
【论文标题】Improve the Protein Complex Prediction with Protein Language Models
【作者团队】Bo Chen, Ziwei Xie, Jinbo Xu, Jiezhong Qiu, Zhaofeng Ye, Jie Tang
【发表时间】2022/09/17
【机 构】清华、芝加哥丰田计算技术研究所、腾讯
【论文链接】https://doi.org/10.1101/2022.09.15.508065
【代码链接】https://github.com/allanchen95/ColAttn
AlphaFold-Multimer极大地改善了蛋白质复合物的结构预测,但其准确性也取决于被预测复合物的相互作用的同源物(即interologs)所形成的多序列比对(MSA)的质量。本文致力于回答问题,能否利用蛋白质预训练语言模型(PLMs)所具有的共进化的信息识别有效的相互关系,并提出了一种新的方法,称为ColAttn,它可以通过利用语言模型来识别复合物的interologs。作者表明,ColAttn比AlphaFold-Multimer中默认的MSA生成方法能生成更好的interologs,该方法比AlphaFold-Multimer的复杂结构预测结果要好得多(就Top-5最佳DockQ而言,+10.7%),特别是当预测的复杂结构具有低置信度时。本文进一步表明,通过结合几种MSA生成方法,可以得到比AlphaFold-Multimer更好的复杂结构预测精度(就前5名最佳DockQ而言,+22%)。本文系统地分析了ColAttn算法的影响因素,发现interologs之间的MSA的多样性对预测的准确性有很大影响。此外ColAttn在真核生物的复合物上表现得特别好。
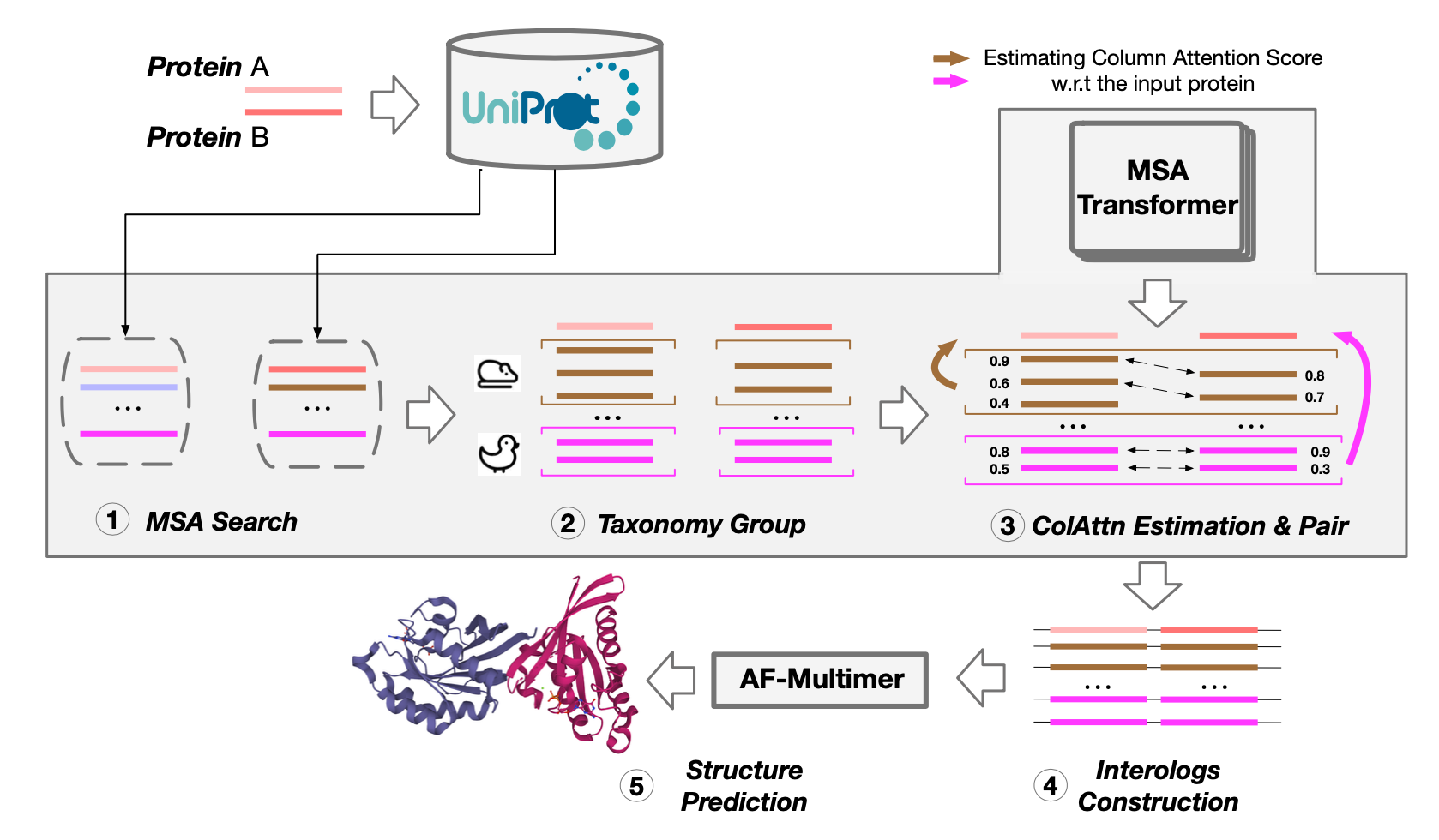
上图展示了基于预训练语言模型的MSA配对方法,ColAttn的框架,在输入一个查询序列后:
1)本文首先用JackHMMER搜索UniProt数据库,生成每个单链查询序列的MSA
2)将相同分类的序列归入同一聚类
3)使用MSA Transformer计算MSA的每个序列同源物与查询序列之间的列注意力分数,对列注意力矩阵进行对称并且在层、头、序列全长等维度进行聚合以获得MSA的成对相似度矩阵,随后从两个查询序列中匹配出注意力分数余弦相似度高的同一组的两个序列同源物,
4)通过直接串联连接两个匹配的序列同源物得到一个interologs
5)AlphaFold-Multimer将interologs的MSA作为输入来预测复杂结构。
对比的基于语言模型的算法为:
- InTraCos:不再使用列注意力分数,输入单链msa获得残基级别的嵌入,聚合各层和残基获得序列嵌入,计算查询序列嵌入与其他序列嵌入的余弦相似度并构建interologs
- InterGlobalCos:将问题看作最大权重二分匹配问题,构建不同链之间有边连接的图,应用KM(Kuhn-Munkres)算法寻找msa边配对
- InterLocalCos:基本假设是各个种属内与查询序列的相似度反应了信息量,应用贪婪算法反复寻找与查询序列有高相似度的配对
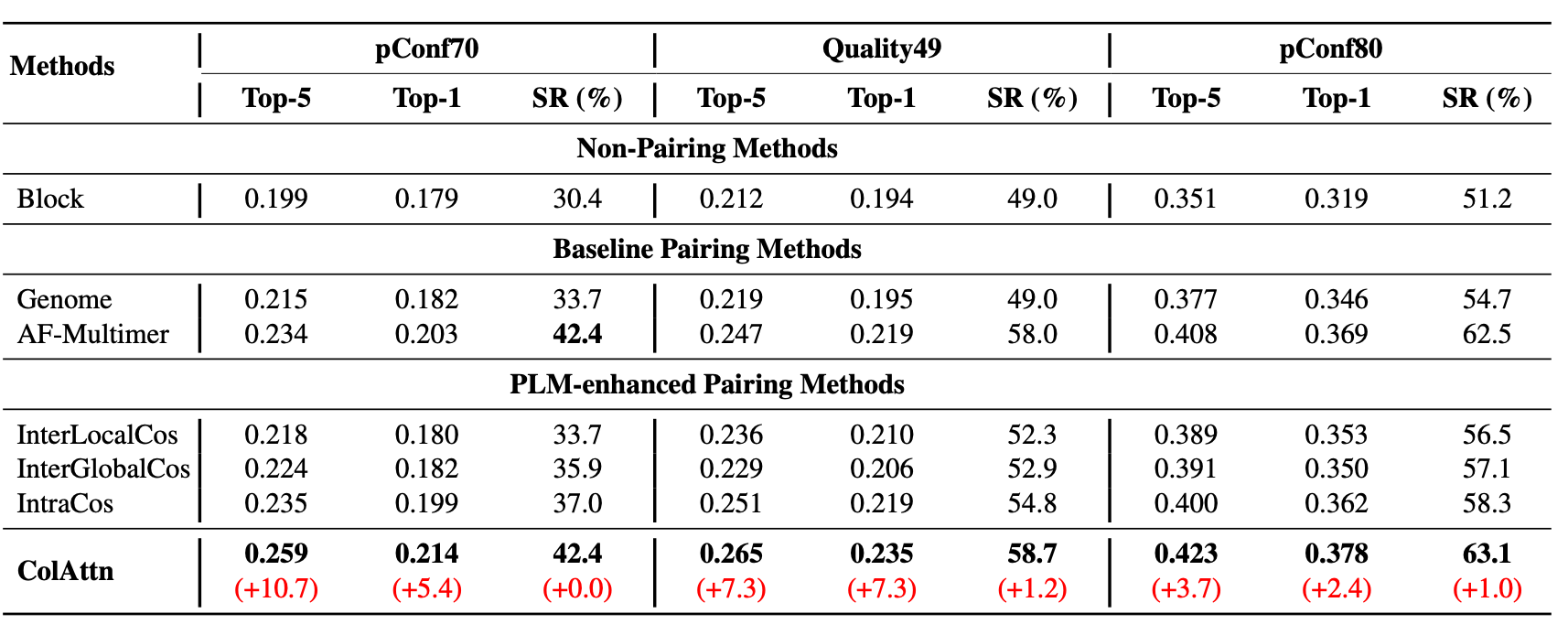
上图展示了PLM增强配对方法和基线的DockQ分数和成功率。本文报告了在pConf70、Quality49和pConf80测试集上Top-5最佳DockQ得分、Top-1最佳DockQ得分和成功率(DockQ≥0.23)的平均值。对于一个测试蛋白,本文使用五个AlphaFold-Multimer模型预测了5个不同的结构。红色下标代表本文的方法比AlphaFold-Multimer中默认的MSA配对策略的性能增益(%),实验结果证实:
- 本文提出的基于列的注意力的MSA配对方法优于AF-Multimer中使用的基于序列相似性的方法,以及基于混合噪声残基嵌入的余弦相似性方法(即IntraCos)。
- InTra方法在有效性和可扩展性方面都优于inter排名方法。
- ColAttn在低pConf(预测置信度)蛋白上表现更好。
- ColAttn在核细胞蛋白上有更高的预测准确率。
创新点
- 本文首次提出了一种简单而有效的MSA配对算法,该算法利用蛋白质语言模型的输出来形成联合MSA,即同源物的MSA。特别是,本文利用MSA Transformer的逐列注意力分数,从组成单链的MSA中识别和配对同源物。
- 此外,本文发现混合策略,即结合ColAttn和其他MSA配对方法,比标准的单一策略明显提高了结构预测精度。本文进一步分析了来自真核生物、细菌和古生物的复合体的性能,发现ColAttn在真核生物上的表现最好,因为对这些生物来说,识别互作是相当困难的。最引人注目的是,在一些组成链之一来自真核生物而另一个来自细菌的蛋白上,ColAttn大大超过了其他基线(总体性能比AlphaFold-Multimer提高了25%),这有力地证明了PLM增强的MSA配对方法是有效的。
- 然后,本文论述了interologs的多样性与预测精度有明显的正相关关系。
- 最后,本文探讨了其他利用MSA transformer输出的方法。例如,本文将序列嵌入之间的余弦相似度得分作为建立interologs的指标,其表现与Alphafold-Multimer中使用的默认方法相当。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢