
DeepMind又对Atari游戏下手了,这回秒的是自己,把两年前的大杀四方的Atari 57模型提速了200倍!
构建在各种任务中表现良好的「通用智能体」,一开始就是强化学习的重要目标。这个问题一直是大量工作的研究对象,其性能评估经常通过观察Atari 57基准中包含的各种环境的分数来衡量。

Agent57是DeepMind在2020年搞的一个Atari游戏智能体,史上首次在所有57个游戏中超过了人类基准表现,但这是以数据效率为代价的,需要近800亿帧的经验训练才能实现。
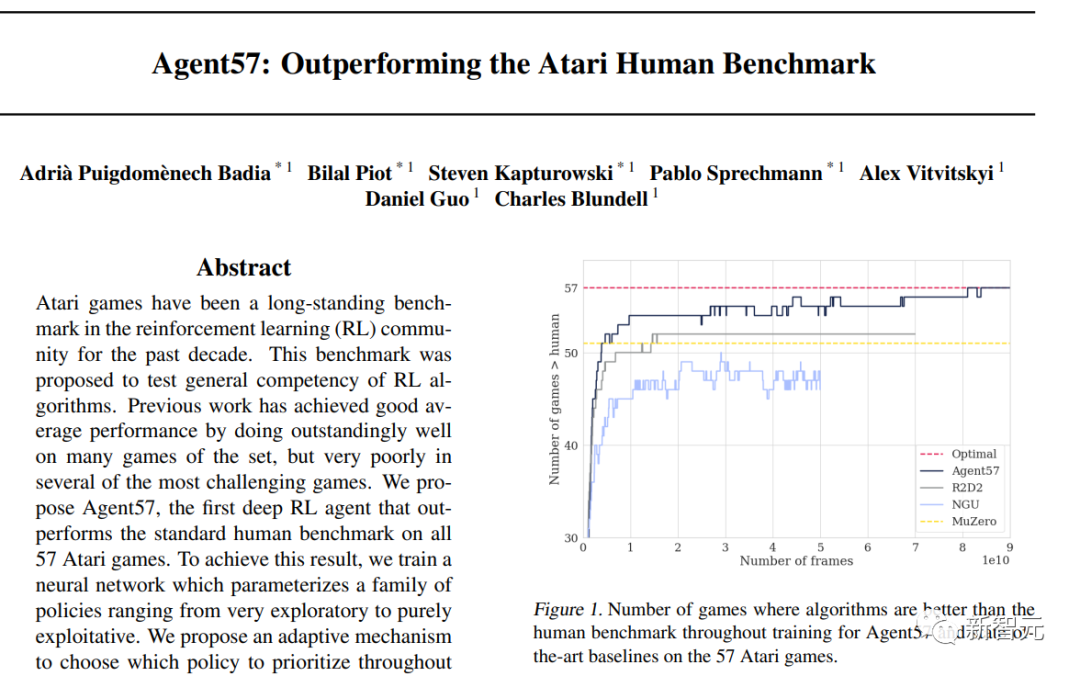
两年过去,DeepMind觉得这个智能体有「亿点点」慢了,不如以它为基础,提提速,降一降训练量,效果还不下降?
于是DeepMind的一篇新论文,带来了一个新的智能体:MEME,所需的训练经验更少,从而实现为原来的Agent57「提速200倍」的小目标。

以Agent57为起点,DeepMind采用了一系列不同的策略,以实现超越人类基准所需经验的200倍减少。我们调查了在减少数据制度时遇到的一系列不稳定因素和瓶颈,并提出了有效的解决方案,以建立一个更加强大和高效的智能体。
研究人员表示,这个新方法的四个关键部分是:
(1)一种近似的信任区域方法,它能够从在线网络中稳定地引导。
(2) 实行损失和优先权的归一化方案,在学习一组具有广泛规模的价值函数时提高了鲁棒性。
(3) 提出一个改进结构,采用NFNets的技术利用更深的网络,不需要规范化层
(4) 一种政策提炼方法,用于平滑瞬时贪婪政策的超时。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢