
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:神经符号专家系统中可解释推理规则的动态生成、语言-视觉智能库LAVIS、通用标记物对应学习框架、基于单个目标的表示/潜空间模型/策略学习、专业/非专业自由手绘3D物体多视图草图数据集、重新思考语义分割的卷积注意力设计、离散空间局部平衡建议的最佳比例、基于不确定估计的看点学习、随机优化噪声相关性理论属性研究
1、[CL] Dynamic Generation of Interpretable Inference Rules in a Neuro-Symbolic Expert System
N Weir, B V Durme
[Johns Hopkins University]
神经符号专家系统中可解释推理规则的动态生成。本文提出一种系统推理的方法,该方法在事实库的基础上产生人工可解释的证明树。所提出的解决方案类似于经典的基于Prolog的推理引擎的风格,通过神经语言建模、指导性生成和半参数密集检索的组合来取代手工制定的规则。新的推理引擎NELLIE动态地实例化了可解释的推理规则,这些规则捕捉并对自然语言语句的包含(非)组合进行评分。NELLIE在需要对多个事实进行结构化解释的科学QA数据集上提供了有竞争力的性能。
We present an approach for systematic reasoning that produces human interpretable proof trees grounded in a factbase. Our solution resembles the style of a classic Prolog-based inference engine, where we replace handcrafted rules through a combination of neural language modeling, guided generation, and semiparametric dense retrieval. This novel reasoning engine, NELLIE, dynamically instantiates interpretable inference rules that capture and score entailment (de)compositions over natural language statements. NELLIE provides competitive performance on scientific QA datasets requiring structured explanations over multiple facts.
https://arxiv.org/abs/2209.07662




2、[CV] LAVIS: A Library for Language-Vision Intelligence
D Li, J Li, H Le, G Wang, S Savarese, S C.H. Hoi
[Salesforce Research]
LAVIS:语言-视觉智能库。本文提出LAVIS,一个用于语言-视觉研究和应用的开源深度学习库。LAVIS旨在作为一个一站式的综合开发库,为研究人员和从业人员提供语言-视觉领域的最新进展,并促进未来的研究和发展。它有一个统一的界面,可以方便地访问最先进的图像-语言、视频-语言模型和通用数据集。LAVIS支持各种任务的训练、评估和基准测试,包括多模态分类、检索、描述、视觉问答、对话和预训练。同时,该库还具有高度的可扩展性和可配置性,便于未来的开发和定制。本文描述了该库的设计原则、关键组件和功能,并介绍了常见语言-视觉任务的基准测试结果。
We introduce LAVIS, an open-source deep learning library for LAnguage-VISion research and applications. LAVIS aims to serve as a one-stop comprehensive library that brings recent advancements in the language-vision field accessible for researchers and practitioners, as well as fertilizing future research and development. It features a unified interface to easily access state-of-the-art imagelanguage, video-language models and common datasets. LAVIS supports training, evaluation and benchmarking on a rich variety of tasks, including multimodal classification, retrieval, captioning, visual question answering, dialogue and pre-training. In the meantime, the library is also highly extensible and configurable, facilitating future development and customization. In this technical report, we describe design principles, key components and functionalities of the library, and also present benchmarking results across common language-vision tasks. The library is available at: https://github.com/salesforce/LAVIS.
https://arxiv.org/abs/2209.09019


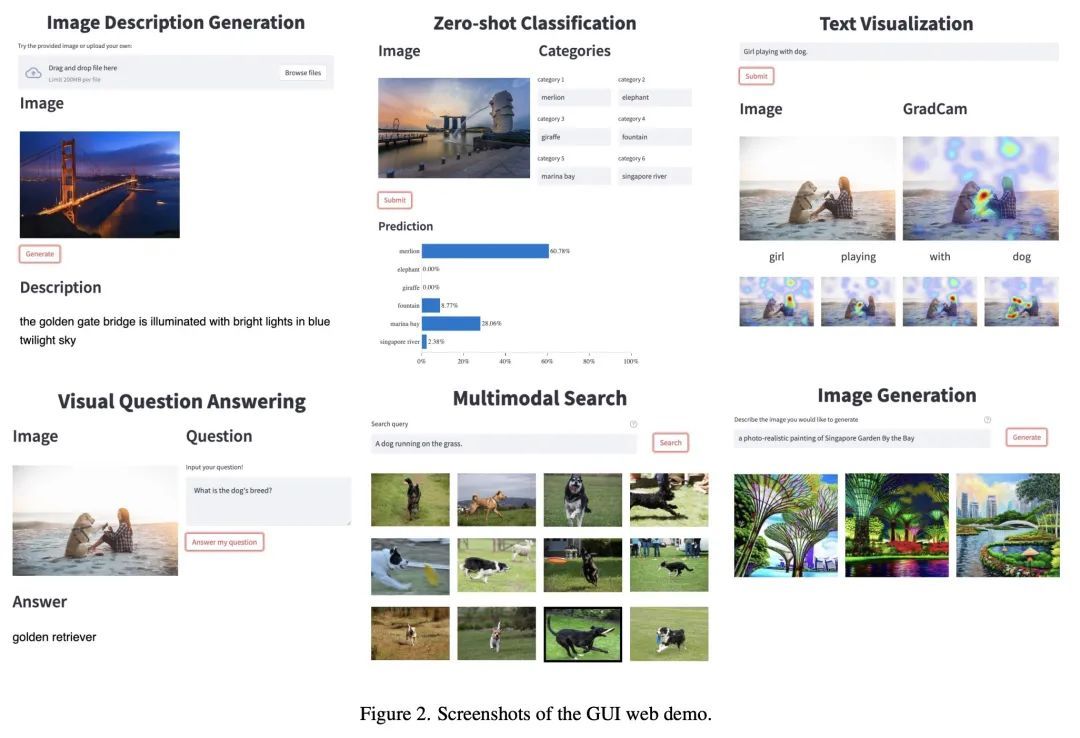

3、[CV] NeuralMarker: A Framework for Learning General Marker Correspondence
Z Huang, X Pan, W Pan, W Bian, Y Xu, K C Cheung, G Zhang, H Li
[The Chinese University of Hong Kong & Zhejiang University]
NeuralMarker: 通用标记物对应学习框架。本文要解决的问题,是估计通用标记物(如电影海报)与捕捉到这种标记物的图像间的对应关系。传统上,这个问题是通过拟合一个基于稀疏特征匹配的同源模型来解决的。然而,它们只能够处理类似平面的标记物,而且稀疏特征没有充分利用外观信息。本文提出一个新框架NeuralMarker,训练一个神经网络,在各种具有挑战性的条件下估计密集的标记物对应关系,如标记物变形、恶劣的光线等。此外,本文还提出一种新的标记对应关系评估方法,在真实的标记-图像对上进行标注,并创建了一个新的基准。实验表明,NeuralMarker明显优于之前的方法,并实现了新的有趣应用,包括增强现实(AR)和视频编辑。
We tackle the problem of estimating correspondences from a general marker, such as a movie poster, to an image that captures such a marker. Conventionally, this problem is addressed by fitting a homography model based on sparse feature matching. However, they are only able to handle plane-like markers and the sparse features do not sufficiently utilize appearance information. In this paper, we propose a novel framework NeuralMarker, training a neural network estimating dense marker correspondences under various challenging conditions, such as marker deformation, harsh lighting, etc. Besides, we also propose a novel marker correspondence evaluation method circumstancing annotations on real marker-image pairs and create a new benchmark. We show that NeuralMarker significantly outperforms previous methods and enables new interesting applications, including Augmented Reality (AR) and video editing.
https://arxiv.org/abs/2209.08896




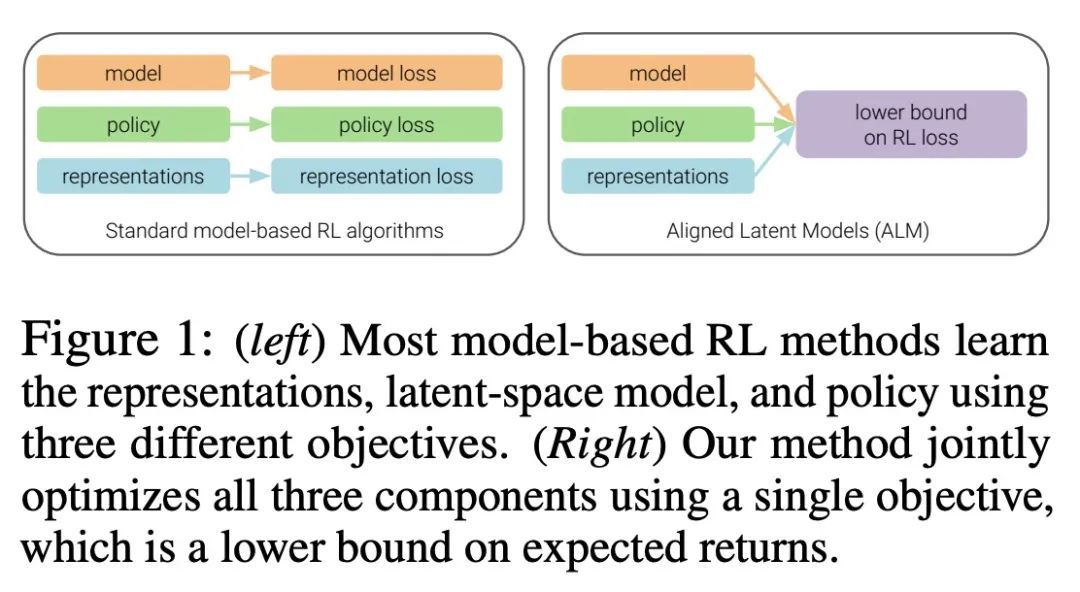
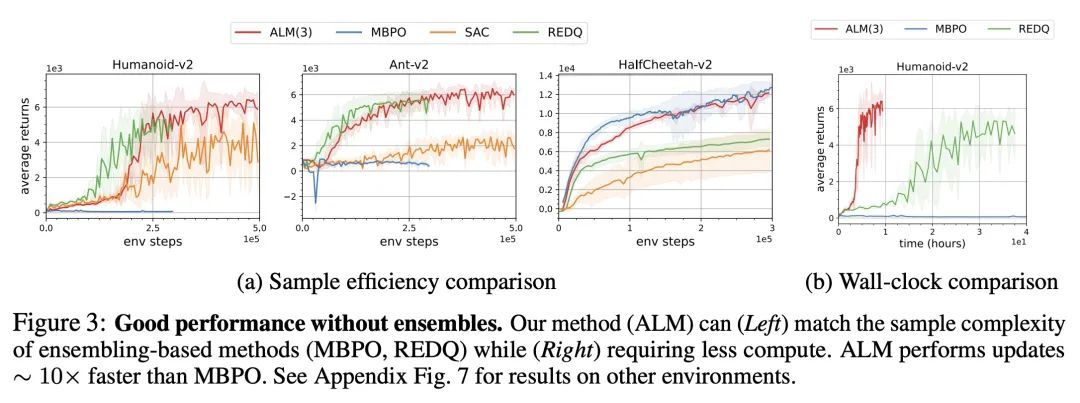
4、[LG] Simplifying Model-based RL: Learning Representations, Latent-space Models, and Policies with One Objective
R Ghugare, H Bharadhwaj, B Eysenbach, S Levine, R Salakhutdinov
[VNIT Nagpur & CMU & UC Berkeley]
简化基于模型强化学习:基于单个目标的表示、潜空间模型和策略学习。虽然学习环境的内部模型的强化学习(RL)方法有可能比无模型的同类方法更有样本效率,但学习来自高维传感器的原始观测数据的模型可能是一个挑战。之前的工作是通过辅助目标(如重建或价值预测)来学习低维观测数据,从而解决这一挑战。然而,这些辅助目标和强化学习目标之间的一致性往往并不明确。本文提出了一种单一目标,联合优化潜空间模型和策略,以实现高回报,同时保持自洽。该目标是预期收益的下界。与之前基于模型的强化学习在策略探索或模型保证上的界不同,所提出的界限是直接针对整体强化学习目标的。本文证明了由此产生的算法与之前最好的基于模型和无模型的强化学习方法的样本效率相匹配,甚至有所提高。虽然这些样本效率高的方法通常在计算上要求很高,但所提出方法以大约50%的实际运行时间达到了SAC的性能。
While reinforcement learning (RL) methods that learn an internal model of the environment have the potential to be more sample efficient than their model-free counterparts, learning to model raw observations from high dimensional sensors can be challenging. Prior work has addressed this challenge by learning lowdimensional representation of observations through auxiliary objectives, such as reconstruction or value prediction. However, the alignment between these auxiliary objectives and the RL objective is often unclear. In this work, we propose a single objective which jointly optimizes a latent-space model and policy to achieve high returns while remaining self-consistent. This objective is a lower bound on expected returns. Unlike prior bounds for model-based RL on policy exploration or model guarantees, our bound is directly on the overall RL objective. We demonstrate that the resulting algorithm matches or improves the sample-efficiency of the best prior model-based and model-free RL methods. While such sample efficient methods typically are computationally demanding, our method attains the performance of SAC in about 50% less wall-clock time.
https://arxiv.org/abs/2209.08466


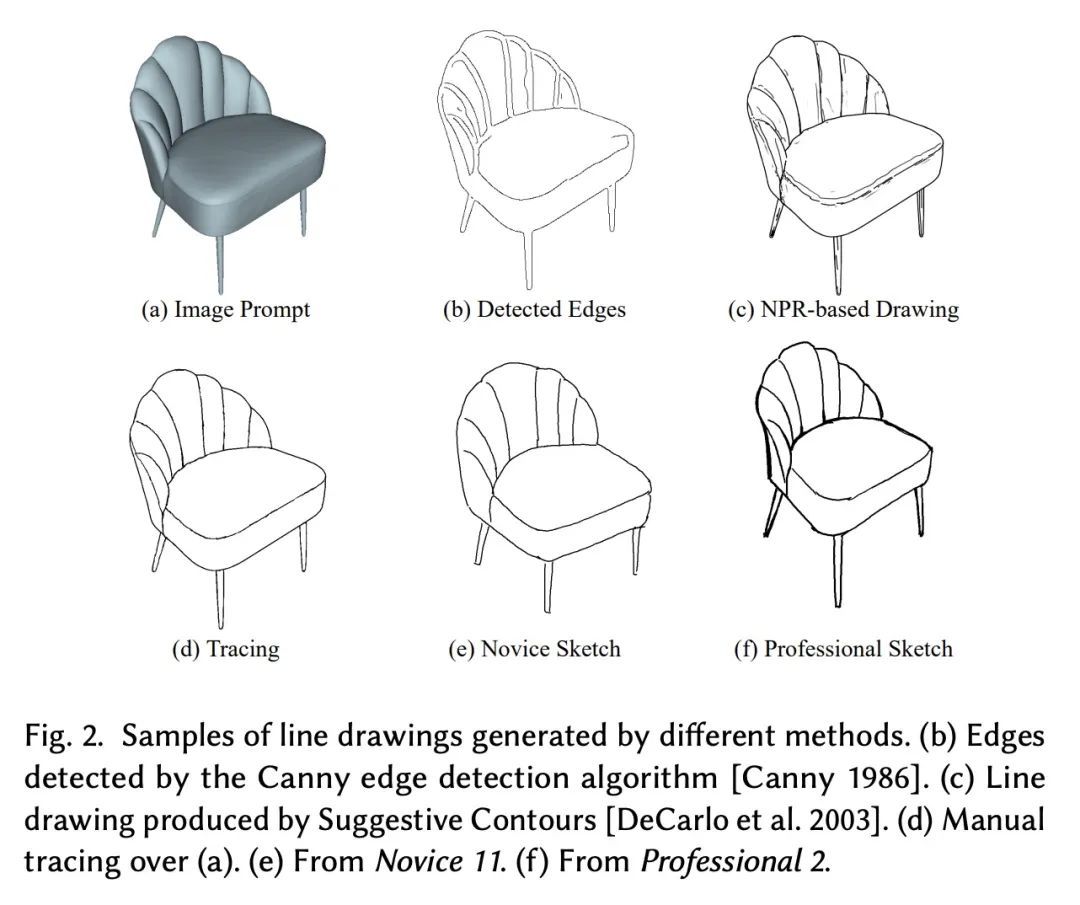
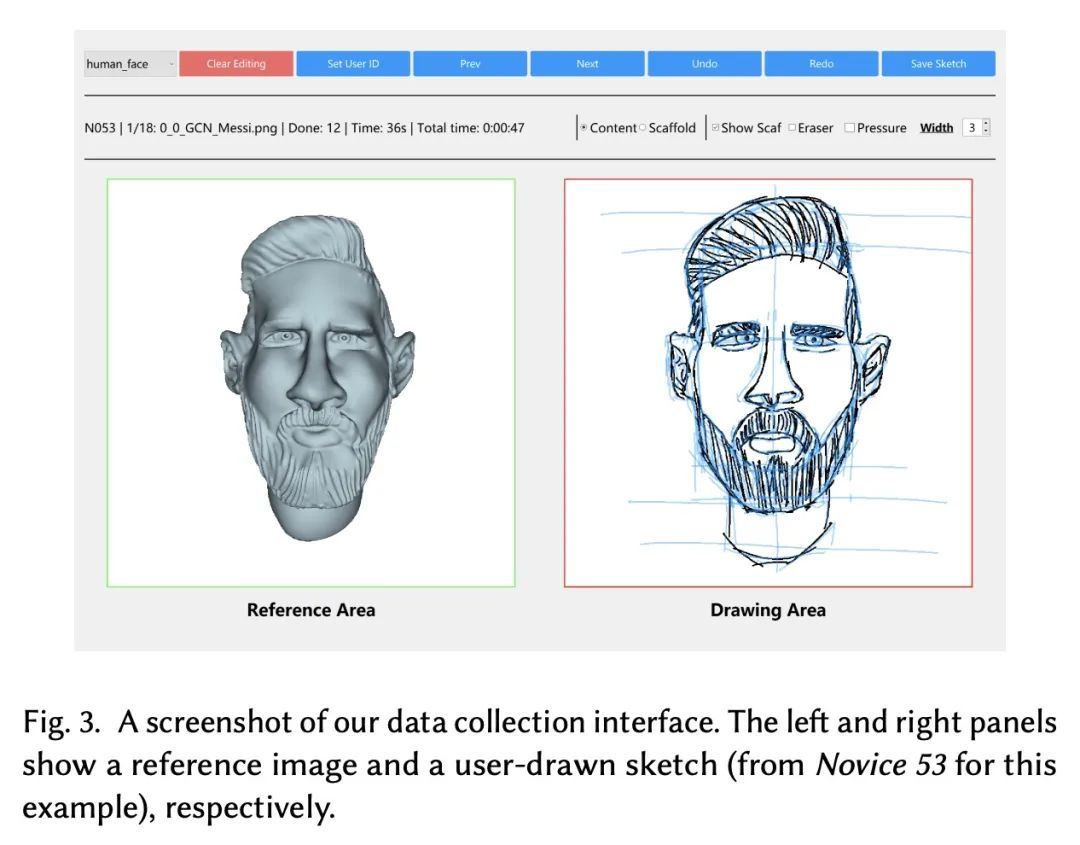
5、[CV] DifferSketching: How Differently Do People Sketch 3D Objects?
C Xiao, W Su, J Liao, Z Lian, Y Song, H Fu
[City University of Hong Kong & Peking University & University of Surrey]
DifferSketching:专业/非专业自由手绘3D物体多视图草图数据集。为了解人们如何绘制3D物体,人们提出了多种草图数据集。然而,这些数据集通常规模较小,涵盖的对象或类别也较少。此外,这些数据集所包含的自由手绘大多来自专家用户,因此很难比较专家用户和新手用户的绘画,而这种比较对于为这两个用户群体提供更有效的基于草图的界面至关重要。这些观察促使我们去分析具有和不具有足够绘画技能的人在绘制3D物体时有什么不同。本文邀请了70位新手用户和38位专家用户绘制136个3D物体的草图,这些物体以362幅多视图的形式呈现。得到了一个由3620张自由手绘的多视图草图组成的新的数据集,这些草图在某些视图下被标记为相应的3D物体。所提数据集比现有的数据集要大一个数量级。本文从三个层面,即草图层面、笔画层面和像素层面,在空间和时间特征下,以及在创作者群体内部和之间,对所收集的数据进行分析,结果发现,专业人员和新手的绘画在笔触层面上表现出明显的差异,包括内在的和外在的。在两个应用中证明了该数据集的有用性:(i)自由手绘风格的草图合成,以及(ii)将其作为基于草图的3D重建的潜在基准。
Multiple sketch datasets have been proposed to understand how people draw 3D objects. However, such datasets are often of small scale and cover a small set of objects or categories. In addition, these datasets contain freehand sketches mostly from expert users, making it difficult to compare the drawings by expert and novice users, while such comparisons are critical in informing more effective sketch-based interfaces for either user groups. These observations motivate us to analyze how differently people with and without adequate drawing skills sketch 3D objects. We invited 70 novice users and 38 expert users to sketch 136 3D objects, which were presented as 362 images rendered from multiple views. This leads to a new dataset of 3,620 freehand multi-view sketches, which are registered with their corresponding 3D objects under certain views. Our dataset is an order of magnitude larger than the existing datasets. We analyze the collected data at three levels, i.e., sketch-level, stroke-level, and pixel-level, under both spatial and temporal characteristics, and within and across groups of creators. We found that the drawings by professionals and novices show significant differences at stroke-level, both intrinsically and extrinsically. We demonstrate the usefulness of our dataset in two applications: (i) freehand-style sketch synthesis, and (ii) posing it as a potential benchmark for sketch-based 3D reconstruction. Our dataset and code are available at this https URL.
https://arxiv.org/abs/2209.08791


另外几篇值得关注的论文:
[CV] SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
SegNeXt:重新思考语义分割的卷积注意力设计
M Guo, C Lu, Q Hou, Z Liu, M Cheng, S Hu
[Tsinghua University & Nankai University & Fitten Tech]
https://arxiv.org/abs/2209.08575




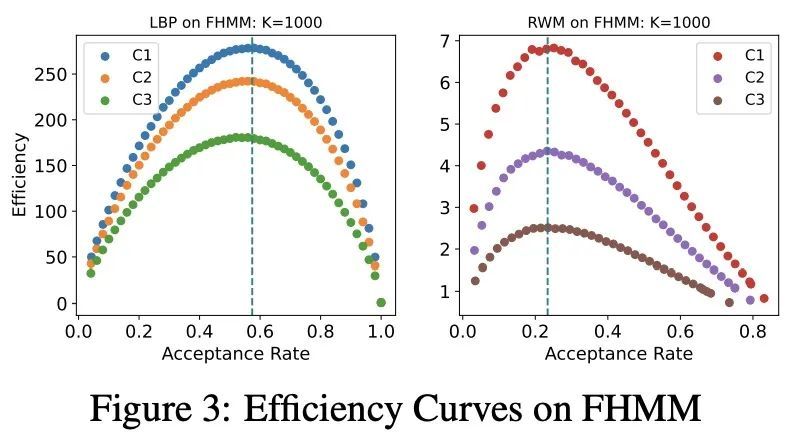
[LG] Optimal Scaling for Locally Balanced Proposals in Discrete Spaces
离散空间局部平衡建议的最佳比例
H Sun, H Dai, D Schuurmans
[Georgia Tech & Google Brain]
Optimal scaling has been well studied for Metropolis-Hastings (M-H) algorithms in continuous spaces, but a similar understanding has been lacking in discrete spaces. Recently, a family of locally balanced proposals (LBP) for discrete spaces has been proved to be asymptotically optimal, but the question of optimal scaling has remained open. In this paper, we establish, for the first time, that the efficiency of M-H in discrete spaces can also be characterized by an asymptotic acceptance rate that is independent of the target distribution. Moreover, we verify, both theoretically and empirically, that the optimal acceptance rates for LBP and random walk Metropolis (RWM) are 0.574 and 0.234 respectively. These results also help establish that LBP is asymptotically O(N23) more efficient than RWM with respect to model dimension N. Knowledge of the optimal acceptance rate allows one to automatically tune the neighborhood size of a proposal distribution in a discrete space, directly analogous to step-size control in continuous spaces. We demonstrate empirically that such adaptive M-H sampling can robustly improve sampling in a variety of target distributions in discrete spaces, including training deep energy based models.
https://arxiv.org/abs/2209.08183



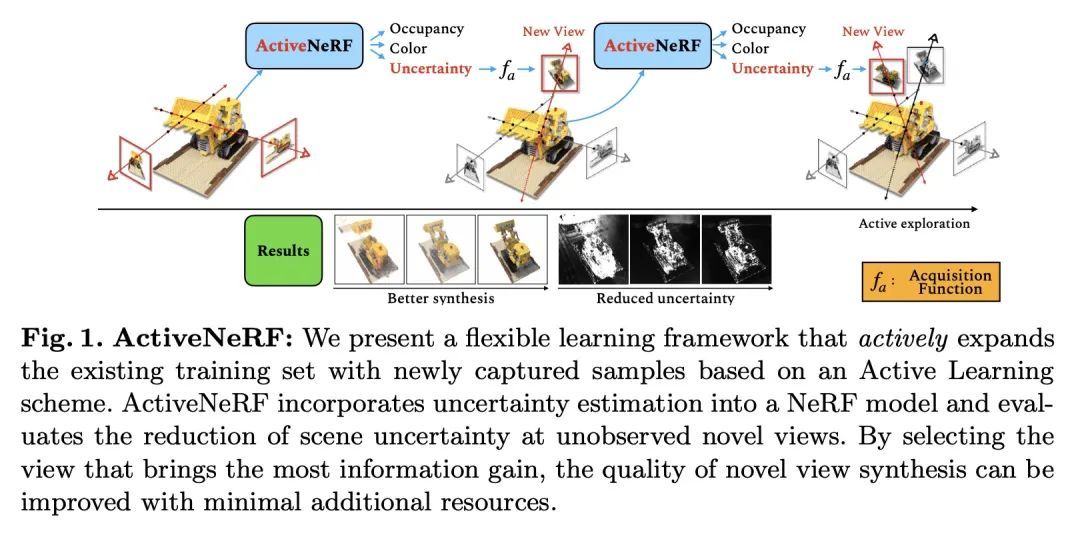
[CV] ActiveNeRF: Learning where to See with Uncertainty Estimation
ActiveNeRF:基于不确定估计的看点学习
X Pan, Z Lai, S Song, G Huang
[Tsinghua University & CMU]
https://arxiv.org/abs/2209.08546



[LG] On the Theoretical Properties of Noise Correlation in Stochastic Optimization
随机优化噪声相关性理论属性研究
A Lucchi, F Proske, A Orvieto, F Bach, H Kersting
[University of Basel & University of Oslo & ETH Zürich & PSL Research University]https://arxiv.org/abs/2209.09162




内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢