
论文标题:LOLNeRF: Learn from One Look
论文链接:https://arxiv.org/abs/2111.09996
最近,来自英属哥伦比亚大学,西蒙菲莎大学和Google Research的研究人员发表在CVPR 2022上的一篇论文中提出了一个全新模型LOLNeRF,对于同一类物体来说,仅需单一视角即可训练NeRF模型,而无需对抗监督。一旦共享的生成模型训练完毕,模型即可提供近似的相机姿态(camera poses)。
简而言之,NeRF不再需要多视图,并且相机也无需非常精确就可以达到令人信服的效果。
将NeRF与GLO结合起来,给每个物体分配一个潜码,与标准的NeRF输入相连接,使其有能力重建多个物体。
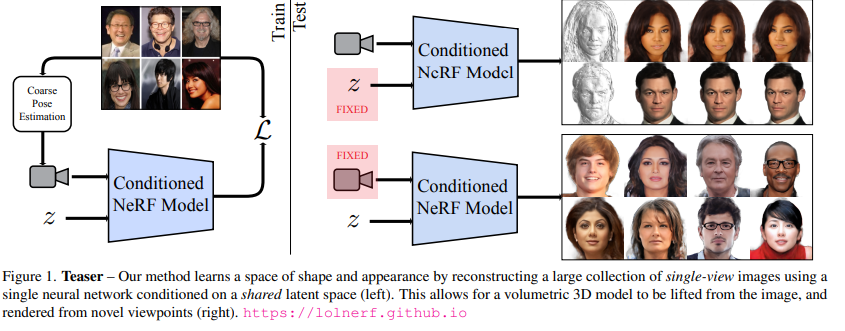

图 论文的效果图
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢