

Deformable PV-RCNN: Improving 3D Object Detection with Learned Deformations
本文提出了 Deformable PV-RCNN,一种基于点云的高性能 3D 目标检测器。目前,最先进的两阶段检测器使用的proposal细化方法不能充分适应不同尺度的目标对象、不同的点云密度、部分变形和杂波。作者提出了一个受 2D 可变形卷积网络启发的proposal细化模块,该模块可以从存在信息内容的位置自适应地收集特定于实例的特征。作者还提出了一种简单的上下文门控机制,允许关键点为细化阶段选择相关的上下文信息。
1、简介
点云的 3D 目标检测对于自动驾驶和机器人技术至关重要。PV-RCNNs 成功的部分原因是随机采样的关键点捕获多尺度特征以进行proposal细化,同时保留细粒度的定位信息。
然而,随机抽样对潜在的模糊场景无效。例如,在点云中很难区分行人和交通杆。在这种情况下,作者希望将关键点对准最具辨别力的区域,以便可以突出显示行人的主要特征。同样,汽车、行人和骑自行车的人的比例也大不相同。虽然多尺度特征聚合有利于图像特征,但点云的非均匀密度使得使用单个模型很难检测到它们。
作者希望自适应地聚合并关注它们在不同尺度上最显著的特征。最后,为了处理混乱并避免误检,例如,为了避免将所有坐着的人检测为骑自行车的人,需要了解分布不均的上下文信息。
本文构建了 Deformable PV-RCNN,这是一种处理 LIDAR 点稀疏性的 3D 检测器,能够适应非均匀点云密度,尤其是在远距离处,并且可以解决现实世界交通场景中的杂波问题。作者表明,本文方法可以在不同类别上优于 PV-RCNN,尤其是在 KITTI 3D 目标检测数据集上的远距离目标。
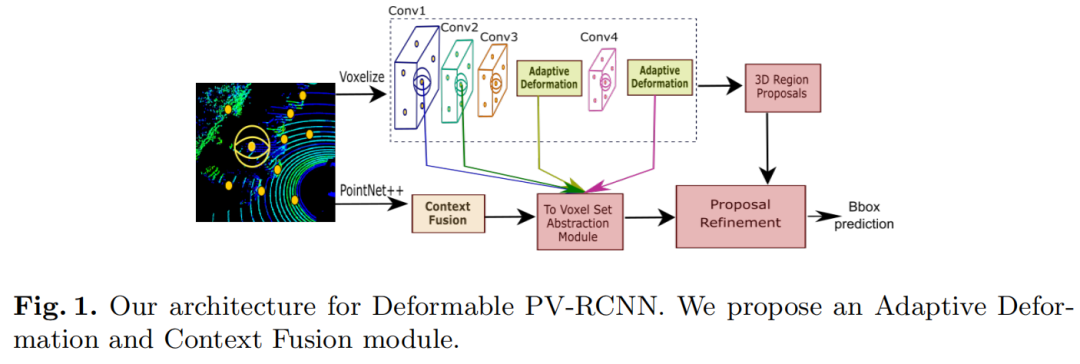
3D 检测的Pipeline如图 1 所示。它由Adaptive Deformation module(图 2)和Context Fusion module(图 3)组成。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢