

论文链接:
https://arxiv.org/pdf/2207.12819.pdf
代码链接:
https://github.com/iamwangyabin/S-Prompts (暂未开放,敬请期待)
导读
本文是对NeurIPS 2022被接收的文章“S-Prompts Learning with Pre-trained Transformers: An Occam’s Razor for Domain Incremental Learning”的介绍。在该工作中作者提出一个针对域增量学习的简单高效的方法(S-Prompts)。作者设计Prompts训练策略对每个域的知识进行独立学习,从而将预训练模型增量地迁移学习不同域。所提出的方法可以让新旧知识互不干扰,并达到双赢的结果。
贡献
增量学习(连续学习)目标是在数据流中增量地训练一个机器学习模型,使得模型能够在获得新知识的同时不遗忘已经学习到的旧知识。灾难性遗忘(catastrophic forgetting)现象是增量学习的最大挑战之一,也就是模型在学习新知识的同时旧知识会出现严重的遗忘,从而导致模型在旧任务上性能下降。早期工作通过存储少量旧数据或者设计正则损失函数来维持模型在旧任务上的精度,然而这不可避免地限制了在新任务上的学习能力,如图1。因此大多数增量方法最后会陷入新旧任务之间的拔河游戏(零和游戏)–一方获得精度的同时会让另一方损失精度。这个挑战在域增量(Domain-incremental learning)问题上尤为明显,不同域的知识可能很难在同一个空间中共存。此外保存旧任务的数据会占用大量存储空间,并且有隐私问题和新旧数据量不平衡的问题。因此本工作从实际应用需求出发,聚焦在无存储样本的域增量学习任务。
在本工作中,作者打破成规提出一个双赢策略来解决域增量问题,通过学习跨域独立的Prompts使得模型在每个域都得到最佳性能而没有任何相互干扰,并将学习到的Prompts存储来消除灾难性遗忘问题。所提出的新的增量模式仅仅为每个任务增加微不足道的参数(Prompts)学习当前域的知识,而预训练网络的其余部分都是冻结固定的,因此非常简单且有效。为了在推理阶段选择合适的Prompts,每个阶段的训练数据特征都会用K-Means计算得到域中心作为这个域的表示。在推理时,对于一个样本,作者先提取这个样本在预训练模型(ViT)的特征,再将这个特征用K-NN找存储的最近域中心作为挑选Prompts的依据。假设有S个阶段(Session),作者最终会独立地学习S个域的Prompts,因此本方法命名为S-Prompts。
此外为更好的学习不同域的Prompts,作者提出全新的针对视觉预训练模型的Prompts学习方法(S-iPrompts)以及针对视觉-语言预训练模型的Prompts学习方法(S-liPrompts)。本方法在三个标准DIL基准数据集上取得了较高的成绩,S-Prompts明显优于最新的无样本增量方法(平均精度相对提高30%),甚至对于使用样本的方法也高出6%精度。S-Prompts仅仅有极微小的参数增加,例如,在S-liPrompts中每个域增加0.03%参数量。
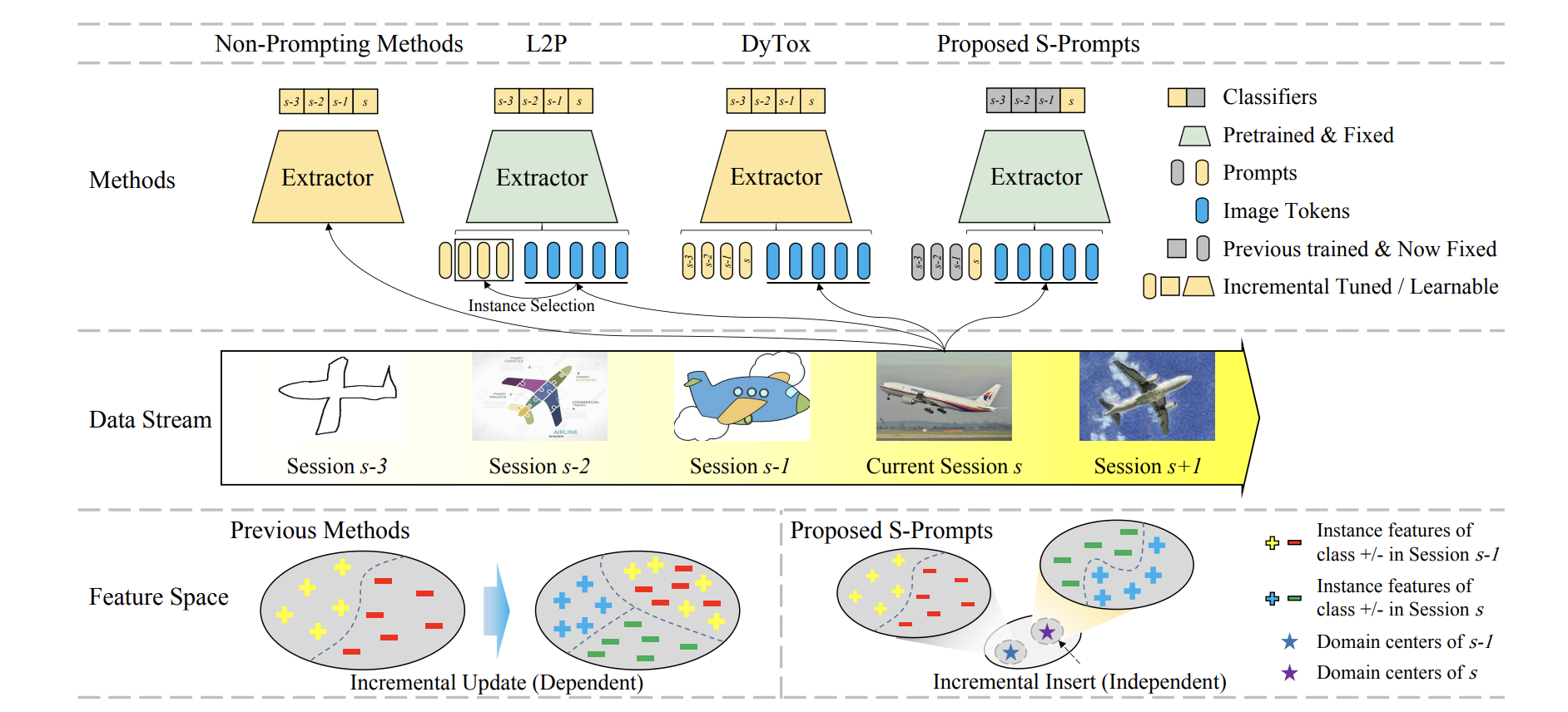
图1 现有工作和本工作区别
方法
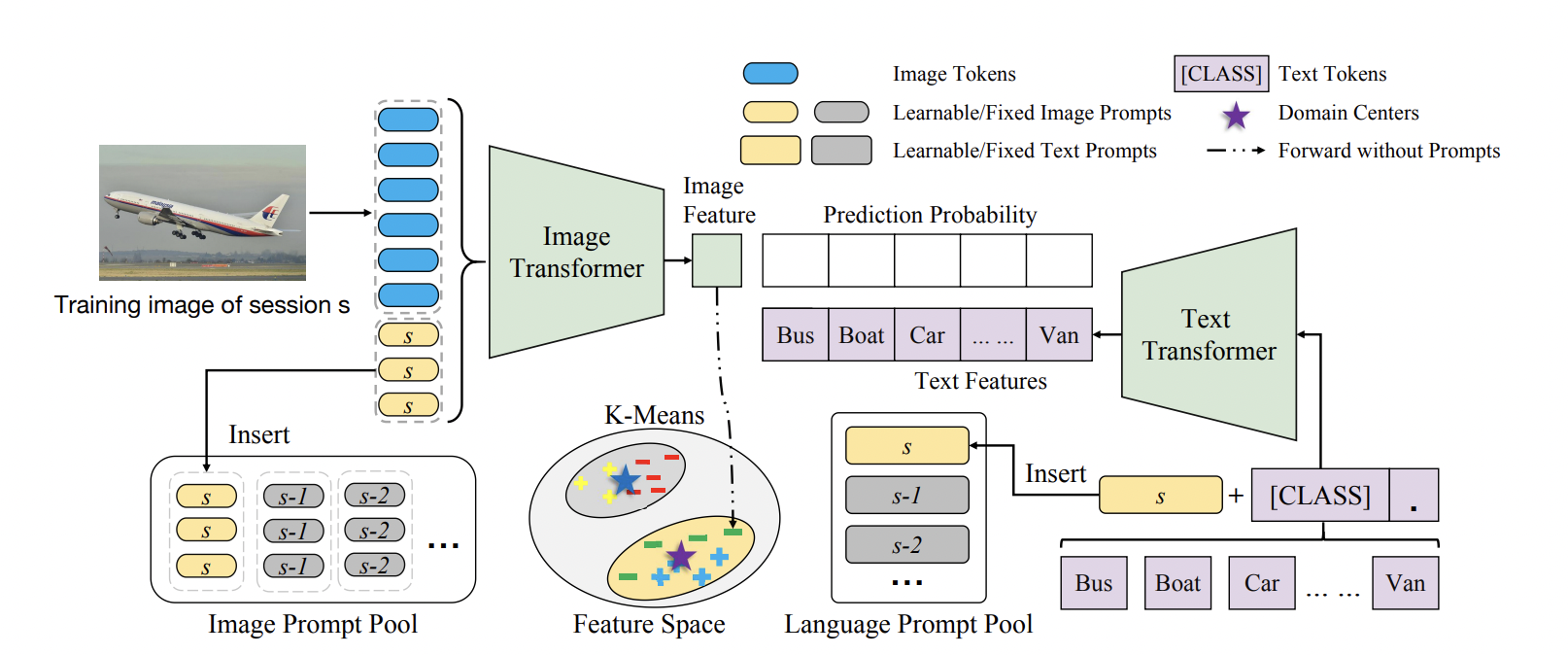
图2 S-liPrompts结构
1 S-Prompts框架简述
S-Prompts的核心思想是借助预训练模型,对每个域逐个学习Prompts。在增量训练时,预训练模型始终是固定的,通过训练Prompts可以将预训练模型调整迁移到不同的域中。在这样设定下,不同的域的知识被编码进仅有少量参数的Prompts中,这样不仅避免了存储旧样本,同时可以极大地减少灾难性遗忘。
然而这种设计在推理时需要对给定的样本挑选合适的Prompts。由于作者已经有了预训练模型,那么预训练模型本身可以帮助选择合适的Prompts。具体而言,如图2所示,作者应用K-Means来得到每个域的训练数据的特征中心,这些特征是直接使用预训练模型提取的,并没有应用Prompts。在推理时,作者直接使用K-NN来查询应该使用哪个域的Prompts。由于域增量任务的特征往往差别很大,这种简单的做法可以在DIL中获得良好的性能。
2 图像Prompts(S-iPrompts)学习策略
在S-iPrompts的方法中,对于一个域S,作者使用一组独立的连续可学习参数(即Prompts) \( P^i_s \in \mathbb{R}^{L_{i} \times D_i} \)P作为预训练ViT的输入的一部分,其中\( L_i \in \mathbb{R} \)和 \( D_i \in \mathbb{R} \)分别是Prompts长度和维度。
如图2所示,给定域 ss 的图片 xx ,ViT的输入为 \( x = [x_{img}, P^i_s ,x_{cls}] \),其中 ximg 是图片tokens, xcls 是预训练模型ViT的class tokens。当在新的域 s+1上增量训练时,会添加一组新的独立的Prompts \( P^i_{s+1} \) 。因此,按顺序学习所有域会产生一个域的Prompt Pool。Prompt Pool可以定义为 \( \mathcal{P}^i =\left \{ P^i_1, P^i_2, ...,P^i_S \right \} \)。
对于Classifier,每个session都会学习单独分类器并且存储下来,在推理时挑选对应的classifier。对于ViT,分类器就是全链接层,表示为\( \left [ W_s, b_s \right ] \) , 其中 \( W_s \in {R}^{C \times D_i}Ws∈RC×Di, b_s \in \mathbb{R}^{C} \)分别是特征维度和总共的类别数量。
每个增量阶段都有独立的分类器,因此作者也有一个分类器池 \( \mathcal{P}^{fc} =\left \{ \left [ W_1, b_1 \right ] , \left [ W_2, b_2 \right ], ...,\left [ W_S, b_S \right ] \right \} \) 。
3 语言-图像Prompts(S-liPrompts)学习策略
S-liPrompts是为了能够将现在很多的视觉-语言预训练模型,例如CLIP,更好地增量迁移到下游任务上。对于阶段ss,作者使用 MM 个可学习的向量 vv 作为语言端的prompts \( P^l_s=\left \{v_1, v_2, ..., v_M \right \} \in \mathbb{R} ^{L_{l} \times D_l} \),其中Ll,Dl 分别是Prompts的长度和维度。
对于第 j个类, 语言编码器(text encoder)的全部输入为 \( t_j = \left \{P^l_s, c_j\right \} \) , 其中 cj 是第 j个类的类别名称编码。
语言Prompts同样和各自的域相关联,在训练完所有增量阶段后,可以同样得到一个Prompt Pool存放所有的语言Prompts,如 \( \mathcal{P}^l = \left \{ P^l_1, P^l_2, ..., P^l_S \right \} \)。
CLIP的语言编码器 gg 以上文定义的tj 作为输入并且输出一个向量表示作为某个类的特征。
令 f(x)f(x) 为视觉编码器 f 提取的图片 x 的特征, \( \left \{ g(t_j) \right \}^C_j \) 是使用文字编码器 g(.)提取的类别 j 的特征,CLIP分类器使用如下公式计算预测概率。
\( p(y_j|x)=\frac{\exp (\left \langle f(x),g(t_j) \right \rangle )}{ {\textstyle \sum_{k=1}^{C}}\exp (\left \langle f(x),g(t_k) \right \rangle) } \)
实验
在实验设置上,本工作选择了三个在DIL任务上有代表性的大型评测基准:CDDB,CORE50和DomainNet。所有方法均使用相同预训练ViT-B/16或者同性能的Backbone(针对DyTox使用的是预训练ConViT)。
表1、2和3结果展示了所提出的S-iPrompts和S-liPrompts极大程度地超越了已有的其他无样本增量方法。甚至S-liPrompts得到了相对30%的精度提升。此外相对于存样本的方法,所提出的S-Prompts在不存样本的情况下也取得了6%左右的精度提升。

表1 CDDB数据集结果

表2 CORE50数据集结果
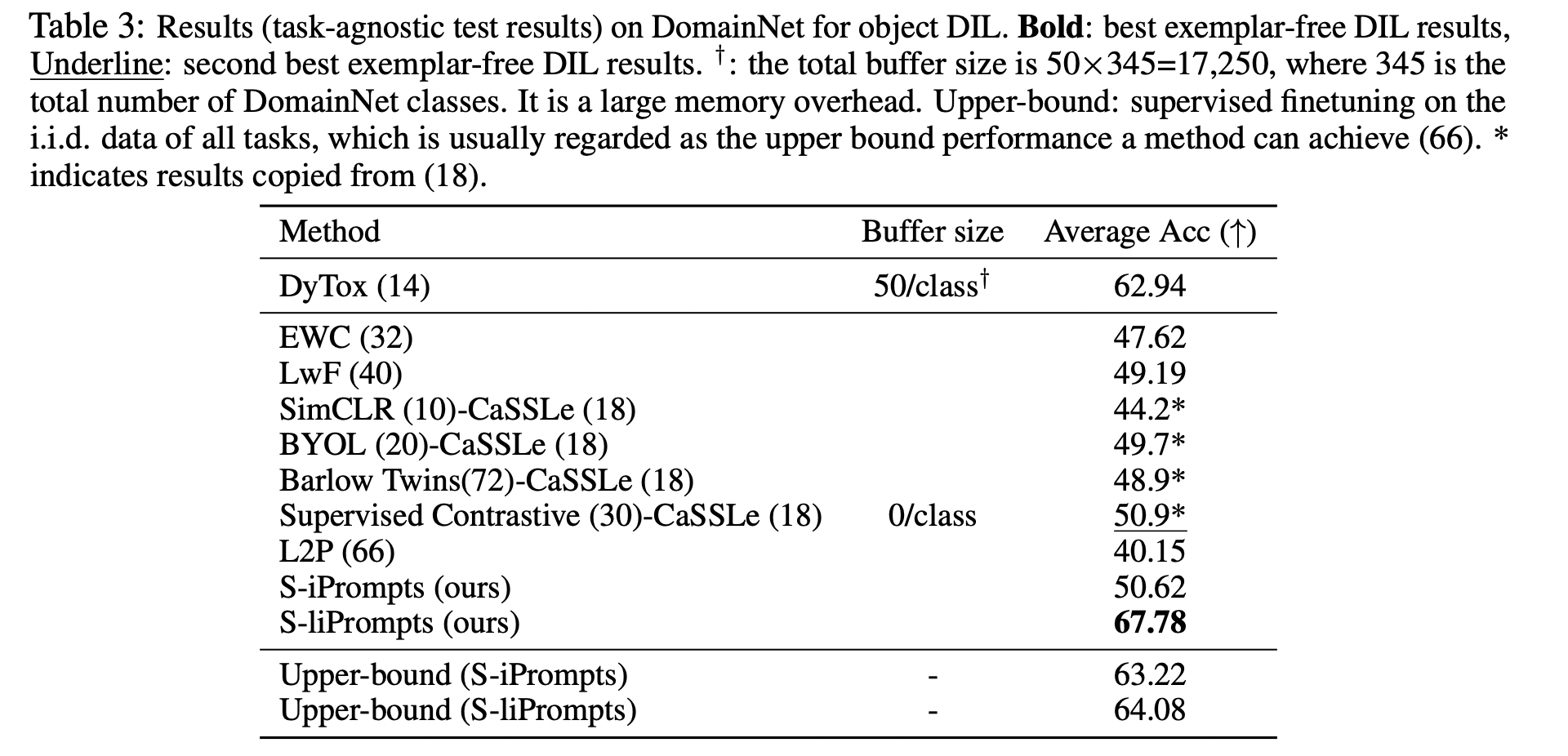
表3 DomainNet数据集结果
在本工作中作者提出使用Prompts来解决域增量学习中的灾难性遗忘现象,并且在多个数据集取得优秀的性能表现。尽管所提出的方法同时适用任务增量任务(TIL),但是还无法做类增量问题(CIL)。此外Prompts的设计还存在较大的优化空间,例如Prompts目前只作为最初的输入,但是Prompts的放置位置有很多可能性。最后,Prompt Tuning作为Efficient Finetuning技术的一种,未来可能会在增量学习中得到更深入的应用,特别是大规模预训练模型的兴起,会进一步推进对增量学习问题的研究。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢