
异常检测(又称outlier detection、anomaly detection、离群值检测)是一种重要的数据挖掘或机器学习方法,可以找到与“主体数据分布”不同的异常值(deviant from the general data distribution),比如从信用卡交易中找出诈骗案例,从正常的网络数据流中找出入侵,在正常案例中找到罕见病患者,有非常广泛的商业应用价值。同时它可以被用于机器学习任务中的预处理(preprocessing),防止因为少量异常点存在而导致的训练或预测失败。
当然,每年各大会议和期刊都少不了异常检测的论文,少则几篇,多则几十篇。但是,我们真的看到异常检测领域的发展了吗?新提出的算法真的更好嘛?为了回答这个问题,这两年我参与发表了三篇NeurIPS分别研究了:
-
图数据上的异常检测(Benchmarking Node Outlier Detection on Graphs-https://openreview.net/forum%3Fid%3DYXvGXEmtZ5N) -
网格数据上的异常检测 (ADBench: Anomaly Detection Benchmark-https://openreview.net/forum%3Fid%3DfoA_SFQ9zo0) -
时间序列上的异常检测(Revisiting Time Series Outlier Detection: Definitions and Benchmarks-https://openreview.net/forum%3Fid%3Dr8IvOsnHchr)
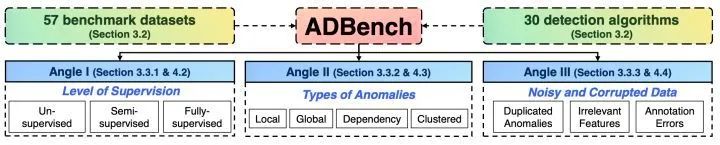
在我们最新的45页论文 ADBench:Anomaly Detection Benchmark(https://arxiv.org/abs/2206.09426)中,我们(@芝士确实是热量@局关THU)尝试通过10万个实验来定量分析网格数据(tabular data)中的这个问题。你会在这篇论文中看到:
-
30个异常检测算法在57个基准数据上的表现(算法和数据均可下载:https://github.com/Minqi824/ADBench),其中有10个我们设计的新数据) -
不同变量下的异常检测算法表现:(i)比如当我们有一定的标签时(supervision)(ii)比如我们遇到不同类型的异常时(iii)以及当我们的数据中存在噪音(noise)或者损坏时(corruption) -
我们认为的新的重要的异常检测研究方向:
-
无监督异常检测的评估、模型选择和设计:我们的实验结果说明了自动机器学习(automl)和自监督学习、迁移学习对于无监督异常检测的重要性。 -
半监督学习在极少标签的优异效果指明了它可能是最适合我们继续探索的方向 -
当我们知道(数据的)异常类型时,它可以被用作重要的先验知识 -
面对数据中的噪音和问题,设计抗噪(noise-resilient)异常检测算法是很重要的方向
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢