
文章信息
来源:Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD 2022)
标题:Learning Binarized Graph Representations with Multi-faceted Quantization Reinforcement for Top-K Recommendation
作者:Chen, Yankai and Guo, Huifeng and Zhang, Yingxue and Ma, Chen and Tang, Ruiming and Li, Jingjie and King, Irwin
链接:https://dl.acm.org/doi/10.1145/3534678.3539452
内容简介
为了执行有效的在线推理,表示量化(Quantization),旨在通过离散数字的紧凑序列嵌入潜在特征。然而,现有工作仅关注数值量化,而忽略了伴随的信息丢失问题,从而导致性能明显下降。
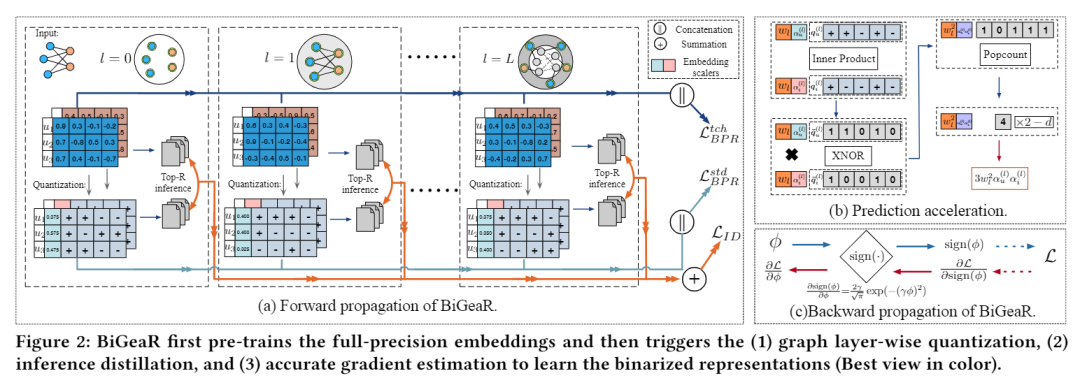
本文中提出了一种新颖的量化框架来学习 Top-K 推荐 (BiGeaR) 的二值化图表示。本文在二值化表示学习的前期、中期和后期引入了多方面的量化强化,这基本上保留了针对嵌入二值化的信息量。除了节省内存占用外,它还通过按位运算进一步开发了可靠的在线推理加速,为实际部署提供了替代的灵活性。五个大型真实世界基准的经验结果表明,BiGeaR 比最先进的基于量化的推荐系统实现了约 22%~40% 的性能提升,并恢复了约 95%~102% 的性能能力。最佳的全精度对应物,时间和空间减少超过 8 倍。
本文的主要贡献有:
- 潜在特征的有限表现力由于离散约束,将全精度嵌入映射到具有相同表达能力的紧凑二进制代码是 NP-hard。因此,不是提出用于量化的复杂和深度神经结构,而是广泛采用 sign(·) 函数来实现 嵌入二值化。但是,这仅保证每个嵌入条目的符号 (+/-) 相关性。与原始的全精度嵌入相比,由 sign(·) 生成的二值化目标自然信息量较少。
- 排名能力下降排名能力作为 Top-K 推荐的基本衡量标准,是主要工作目标。除了数值量化中不可避免的特征损失之外,之前的工作进一步忽略了由全精度和二值化嵌入推断出的隐藏知识的差异。然而,这种隐藏的知识对于揭示用户对不同项目的偏好至关重要,失去这些可能会因此导致排名能力下降和次优模型学习。
- 梯度估计不准确由于量化函数符号 (·) 的不可微性,直通估计器 (STE)被广泛采用,以在反向传播中假设所有传播的梯度为 1 。直观上看,1的积分是sign(·)以外的某个线性函数,而这可能会导致梯度估计不准确,在模型训练中产生不一致的优化方向。
BiGear 方法论
BiGeaR 框架如图 2(a) 所示。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢