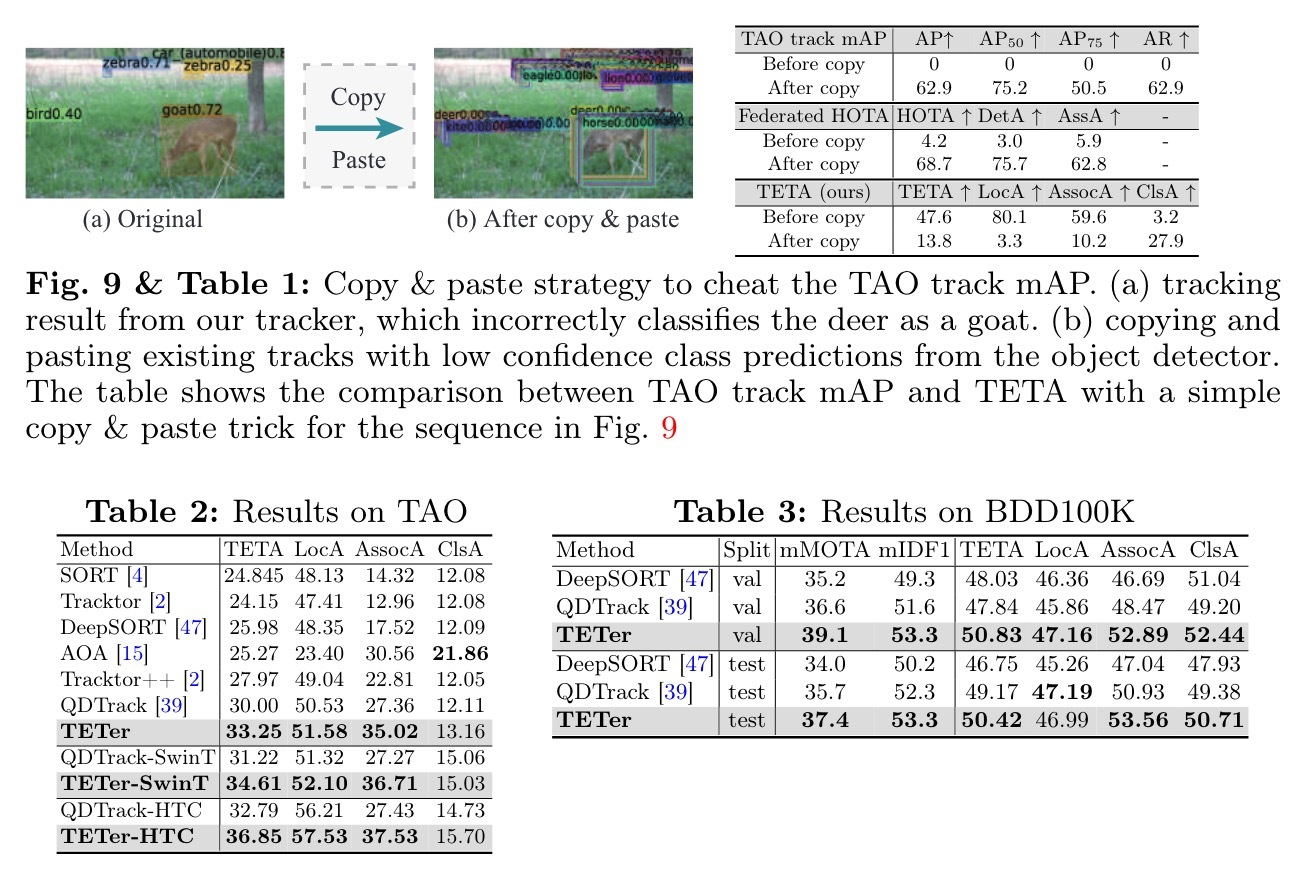
当前的多类别多对象跟踪(MOT)指标使用类标签对跟踪结果进行分组,以实现对每个类的评估。类似地,MOT方法通常只将对象与相同的类预测相关联。这两种在MOT中流行的策略隐含地假设了分类性能接近完美。然而,在最近的大规模MOT数据集中,情况远非如此,这些数据集包含大量具有许多稀有或语义相似类别的类。因此,由此产生的不准确分类导致次优跟踪和跟踪器基准不足。我们通过将分类与跟踪分离来解决这些问题。我们引入了一个新的度量指标--跟踪每件事的精确度(TETA),将跟踪度量分解为三个子因素:定位、关联和分类,即使在分类不准确的情况下,也允许对跟踪性能进行全面的基准测试。TETA还解决了大规模跟踪数据集中具有挑战性的不完全标注问题。我们进一步引入了一个Track Every Things tracker(TETer),该Track Every Things tracker使用类样本匹配(CEM)执行关联。我们的实验表明,TETA对跟踪器的评估更加全面,TETer在具有挑战性的大规模数据集BDD100K和STAO上取得了显著的改进。

主要贡献
我们的TETer遵循每件事都有关联(AET)的策略。我们不是将同一类中的对象关联起来,而是将相邻帧中的每个对象关联起来。AET策略将关联从大规模长尾环境下具有挑战性的分类/检测问题中解放出来。然而,尽管在关联过程中完全不考虑类信息,我们提出了一种新的利用类信息的方法,该方法对分类错误具有鲁棒性。我们引入了类样本匹配(CEM),其中学习到的类样本以一种软的方式结合了有价值的类信息。这样,我们在不依赖于通常不正确的分类输出的同时,有效地利用了对大规模检测数据集的语义监督。CEM可以无缝地集成到现有的MOT方法中,并持续地提高性能。此外,我们的跟踪策略使我们能够利用丰富的时间信息修正每帧类预测。
我们在新引入的大规模多类别跟踪数据集TAO[8]和BDD100K[50]上分析了我们的方法。我们的综合分析表明,我们的度量更全面地评价跟踪器,并实现了更好的交叉数据集一致性,尽管注释不完全。此外,我们的跟踪器在TAO和BDD100K上实现了最先进的性能,无论是使用以前建立的度量还是建议的TETA。

实验
我们对不同的评价指标进行了分析,并在TAO[8]和BDD100K[50]上研究了我们新的跟踪方法的有效性。TAO为常见和稀有对象提供视频和跟踪标签,有超过800个对象类别。尽管BDD100K用于驾驶场景的标记类别较少,但一些类别,如火车,比汽车等常见对象要少得多。在本节中,我们首先将不同的度量与TETA进行比较。然后,我们在不同的数据集上对所提出的TETer进行评估,并将CEM插入到现有的跟踪方法中,以证明其可推广性。
对于目标检测器,我们使用速度更快的R-CNN[41]和特征金字塔网络(FPN)[24]。我们在TAO上使用ResNet-101作为主干,与TAO基线相同[8],在BDD100K上使用ResNet-50作为backone,与QDTrack相同[39]。在TAO上,我们使用重复因子抽样,在LVISV0.5[17]和COCO数据集的组合上训练我们的模型。重复系数设置为0.001。我们使用学习速率为0.02的SGD优化器,并采用学习速率衰减的步长策略,动量衰减为0.9,权值衰减为0.0001。我们对我们的模型进行了总共24个历元的训练,在16和22个历元时,学习速率下降。对于具有SwinT骨干[28]的TETer,我们使用mmdetection使用的3x调度[6]。对于TETer-HTC,我们使用[23]中的HTCX101-MS-DCN检测器。在BDD100K上,我们从QDTrack[39]加载相同的对象检测器权重,并在冻结其他权重的情况下,用BDD100K检测数据集微调样本编码器。对于每个图像,我们最多采样256个对象建议。有关更多详情,请参阅附录第8.6节。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢