
【论文标题】Dynamic Context-guided Capsule Network for Multimodal Machine Translation
【多模态+机器翻译】面向多模态机器翻译的动态上下文信息引导胶囊网络
【作者团队】Huan Lin, Fandong Meng, Jinsong Su, Yongjing Yin, Zhengyuan Yang, Yubin Ge, Jie Zhou, Jiebo Luo(厦门大学&腾讯微信AI&罗切斯特大学)
【发表时间】2020/9/4
【论文链接】https://arxiv.org/pdf/2009.02016.pdf
【代码链接】https://github.com/DeepLearnXMU/MM-DCCN
【推荐理由】如何在翻译过程中有效地利用视觉特征是当前多模态机器翻译一大关键问题,本文提出了基于动态上下文信息引导的胶囊网络(Dynamic Context-guided Capsule Network(DCCN)),首次利用胶囊网络将两种不同粒度(全局视觉信息和区域视觉信息)的视觉特征与文本进行交互,该结构能够在翻译过程中动态地提取多粒度图像特征,从而生成更为丰富的多模态表示,从而提高多模态机器翻译的性能。
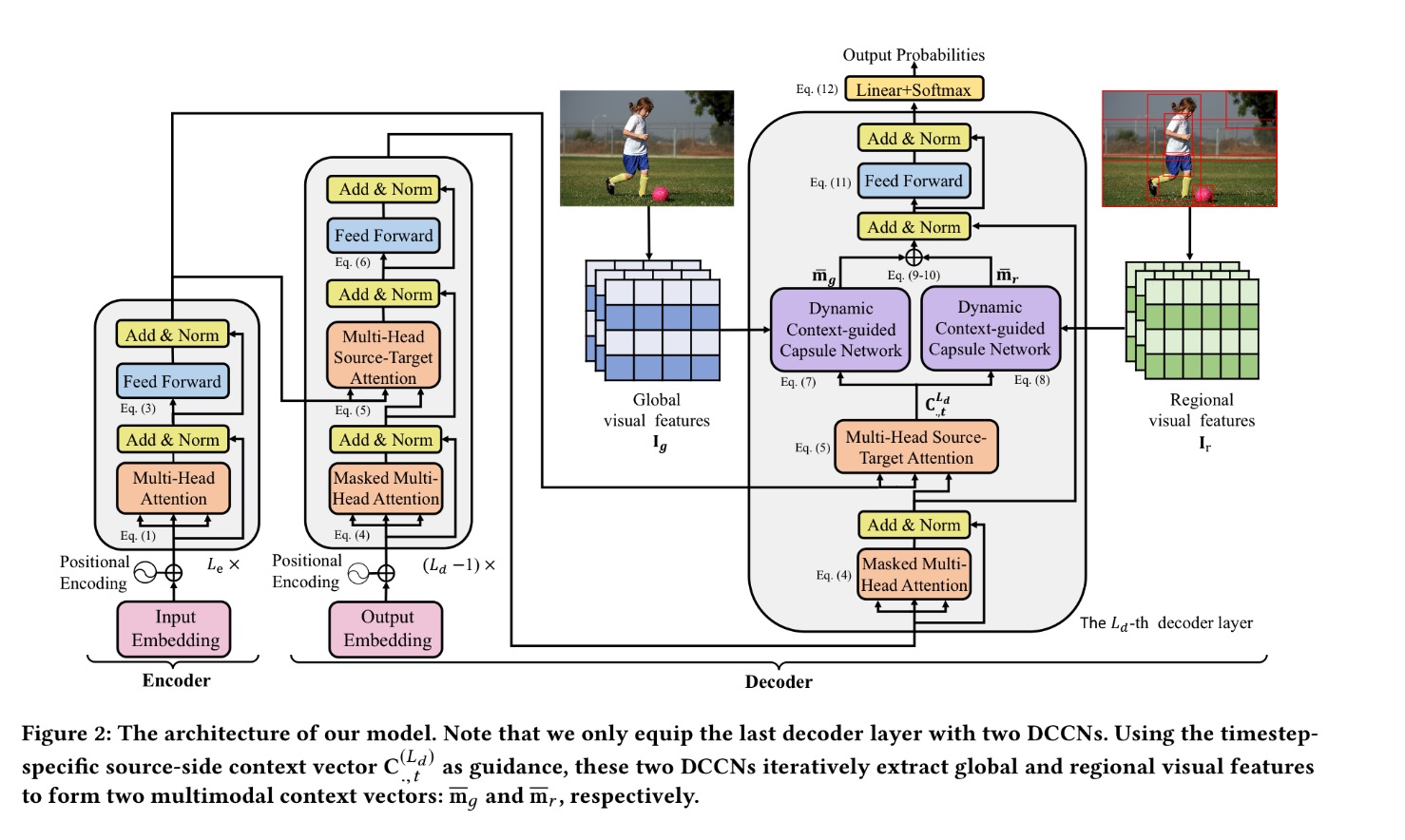
本文提出的基于动态上下文信息引导的胶囊网络,是在传统transformer架构基础上,对解码器部分进行创新(如图)。具体而言:
1.在解码的每个时间步,DCCN首先使用传统的源端注意力机制来生成特定于时间步的源端上下文信息向量。
2.接着,DCCN将源端上下文信息向量作为输入,并且通过基于上下文信息引导动态路由机制的胶囊网络来指导相关视觉特征的迭代提取。特别地,作者引入了两个并行的DCCN从全局和区域两个不同粒度视觉特征对多模态上下文信息向量进行建模。
3.最后,作者将获得的两个多模态上下文信息向量进行融合并合并到解码器中用以预测目标生成词。
 本文的主要贡献点在于:
1.本文首次在多模态机器翻译中使用胶囊网络提取视觉特征,从而能够无需更多参数即可有效的捕获视觉特征。
2.本文创新地提出了一个基于上下文信息引导动态路由机制的胶囊网络,用特定于时间步的源端上下文信息向量作为引导动态生成多模态上下文信息向量。
3.本文方法在Multi30K的英语-德语和英语-法语的两个翻译数据集上取得了优越的性能。
本文的主要贡献点在于:
1.本文首次在多模态机器翻译中使用胶囊网络提取视觉特征,从而能够无需更多参数即可有效的捕获视觉特征。
2.本文创新地提出了一个基于上下文信息引导动态路由机制的胶囊网络,用特定于时间步的源端上下文信息向量作为引导动态生成多模态上下文信息向量。
3.本文方法在Multi30K的英语-德语和英语-法语的两个翻译数据集上取得了优越的性能。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢