
LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 AS - 音频与语音 RO - 机器人
转自爱可可爱生活
摘要:面向现实世界规划的开放词表可查询场景表示、重新思考其对称性来理解和扩展子图GNN、Transformer模型松弛注意力、面向分布外检测的极其简单的激活整形、具有线性复杂度的节能注意力、零样本文本驱动HDR全景生成、基于神经隐映射和深度特征跟踪的端到端RGB-D SLAM、通用极小极大最优学习器和表征、基于信息最大化准则的自监督学习
1、[RO] Open-vocabulary Queryable Scene Representations for Real World Planning
B Chen, F Xia, B Ichter, K Rao, K Gopalakrishnan, M S. Ryoo, A Stone, D Kappler
[MIT & Robotics at Google]
面向现实世界规划的开放词表可查询场景表示。大型语言模型(LLM)已经从人工指令中解锁了任务规划的新能力。然而,之前将LLM应用于现实世界的机器人任务的尝试由于缺乏周围场景的基础而受到限制。本文开发了NLMap,一个开放词汇和可查询的场景表示法来解决这个问题。NLMap作为一个框架,用来收集和整合上下文信息到LLM规划器中,使它们能够在生成一个有上下文条件的规划之前看到并查询场景中的可用对象。NLMap首先用视觉语言模型(VLM)建立了一个自然语言可查询的场景表示。一个基于LLM的对象建议模块对指令进行解析,并提出所涉及的对象,以查询场景表示中的对象可用性和位置。然后,LLM规划器利用这些关于场景的信息进行规划。NLMap允许机器人在没有固定对象清单或可执行选项的情况下进行操作,从而实现了之前的方法无法实现的真正的机器人操作。
Large language models (LLMs) have unlocked new capabilities of task planning from human instructions. However, prior attempts to apply LLMs to real-world robotic tasks are limited by the lack of grounding in the surrounding scene. In this paper, we develop NLMap, an open-vocabulary and queryable scene representation to address this problem. NLMap serves as a framework to gather and integrate contextual information into LLM planners, allowing them to see and query available objects in the scene before generating a context-conditioned plan. NLMap first establishes a natural language queryable scene representation with Visual Language models (VLMs). An LLM based object proposal module parses instructions and proposes involved objects to query the scene representation for object availability and location. An LLM planner then plans with such information about the scene. NLMap allows robots to operate without a fixed list of objects nor executable options, enabling real robot operation unachievable by previous methods.
https://arxiv.org/abs/2209.09874




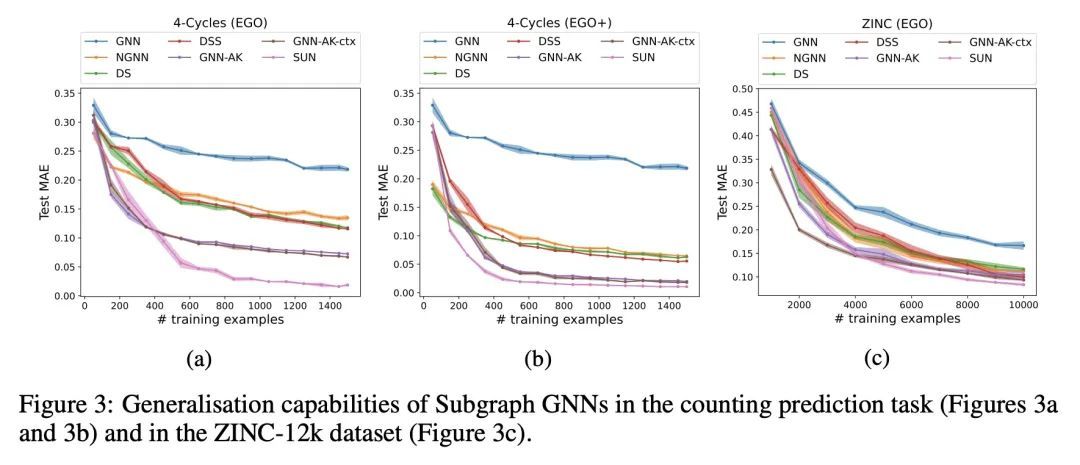
2、[LG] Understanding and Extending Subgraph GNNs by Rethinking Their Symmetries
F Frasca, B Bevilacqua, M M. Bronstein, H Maron
[Imperial College London & Purdue University & University of Oxford & NVIDIA Research]
重新思考其对称性来理解和扩展子图GNN。子图GNN是最近一类具有表现力的图神经网络(GNN),它将图建模为子图的集合。到目前为止,可能的子图GNN架构的设计空间以及它们的基本理论属性在很大程度上仍未被探索。本文研究了最突出的子图方法的形式,采用了基于节点的子图选择策略,如自我网络或节点标记和删除。本文提出了两个核心问题:(1)这些方法表达能力的上限在哪里?(2)这些子图集上的等价消息传递层族是什么?本文回答这些问题的第一步是一种新的对称性分析,它表明为基于节点的子图集合的对称性建模需要一个比之前的工作中采用的对称组小得多的对称组。然后,这一分析被用来建立子图GNN和不变图网络(IGN)之间的联系。本文首先通过3-WL对子图方法的表达能力进行了限定,然后为子图方法提出了一个通用的消息传递层族,概括了以前所有基于节点的子图GNN。最后,设计了一种新的子图GNN,称为SUN,在理论上统一了之前的架构,同时在多个基准上提供更好的经验性能。
Subgraph GNNs are a recent class of expressive Graph Neural Networks (GNNs) which model graphs as collections of subgraphs. So far, the design space of possible Subgraph GNN architectures as well as their basic theoretical properties are still largely unexplored. In this paper, we study the most prominent form of subgraph methods, which employs node-based subgraph selection policies such as ego-networks or node marking and deletion. We address two central questions: (1) What is the upper-bound of the expressive power of these methods? and (2) What is the family of equivariant message passing layers on these sets of subgraphs?. Our first step in answering these questions is a novel symmetry analysis which shows that modelling the symmetries of node-based subgraph collections requires a significantly smaller symmetry group than the one adopted in previous works. This analysis is then used to establish a link between Subgraph GNNs and Invariant Graph Networks (IGNs). We answer the questions above by first bounding the expressive power of subgraph methods by 3-WL, and then proposing a general family of message-passing layers for subgraph methods that generalises all previous node-based Subgraph GNNs. Finally, we design a novel Subgraph GNN dubbed SUN, which theoretically unifies previous architectures while providing better empirical performance on multiple benchmarks.
https://arxiv.org/abs/2206.11140



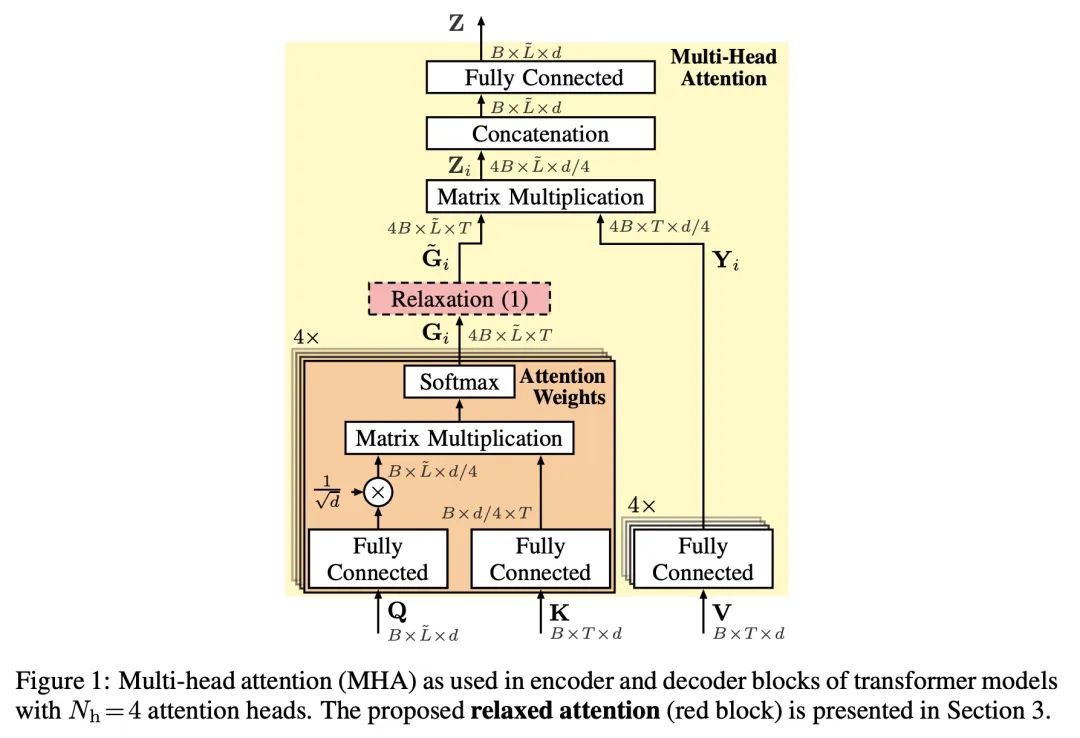
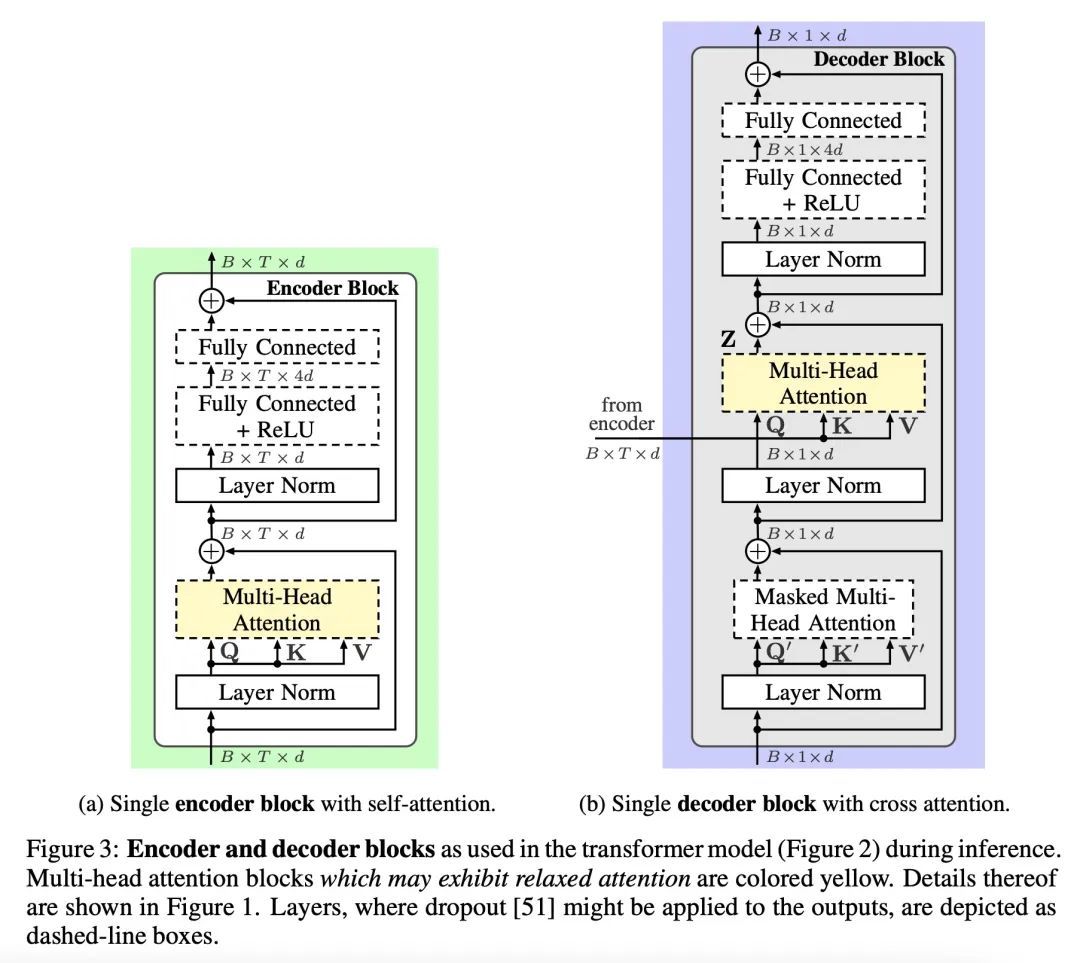
3、[LG] Relaxed Attention for Transformer Models
T Lohrenz, B Möller, Z Li, T Fingscheidt
[Technische Universität Braunschweig]
Transformer模型松弛注意力。基于全注意力的Transformer架构的强大建模能力往往会导致过拟合,并且对于自然语言处理任务来说,会导致自回归Transformer解码器中隐含的内部语言模型的学习,从而使外部语言模型的整合变得复杂。本文探讨了松弛注意力,一种简单易行的注意力权重平滑,对一般的变换器Transformer结构产生了双重的改进。首先,松弛注意力在应用于编码器中的自注意力层时提供了正则化。其次,它自然支持外部语言模型的整合,因为它通过松弛解码器中的交叉注意力来抑制隐性学习的内部语言模型。本文证明了松弛注意力在几个任务中的好处,与最近的基准方法相结合,有明显的改善。具体来说,在最大的开放唇读LRS3基准上,以26.31%的单词错误率超过了以前最先进的性能,在没有外部语言模型和几乎没有额外模型参数的情况下,在IWSLT14(DE→EN)机器翻译任务上取得了37.67分的最高性能的BLEU分数。
The powerful modeling capabilities of all-attention-based transformer architectures often cause overfitting and—for natural language processing tasks—lead to an implicitly learned internal language model in the autoregressive transformer decoder complicating the integration of external language models. In this paper, we explore relaxed attention, a simple and easy-to-implement smoothing of the attention weights, yielding a two-fold improvement to the general transformer architecture: First, relaxed attention provides regularization when applied to the self-attention layers in the encoder. Second, we show that it naturally supports the integration of an external language model as it suppresses the implicitly learned internal language model by relaxing the cross attention in the decoder. We demonstrate the benefit of relaxed attention across several tasks with clear improvement in combination with recent benchmark approaches. Specifically, we exceed the former state-of-the-art performance of 26.90% word error rate on the largest public lip-reading LRS3 benchmark with a word error rate of 26.31%, as well as we achieve a top-performing BLEU score of 37.67 on the IWSLT14 (DE→EN) machine translation task without external language models and virtually no additional model parameters. Code and models will be made publicly available.
https://arxiv.org/abs/2209.09735


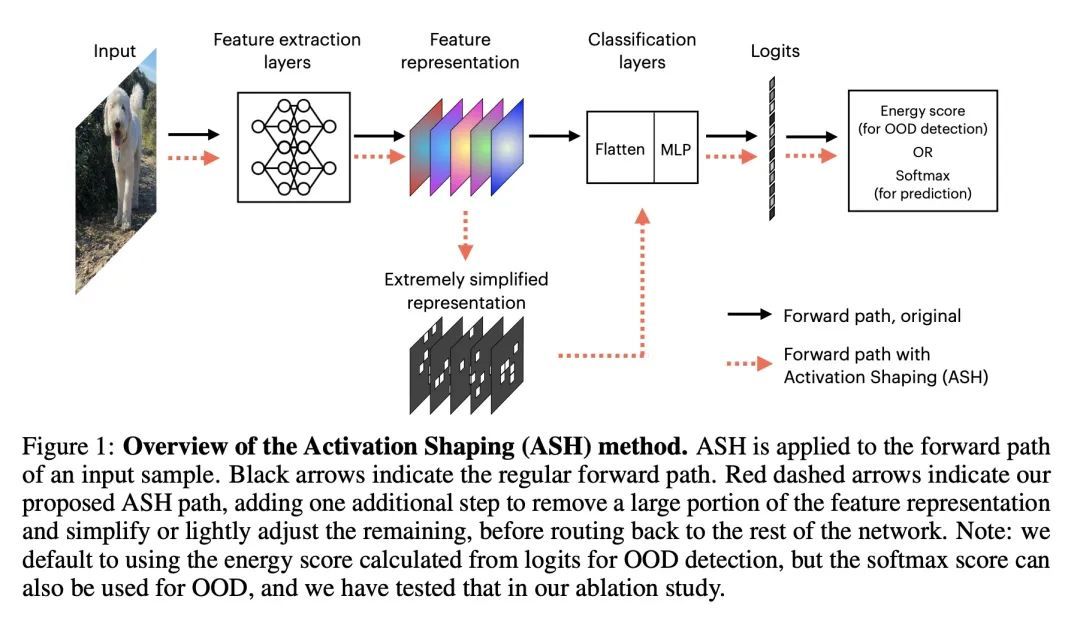
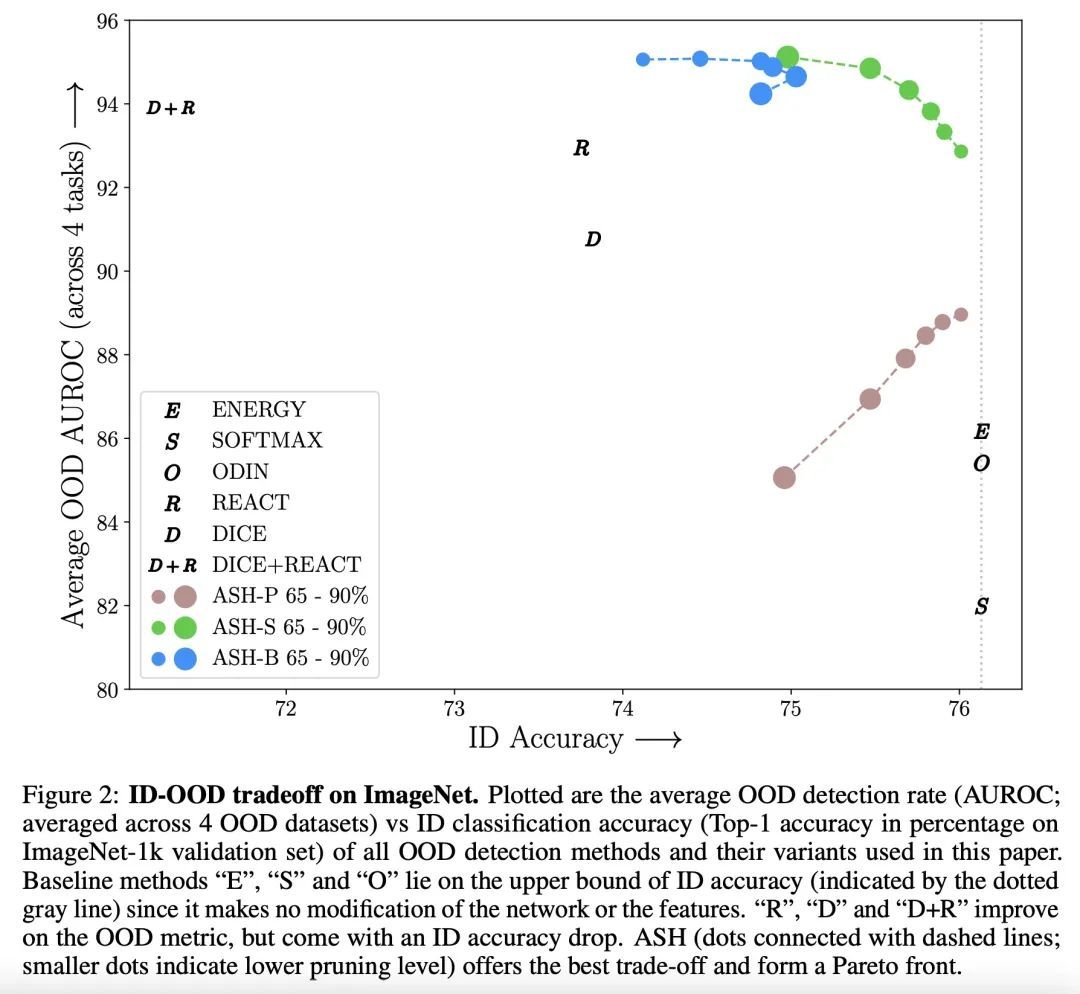
4、[LG] Extremely Simple Activation Shaping for Out-of-Distribution Detection
A Djurisic, N Bozanic, A Ashok, R Liu
[ML Collective]
面向分布外检测的极其简单的激活整形。机器学习模型的训练和部署是分开的,这意味着在训练中并不能预见到部署中遇到的所有情况,因此仅仅依靠训练中的进展是有局限的。分布外(OOD)检测是一个重要的领域,它对模型处理未见情况的能力进行了压力测试。模型是否知道他们不知道的情况?现有的OOD检测方法要么产生额外的训练步骤,要么产生额外的数据,要么对训练好的网络进行非实质性的修改。相比之下,本文提出一种极其简单的、事后的、即时的激活整形方法,即ASH,其中一个样本的大部分(例如90%)在后期层的激活被移除,其余的(例如10%)被简化或轻度调整。整形是在推理时应用的,不需要从训练数据中计算任何统计数据。实验表明,这种简单的处理方法增强了分布内和分布外样本的区分,从而允许在ImageNet上进行最先进的OOD检测,并且不会明显地恶化分布内的精度。
The separation between training and deployment of machine learning models implies that not all scenarios encountered in deployment can be anticipated during training, and therefore relying solely on advancements in training has its limits. Out-of-distribution (OOD) detection is an important area that stress-tests a model’s ability to handle unseen situations: Do models know when they don’t know? Existing OOD detection methods either incur extra training steps, additional data or make nontrivial modifications to the trained network. In contrast, in this work, we propose an extremely simple, post-hoc, on-the-fly activation shaping method, ASH, where a large portion (e.g. 90%) of a sample’s activation at a late layer is removed, and the rest (e.g. 10%) simplified or lightly adjusted. The shaping is applied at inference time, and does not require any statistics calculated from training data. Experiments show that such a simple treatment enhances in-distribution and outof-distribution sample distinction so as to allow state-of-the-art OOD detection on ImageNet, and does not noticeably deteriorate the in-distribution accuracy. We release alongside the paper two calls for explanation and validation, encouraging collective participation to further validate and understand the discovery. Calls, video and code can be found at: https://andrijazz.github.io/ash.
https://arxiv.org/abs/2209.09858


5、[CV] EcoFormer: Energy-Saving Attention with Linear Complexity
J Liu, Z Pan, H He, J Cai, B Zhuang
[Monash University]
EcoFormer:具有线性复杂度的节能注意力。Transformer是一个为顺序数据建模的转换框架,在广泛的任务中取得了显著的性能,但计算和能源成本很高。为了提高其效率,一个流行的选择是通过二进制化来压缩模型,二进制化将浮点值约束为二进制值,以节省资源消耗,因为位操作很便宜。然而,现有的二进制化方法只是为了在统计上最小化输入分布的信息损失,而忽略了作为注意力机制核心的成对相似性建模。为此,本文提出一种新的二进制化范式,通过核化哈希定制的高维softmax注意力,称为EcoFormer,将原始查询和键映射为汉明空间的低维二进制代码。核化哈希函数是以自监督方式学习的,以匹配从注意力图中提取的真实相似性关系。基于二进制代码的内积和汉明距离之间的等价关系以及矩阵乘法的关联属性,可以通过将注意力表达为二进制代码的点积来近似地计算其线性复杂性。此外,查询和键的紧凑二进制表示使得能用简单的累积来取代注意力中大多数昂贵的乘法-累积操作,从而在边缘设备上节省大量的片上能源。在视觉和语言任务上的大量实验表明,EcoFormer始终能达到与标准注意力相当的性能,而消耗的资源却少得多。例如,基于PVTv2-B0和ImageNet-1K,Ecoformer实现了73%的能源开销减少,而与标准注意力相比,性能只下降了0.33%。
Transformer is a transformative framework that models sequential data and has achieved remarkable performance on a wide range of tasks, but with high computational and energy cost. To improve its efficiency, a popular choice is to compress the models via binarization which constrains the floating-point values into binary ones to save resource consumption owing to cheap bitwise operations significantly. However, existing binarization methods only aim at minimizing the information loss for the input distribution statistically, while ignoring the pairwise similarity modeling at the core of the attention mechanism. To this end, we propose a new binarization paradigm customized to high-dimensional softmax attention via kernelized hashing, called EcoFormer, to map the original queries and keys into low-dimensional binary codes in Hamming space. The kernelized hash functions are learned to match the ground-truth similarity relations extracted from the attention map in a self-supervised way. Based on the equivalence between the inner product of binary codes and the Hamming distance as well as the associative property of matrix multiplication, we can approximate the attention in linear complexity by expressing it as a dot-product of binary codes. Moreover, the compact binary representations of queries and keys enable us to replace most of the expensive multiply-accumulate operations in attention with simple accumulations to save considerable on-chip energy footprint on edge devices. Extensive experiments on both vision and language tasks show that EcoFormer consistently achieves comparable performance with standard attentions while consuming much fewer resources. For example, based on PVTv2-B0 and ImageNet-1K, Ecoformer achieves a 73% energy footprint reduction with only a 0.33% performance drop compared to the standard attention. Code is available at this https URL.
https://arxiv.org/abs/2209.09004


另外几篇值得关注的论文:
[CV] Text2Light: Zero-Shot Text-Driven HDR Panorama Generation
Text2Light:零样本文本驱动HDR全景生成
Z Chen, G Wang, Z Liu
[Nanyang Technological University]
https://arxiv.org/abs/2209.09898




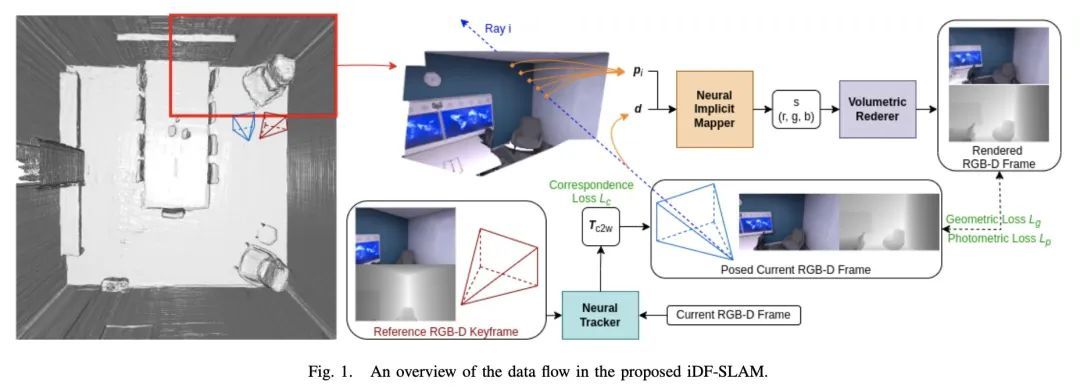
[RO] iDF-SLAM: End-to-End RGB-D SLAM with Neural Implicit Mapping and Deep Feature Tracking
iDF-SLAM:基于神经隐映射和深度特征跟踪的端到端RGB-D SLAM
Y Ming, W Ye, A Calway
[University of Bristol & Zhejiang University]
https://arxiv.org/abs/2209.07919



[LG] Adversarially Robust Learning: A Generic Minimax Optimal Learner and Characterization
对抗性鲁棒学习:通用极小极大最优学习器和表征
O Montasser, S Hanneke, N Srebro
[Toyota Technological Institute at Chicago & Purdue University] https://arxiv.org/abs/2209.07369

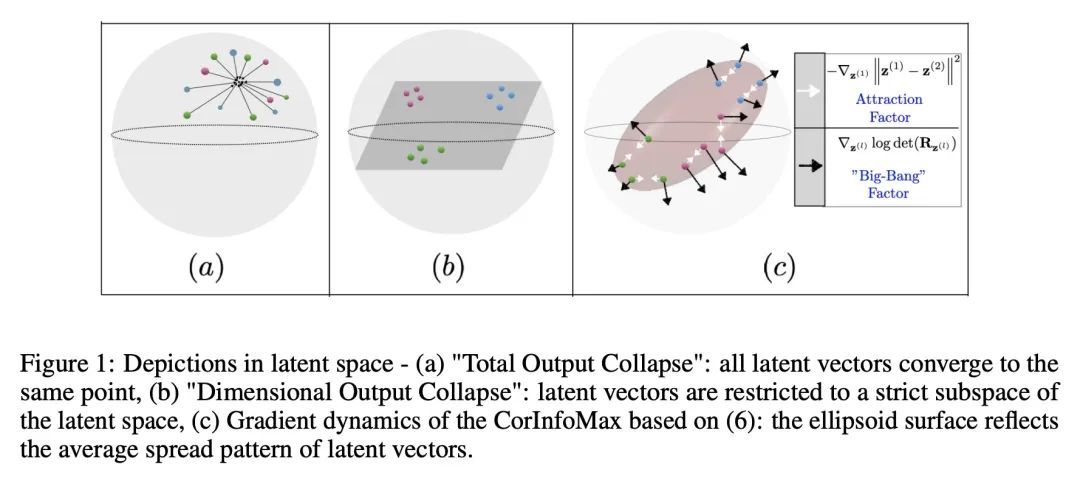
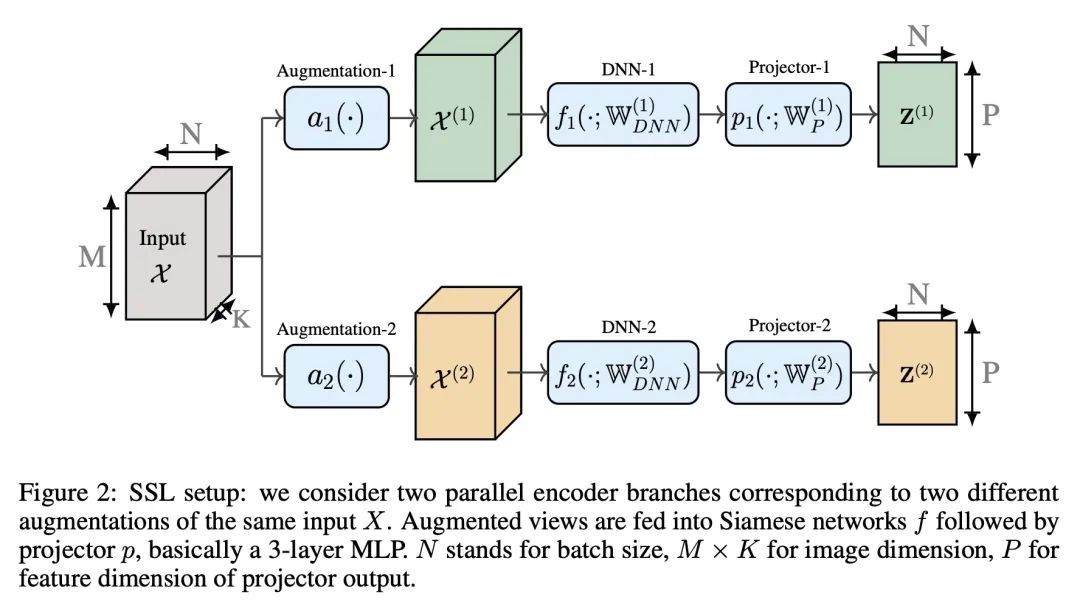
[LG] Self-Supervised Learning with an Information Maximization Criterion
基于信息最大化准则的自监督学习
S Ozsoy, S Hamdan, S Ö. Arik, D Yuret, A T. Erdogan
[Koc University & Google Cloud AI Research] https://arxiv.org/abs/2209.07999


内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢