

论文暂未公布,可关注开源地址
研究动机
面向目标的多模态情感分类(TMSC)是方面级情感分析的一个新的子任务,旨在预测一对句子和图片中提到的意见目标的情感极性。该任务背后的假设是图片信息可以帮助文本内容识别意见目标的情感。图1给出了两个代表性的示例。我们可以看到仅仅根据非正式的简短句子很难检测出意见目标的情感,但与意见目标相关的视觉内容(即笑脸)可以清晰地反映其情感极性。
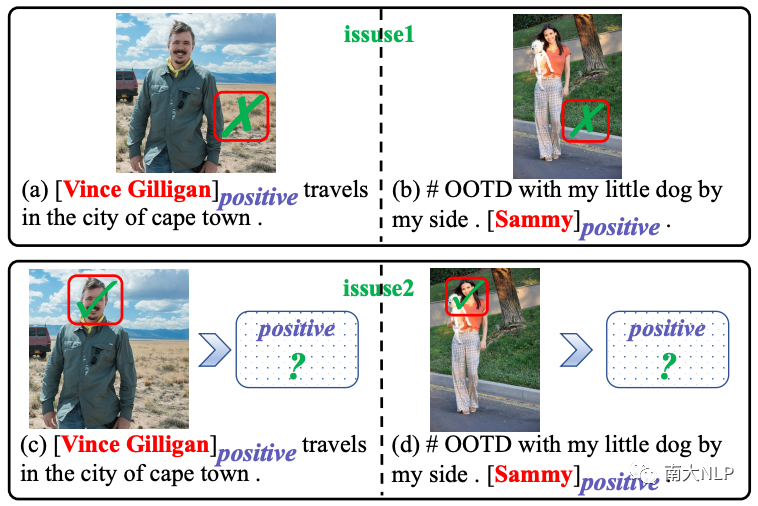
图1:面向目标的多模态情感分类 (TMSC) 的两个示例。意见目标及其相应的情感极性在句子中突出显示。红色边框表示意见目标关注到的视觉线索。
从上面的示例中我们可以看出,对齐两种模态的意见目标并捕获有用的视觉情感特征在TMSC任务中起着至关重要的作用。鉴于其重要性,主流的工作[1,2,3,4,5,6]采用了注意力机制来自动学习文本和图片的对齐关系,然后将捕获的意见目标的视觉表示聚合为证据来进行情感预测。
尽管取得了一些改进,但上述方法仍然存在两个关键问题:(1)由于文本和图片中意见目标的粒度存在很大的差距,之前的这些方法很难对齐两种模态。具体来说,图片中出现的意见目标通常是指粗粒度的对象(例如,图片中的man),而句子中的意见目标通常是细粒度的实体(例如,人名 “Vince Gilligan)。意见目标粒度的不一致导致视觉注意力有时无法捕捉到相应的视觉表征。(2)即使捕获到了,表达相同情绪的多样化视觉表示也给情感预测带来了很大的挑战。以图1(c)和图1(d)为例,意见目标“Vince Gilligan”和“Sammy”分别关注了图片中的粗粒度对象man和girl,从他们的面部表情我们可以看出他们都在微笑,但微笑的角度和幅度却大不相同。视觉表示的多样性不可避免地导致其稀疏性,这使得学习视觉表示和情感标签之间的映射函数变得困难。
在这项工作中,我们提供了解决上述问题的新思路,即利用从图片中提取的形容词-名词对 (ANPs) . (例如图2(a)中的“nice clouds”, “bad car”, “happy man”, “clear sky” 和“dry grass”)。对于第一个问题,我们观察到 ANPs 中的名词也是粗粒度的概念,因此一个很直观的想法是将细粒度的意见目标(例如“Vince Gilligan”)映射到粗粒度名词中(例如“man”)。通过这种方式更容易弥合两种模态的粒度差距并对齐文本和图片。对于第二个问题,我们观察到 ANPs 通常可以从表达相同情绪的不同视觉内容中提取到相同的形容词,因此一个很直观的想法是将多样化的视觉表征(例如笑脸)映射到同一个形容词(例如“happy”)。显然,学习这些相同形容词和情感标签之间的映射函数更容易。
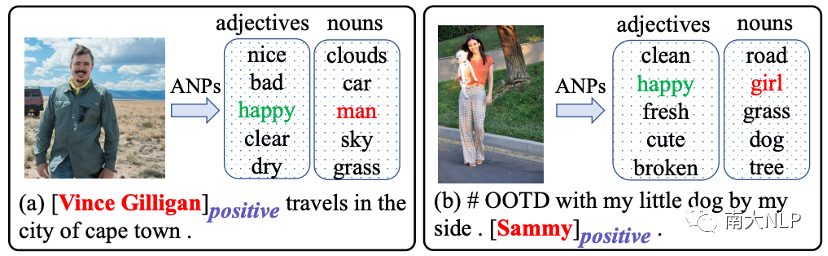
图2:从每个图片中提取前 5 个形容词-名词对 (ANPs)
为了使用 ANPs 促进 TMSC 任务,我们提出了一个知识增强框架(简称KEF), 它主要包含两个组件:视觉注意力增强器和情感预测增强器。前者首先使用我们设计的映射方法从 ANPs 中找到与意见目标最相关的名词,然后用它来提高视觉注意力的有效性。后者的目的是建立形容词和目标相关视觉表示之间的联系,然后将其用作视觉表示的补充信息,以降低预测情感标签的难度。
内容中包含的图片若涉及版权问题,请及时与我们联系删除

评论
沙发等你来抢