
作者:Xi Chen, Xiao Wang, Soravit Changpinyo, 等
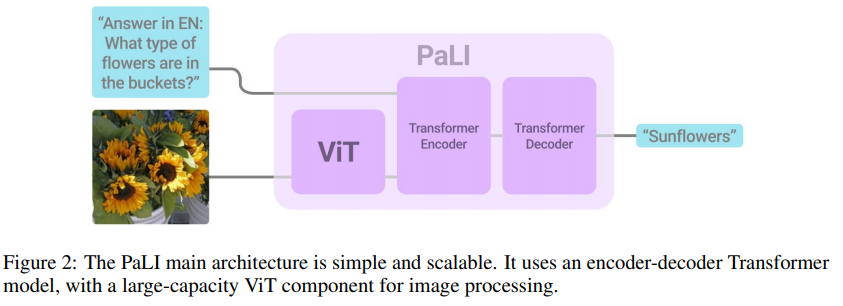
简介:本文以迄今最大的ViT模型、推动图像语言模型向前迈出重要一步。有效的扩展和灵活的任务接口,使大型语言模型能够在许多任务中表现出色。PaLI((Pathways Language and Image model:通道语言和图像模型)将这种方法扩展到语言和视觉的联合建模。PaLI 基于视觉和文本输入生成文本,并通过此接口以多语种:执行许多视觉、语言和多模式任务。为了训练 PaLI,作者使用了大型预训练的编码器-解码器语言模型和视觉Transformer(ViT)。这使作者能够利用:模型现有的能力与训练模型的大量成本。作者发现视觉和语言组件的联合扩展很重要。由于现有的语言Transformer比它们的视觉Transformer大得多,作者训练了迄今为止最大的 ViT (ViT-e),以量化更大容量视觉模型的好处。为了训练 PaLI,作者创建了一个大型多语言预训练任务组合,基于包含100余种语言的10B图像和文本的新图像-文本训练集。PaLI 在多种视觉和语言任务(例如字幕、视觉问答、场景文本理解)中实现了最先进的水平,同时保留了简单、模块化和可扩展的设计。

论文: https://arxiv.org/abs/2209.06794
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢